Cumulative totals three different ways in data science
The data analysis field has moved away from querying tools like Crystal Reports (shudder), OLAP cubes, and Excel, to programming languages closer to the raw data.
I primarily work with IPython notebooks, R, and SQL these days, and I thought it would be interesting to look at the differences between these three tools and three ways of thinking through a single task.
Something people often ask of data scientists (or analysts or engineers or what have you) is to just find out how many total customers the company has from the very beginning on a cumulative basis. Often product heads like to see this to figure out if their sexy new product is showing that legendary hockey stick growth.
Often times, this data is only available at a granular level (i.e. you have a base number and the adds every month.) For example, let’s say we want to find out how many total employees each of these Silicon Valley Companies have in any given month. Are they growing as quickly as Hooli?
Here’s the CSV file you’re given to work with: (also available in the associated GitHub repo for all the code in this post.)
Company Month New Employees
Hooli 14-Jan 123,456
Hooli 14-Feb 1,434
Hooli 14-Mar 2,455
Pied Piper 14-Jan 1
Pied Piper 14-Feb 2
Pied Piper 14-Mar 2
Raviga 14-Jan 50
Raviga 14-Feb -2
Raviga 14-Mar 17
But what we really want is this:
Company Month New Employees
Hooli 14-Jan 123,456
Hooli 14-Feb 124,890
Hooli 14-Mar 127,345
Pied Piper 14-Jan 1
Pied Piper 14-Feb 3
Pied Piper 14-Mar 5
Raviga 14-Jan 50
Raviga 14-Feb 48
Raviga 14-Mar 65
What I often want to do is create a cumulative total, by month and by company. In Excel, this is super-easy. Just add a new column and add the previous row’s values to it. I’ve shown the formula view:
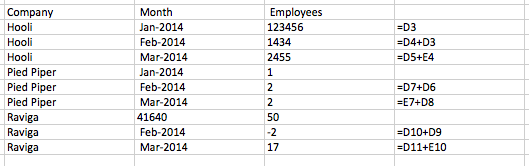
But, it’s extremely annoying when there’s any more than 100 rows of data, because then I’m resorting to cut and paste and manually tweaking. As soon as I start to do things manually, I make mistakes, and it’s not very good data practice to have code you can’t reproduce.
Doing this kind of thing in more data science-y environments is great because then you have reproducible code you can run over and over again. However, it does take a bit more legwork and requires thinking about the problem in a little bit of a different way than just summing cells.
So here are three typical ways to do cumulative totals in three pretty typical data science environments.
###Cumulative totals in Python
Python, like most programming languages, performs operations over rows of data sequentially, stopping when it hits a new column. (for example, it doesn’t see data as a matrix, but more as individual values. )
This is a “problem” for data people with all languages: Software developers often see data as means to an end (compiling the program). This means data doesn’t need to be organized exactly, just well enough to move through different pipes. Whereas for data people, data is the end goal. (If you’re interested in more about this, I gave a presentation a year or so ago with graphics illustrating the topic here.)
This “problem” (which is really just a feature of programming) is easy to solve with Pandas, which transforms data once again into matrices that need to be operated on in their entirerty. These matrices are called data frames. But it’s a little unwieldy when performing operations on operations on matrices, so you have to do a cumulative sum of a cumulative sum:
###Import Pandas for working with data
import pandas as pd
from pandas import DataFrame
import dateutil.parser as parser
###Read in CSV file
df=pd.read_csv('sv.csv')
print df
Company Month New Employess
0 Hooli 14-Jan 123456
1 Hooli 14-Feb 1434
2 Hooli 14-Mar 2455
3 Pied Piper 14-Jan 1
4 Pied Piper 14-Feb 2
5 Pied Piper 14-Mar 2
6 Raviga 14-Jan 50
7 Raviga 14-Feb -2
8 Raviga 14-Mar 17
###Make sure date and number values are rendered correctly from CSV file (the dateutil library) and check each column’s datatype
print df.dtypes
Company object
Month datetime64[ns]
New Employess float64
dtype: object
###Finally, roll up the cumulative total with two group-bys:
print df.groupby(by=['Company','Month']).sum().groupby(level=[0]).cumsum()
New Employess
Company Month
Hooli 2015-01-14 123456
2015-02-14 124890
2015-03-14 127345
Pied Piper 2015-01-14 1
2015-02-14 3
2015-03-14 5
Raviga 2015-01-14 50
2015-02-14 48
2015-03-14 65
##Cumulative Totals in R
R, in theory, operates on matrices. But mostly, R “thinks about data sets” in columns as opposed to across both rows and columns. In order for it to understand matrices the same way databases do, you need to get the data.table package. (Check out this link for more details.) It’s a little more straightforward than Python because it handles CSV formatting a little better and you don’t need to do as much pre-processing. Like Python, the data.table package has cumulative sum as a built-in function, but there are two steps to organizing the data correctly to be sorted instead of one.
