My recent experiences using Azure ML

I never thought I’d write “Microsoft” and “exciting” in the same sentence.
I started my data career using Excel, which is a great tool for prototyping and sharing data quickly, and has been used by many people as a gateway to learning programming through VBA, but has none of the features someone serious about working with data could get behind: version control, testing, code review,cross-platform compatibility, or more than 1 million rows.
Oh, also it crashes all the time. and has so many irritating bugs that it is sometimes almost unusable.
Then there all of the wrong Microsoft has made on the developer side, from making C# proprietary, to forcing IE 6 compatibility, to the awfulness that is the Windows command prompt. Needless to say, as soon as I learned enough to know better, I switched to Mac and never looked back. Here are several examples of basic development/data science tasks that take less than half an hour on Mac in total, and take more than half a day in Windows.
- Installing a Hadoop Cloudera Quickstart VM (requires simply installing VirtualBox on Mac, requires changes to the registry on Windows)
- Using Python on Windows (a recent Django class I went to made everyone on Windows install VM to run Python to avoid the annoyingness of this, simply to have them waste time trying to set up virtual environments)
- Trying to do any type Unix command-line processing
- Running Jupyter notebooks
- Getting Git running
- Cygwin quirks (aka the inability to use Brew. There is always scoop, but it’s not the same)
- Getting Anaconda set up correctly
As of 2015, my opinion was strictly that I could not program on a Windows machine because the experience completely impedes my data science work flow.
But with Satya Nadella really coming into his own at Microsoft, the company has been making some moves to get back on track, the best of which has been bash on Windows. It’s also made Visual Studio available for Mac. They’ve even done several Reddit AMAs.
Right as my opinion of Microsoft was coming to a point somewhere between “horror” and “I could potentially be productive in this environment”, I was tasked with building out a proof-of-concept project in Azure ML (AML). The goal was to see how the platform would handle processing ~1GB of dumped csv data and running it through an algorithm of my choice. The idea was become more familiar with the platform and its capabilities in general, as well as test performance on medium-ish sized data.
What’s Azure ML?
AML launched over a year and a half ago. It purports to be a complete GUI data science/ETL/analysis platform in the cloud that is customizable and shareable and allows for API access. So, essentially a web app for data science.
Like most data scientists, I am leery of any platform that purports to be an end-to-end solution. There are a lot of analytics solutions that try to incorporate the entire data engineering and data science stack, but ultimately fall short, because there is a LOT of data work that can’t be automated:
- deciding how to clean the data,
- picking a sample size,
- deciding on the scope of the problem space,
- choosing an algorithm,
- and prototyping visualizations.
This tweet encapsulates that frustration pretty well:
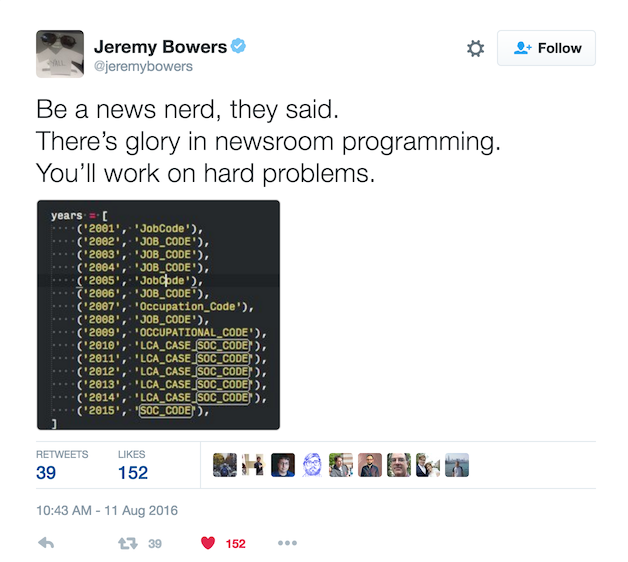
However, I’m open to trying anything as long as it gets the job done. And there is a lot to try today.
