How large should your sample size be?

I read a recent interview with Hadley Wickham. Two things stood out to me.
The first is how down-to-earth he seems, even given how well-known he is in the data science community.
The second was this quote:
Big data problems [are] actually small data problems, once you have the right subset/sample/summary. Inventing numbers on the spot, I’d say 90% of big data problems fall into this category.
##The technical side of sampling
Even if you don’t have huge data sets (defined for me personally as anything over 10GB or 5 million rows, whichever comes first), you usually run into issues where even a fast computer will process too slowly in memory (especially if you’re using R). It will go even slower if you’re processing data remotely, as is usually the case with pulling down data from relational databases (I’m not considering Hadoop or other NoSQL solutions in this post, since they’re a different animal entirely.)
In the cases where pulling down data takes longer than running regressions on it, you’ll need to sample.
But how big a sample is big enough? As I’ve been working through a couple of rounds of sampling lately, I’ve found that there’s no standard rule of thumb, either in the data science community or in specific industries like healthcare and finance. The answer is, as always, “It depends.”.
Before the rise of computer-generated data collection, statisticians used to have to work up to a large-enough sample. The question was, “I have to collect a lot of data. The process of collecting data, usually through paper surveys, will take a long time and be extremely expensive. How much data is enough to be accurate?”
Today, the question is the opposite: “How much of this massive amount of data that we’ve collected can we throw out and still be accurate?”
That was the question I was trying to answer a couple weeks ago when I was working with a SQL table that had grown to 1+ billion rows.
The business side of sampling
To understand the relationship between an entire population and a subset, let’s take a step back to see why someone might ask.
Let’s say you’re the data scientist at a start-up - Goatly - that sells artisanal handcrafted medicine boxes monthly to owners of narcoleptic goats (this is a real thing and I could watch this video over and over again.
Goatly has ~ 100,000 farms already in your system (who knew America had a narcoleptic goat problem?) and the CEO wants to buy a share in a private jet, so she needs the company to keep growing very quickly. A startling number of goats get much better after taking your medicine and hence, the farm leaves your service. The CEO needs you to figure out what makes these goats better and see if you can predict how many farms will be the next to leave, and as a result, how much business she needs to replace them.
You think you might be able to use logistic regression to predict whether the farm will cancel Goatly (number of goats, size of goats, color of goats, how much of the pills they buy in a month, how many pills they use in a month, ratio of narcoleptic to regular goats, etc.) But when you try to run the regression on the entire data set, it fails because it’s simply too much.
So you need to sample. How many farms do you need to pick to make sure that they accurately represent the total population of farms? There are some smaller farms, some larger farms, some farms with more narcoleptic goats, some farms where the farmers are more aggressive in giving the goats the medicine, etc. If you pick the wrong sample, it won’t be the same as the population, and then all the tests you plan to do later will fail.
Determining sample size
Here’s the standard equation used to calculate error. It’s often the precursor to testing the power of a test (that is, if this equation works in your favor, then you can use power of a test to figure out whether logistic regression or most other tests you use actually work on your sample). More on that at the bottom of the post.
You need to know:
- Population size - The entire population you’re sampling (in our case, 100,000.)
- Margin of error/confidence interval - How far away are you willing to be from the population statistic?
- Confidence level - How confident do you want to be that your sample statistic (the mean, for example) matches your population?
The two things you have to pass judgment on are:
how large you want your confidence level to be: i.e. do you want to be 90% sure that you found all the farms that will cancel Goatly and leave your CEO traveling coach with the peons? 95% or 99%? In settings where you’re dealing with medical data, you want this to be 99%. Elsewhere, 95%, or even 90%, depending on what you’re doing is good enough. I asked around the Data Science Slack and the general consensus was most business settings can do with 95%, again, depending on context.
margin of error By what percent the sample deviates from the population. This is the number you usually see in polls: 43% of people voted Yes on this issue, +/- 3%. Again, you’ll need to use your judgment. There is no standard of error. It’s usually anything between 1 to 4%. Let’s pick 2% for now. Just keep in mind that sample size and margin of error are related: the larger margin of error you pick, the smaller sample size you’ll need.
##Putting it all together:
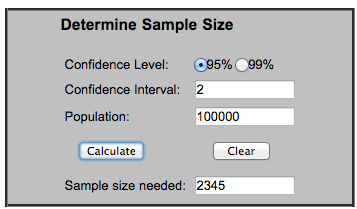
Interpreting the results of the four stats you need for the entire equation: If we have a population size of 100,000, what number of farms can we sample and be sure that they are representative of all of the farms using Goatly 95% of the time, where our sample statistic is at most 2% below or 2% above the population mean?
Calculating sample size with Python
There are a couple ways to run a quick calculation. The fastest is probably this site. I use it a lot for quick back of the envelope calculations. Normally I would be wary of using a site whose code and methods I didn’t know, but this site is generally well-documented, and we’ll be cross-checking this value against another method.
Putting in our numbers there, we get:
2,345 as the sample size.
There is also a really nice Python script that does the same thing.
Adjusted for my sample size and confidence interval (see my Github):
def main():
sample_sz = 0
population_sz = 100000
confidence_level = 95.0
confidence_interval = 2.0
It also returns the same number:
vicki$ python samplesize.py
SAMPLE SIZE: 2345
There are a couple of ways to get close to it in R, but I haven’t found anything in the pwr library so far that only requires those three things: margin of error, confidence level, and population. I also haven’t found anything in either SciPy or NumPy that does exactly this, although if I do, I’ll be sure to change the post.
Wrapping up
If you want to select a sample of farms that are representative of the whole Goatly population, you’d need to pick about 2.5k, which is much more manageable than looking at 100,000, and will allow you to get your CEO the results much more quickly. You’re happy, she’s happy, and the narcoleptic goats (the ones that are getting treated, anyway), are also happy.
##Post-script on the Power of a Test
Something you might often come across while reading up on picking the right sample size is “power of test.” (This can be performed once)[https://en.wikipedia.org/wiki/Statistical_power] you actually have your sample size. The power for a test gives you an acceptable Type I error. A Type I error is a false positive, or saying that a farm will leave the Goatly platform when they really won’t. What you’re really testing for is whether the sample size you’re taking matches the population.
Thanks to Sandy and @perfectalgo for editing.