Install the package, read in the csv file, set it as the data table, and set the two keys as the columns you want to group by, then run the cumulative sum function.
install.packages("data.table")
sv <- read.csv("~/Desktop/ipythondata/sv.csv") #read in data
require(data.table) #package for transforming to data table
View(sv)
setDT (sv) #set the table as your dataset
setkey(sv, Company,Month)
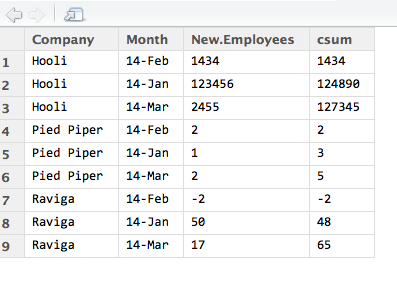
sv[,csum := cumsum(New.Employees),by=c('Company')]
View(sv) #view your results
And you get:
##Cumulative Totals in SQL
This one is a little trickier because instead of running RStudio or IPython notebooks locally, you have to start a database instance…somewhere. You can, in theory, set up SQLite or MySQL locally, but it’s probably more of a pain than it’s worth. I have a Digital Ocean droplet that has Postgres installed exactly for this kind of tomfoolery. There is a bunch of admin work that will have to be done before you can create tables in Postgres, but then you’re on your way on the command line:
postgres@data:~$ psql
postgres=# CREATE SCHEMA employees;
CREATE SCHEMA
postgres=# CREATE TABLE cumtot(company CHAR(50) NOT NULL,
month DATE NOT NULL,nemp NUMERIC NOT NULL);
CREATE TABLE
Then take a look at the table that you’ve created:
postgres=# \d
List of relations
Schema | Name | Type | Owner
——–+——–+——-+———-
public | cumtot | table | postgres
Then, let’s copy the csv file into the table, instead of creating each row one by one:
postgres=# copy cumtot FROM '/data/sv.csv' DELIMITER ',' CSV HEADER;
In the file, we first have to change the date format because Postgres only takes certain formats http://www.postgresql.org/docs/9.1/static/datatype-datetime.html
So what we’re importing is:
Company,Month,NewEmployees
Hooli,2014-Jan-01,123456
Hooli,2014-Feb-01,1434
Hooli,2014-Mar-01,2455
Pied Piper,2014-Jan-01,1
Pied Piper,2014-Feb-01,2
Pied Piper,2014-Mar-01,2
Raviga,2014-Jan-01,50
Raviga,2014-Feb-01,-2
Raviga,2014-Mar-01,17
Check out the table created with the \d command:
postgres=# \d cumtot
Table "public.cumtot"
Column | Type | Modifiers
---------+---------------+-----------
company | character(50) | not null
month | date | not null
nemp | numeric | not null
And now view the contents of the table: (don’t forget the semi-colon…Postgres is pretty picky with syntax):
postgres=# select * from cumtot;
company | month | nemp
--------------------------------------
Hooli | 2014-01-01 | 123456
Hooli | 2014-02-01 | 1434
Hooli | 2014-03-01 | 2455
Pied Piper | 2014-01-01 | 1
Pied Piper | 2014-02-01 | 2
Pied Piper | 2014-03-01 | 2
Raviga | 2014-01-01 | 50
Raviga | 2014-02-01 | 48
Raviga | 2014-03-01 | 65
That was just the pre-work gruntwork. Now we get to actually do the cumulative total, which requires a window function. Window functions in SQL seem complicated but they’re pretty easy once you get the hang of them. They say, “don’t look at this entire table, look at a portion of the table in a specific order.”
postgres=# SELECT company, month, nemp, sum(nemp)
OVER (PARTITION BY company ORDER BY month) as cum_tot
FROM cumtot ORDER BY company, month;
company | month | nemp | cum_tot
Hooli | 2014-01-01 | 123456 | 123456
Hooli | 2014-02-01 | 1434 | 124890
Hooli | 2014-03-01 | 2455 | 127345
Pied Piper | 2014-01-01 | 1 | 1
Pied Piper | 2014-02-01 | 2 | 3
Pied Piper | 2014-03-01 | 2 | 5
Raviga | 2014-01-01 | 50 | 50
Raviga | 2014-02-01 | -2 | 48
Raviga | 2014-03-01 | 17 | 65
And then you’re done.
So that’s pretty much it. Three different approaches to cumulative totals, that will each give you the right answer.
I worked with a tiny dataset that is lightning-fast in memory and very easy to transfer from place to place. The larger your dataset grows, the less you will want to move it. In this case, if you already have the data set up in a SQL database, keep it there and run your window function. It will take MUCH less time than exporting it out as a csv and importing it into either IPython or R. At the size of the data included in this post, it pretty much doesn’t matter which one you use (although creating and importing into a database will take longer.)
###When to use what:
- Use IPython if you need to do further cleaning to the data after you cumulatively total it, and want to retrace your steps back to the original data.
- Use R if you need to do simple statistics or regression or charting on the data as-is, and if the data is small.
- Use SQL if your data’s already in SQL and you need to create more groups from it.