My criteria for evaluating AML included:
- Ablility to ingest both small and files from my laptop
- Ability to load from a number of external DBMSes and cloud services
- Ablility to add factors to data (ala Python and R) and to manipulate datasets in-place on the platform (change data types, delete nulls, change column labels, etc.)
- Access to data science staple algorithms: linear regression, multiple linear regression, logistic regression, decision trees, random forests, K-means, Naive Bayes, and maybe a few other bonus ones. It basically had to be able to do the work of scikit-learn.
- Outputs data as 1)an API (i.e. JSON), 2)csv and 3) visually and lets me manipulate the ways in which data is output.
- Analysis can be shared and used by others in the organization regardless of level of technical skill
And, one of the most important features for me with any software product:
- Easy to get started with and has a large community of practitioners that answer each other’s questions
My first course of action was to see how active the community around the product was by checking out blog posts and asking fellow practitioners. If you read DataTau or HackerNews, every other post is about R or Python or Tensorflow or AWS, which tells me several things:
- They’re languages and platforms the community uses frequently and will be available in almost any data science environment
- They’re in active development and have a lot of active developers and
- There will be a lot of Stack Overflow answers if I get stuck.
Unfortunately, I only found one or two posts. The StackOverflow pickings were slim.
None of the data scientists I talked to, both in person and in data science specific Slacks, had ever used this product. And finally, discouragingly, there was this review.
So a few weeks ago I got a call from a Microsoft customer success rep calling in to see why I was letting my trial lapse. I was honest and said “Look, I’ve used the product twice, invested 3-4 hours, looked at the examples, and honestly I feel like there isn’t anything you offer that I can’t do myself with code. The models I build are faster to implement and the ones I have tested have higher out of sample accuracy”. Her response? Her response was “Oh yeah, we get that a lot.”.
This was one of my first thoughts as well: Why would I pay for this product, when I can just roll my own Python or R code in much less time, and spend time learning the platform, getting set up with private keys and the overhead admin necessary for a secure cloud product, and the rolling Azure accessibility costs.
But I was keeping an open mind for the evaluation. If this product is faster than R and Python and, even more importantly, others in the organization could view the analysis via dashboards, it would be great.
Getting started with Azure ML
One of the cool things AML does it allow you to take an 8-hour free trial before creating a log-in. After that, it’s a mess of signing up for Microsoft IDs. This is a breeze if you already have a Microsoft or organizational account, very annoying if you don’t.
After I’d logged in and played around with it for a couple hours, I had to admit the product was really impressive, to the point of asking, “Why don’t more people talk about how awesome this is?”
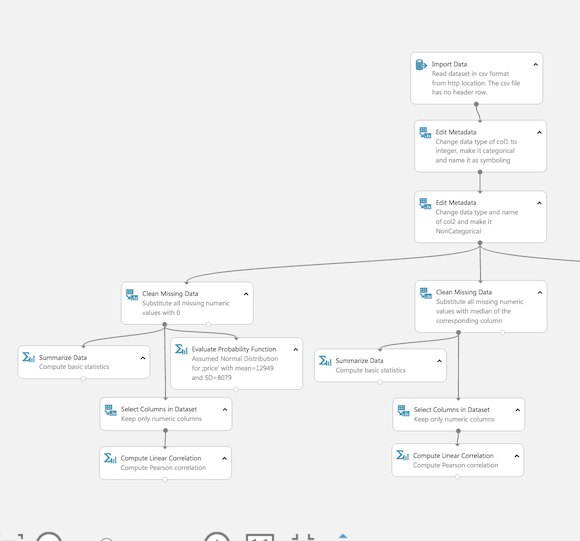
Once you log in, the product takes you through how to drag concepts and ideas onto the screen in order to build a model, which is very handy for people just getting started with machine learning. In terms of products, it’s very similar to KNIME for machine learning, or Pentaho for ETL, with structured workflow steps you can chain together and specify parameters on. Bottom line: This is a REALLY great tool for prototyping out data flows without having to write too much of your own code.
AML is structured around experiments, which are GUI workspaces that consist of imported data, algorithm steps, notebook analysis, and annotation, and, can be shared with others with a Microsoft log-in, with different levels of permissioning.
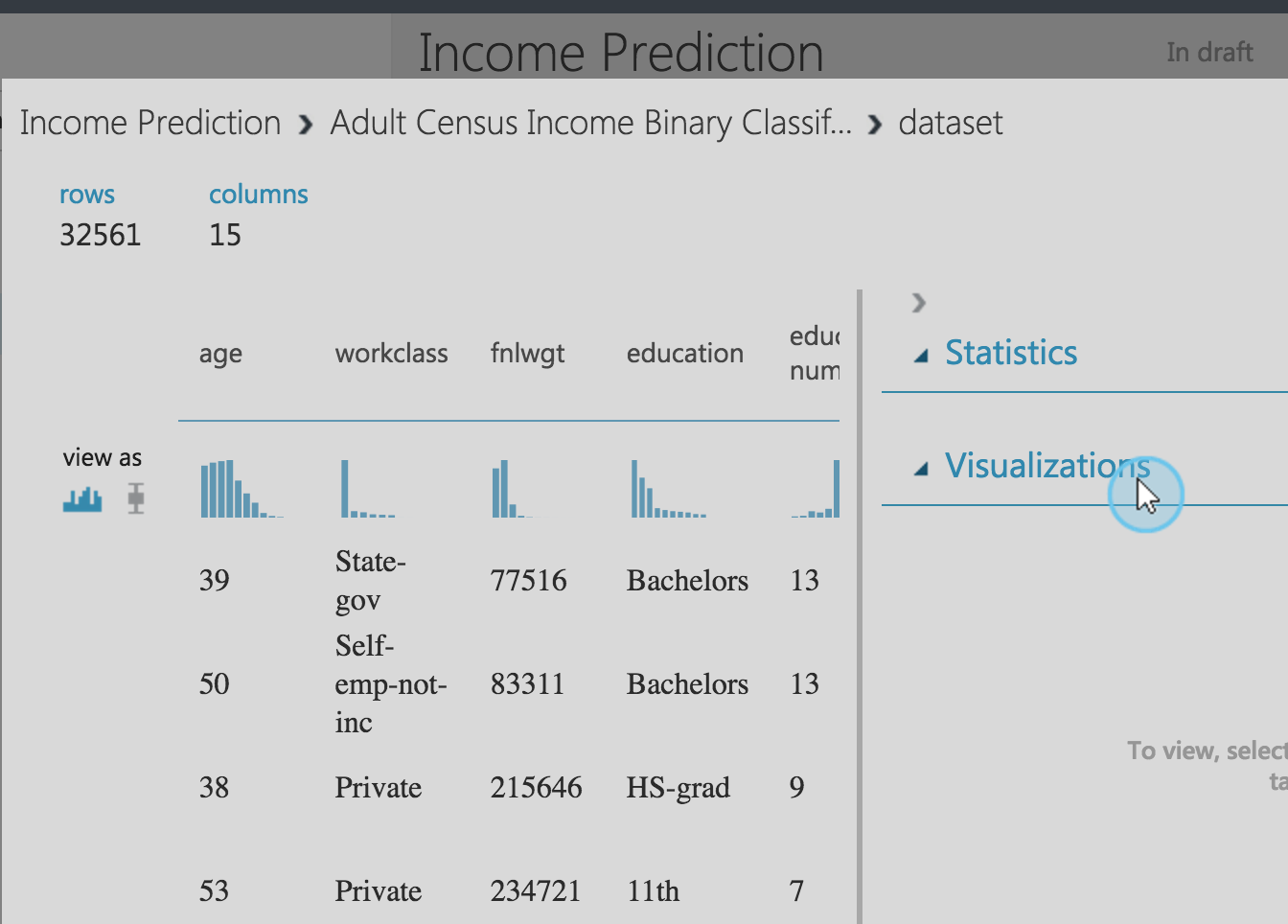
There are a number of different algorithms and data sources, and you can launch either R or Python (2 or 3) Jupyter notebooks to quickly visualize/incorporate data at each step, although it is harder incorporating that analysis or sharing it with other people unless you activate workspace sharing correctly.
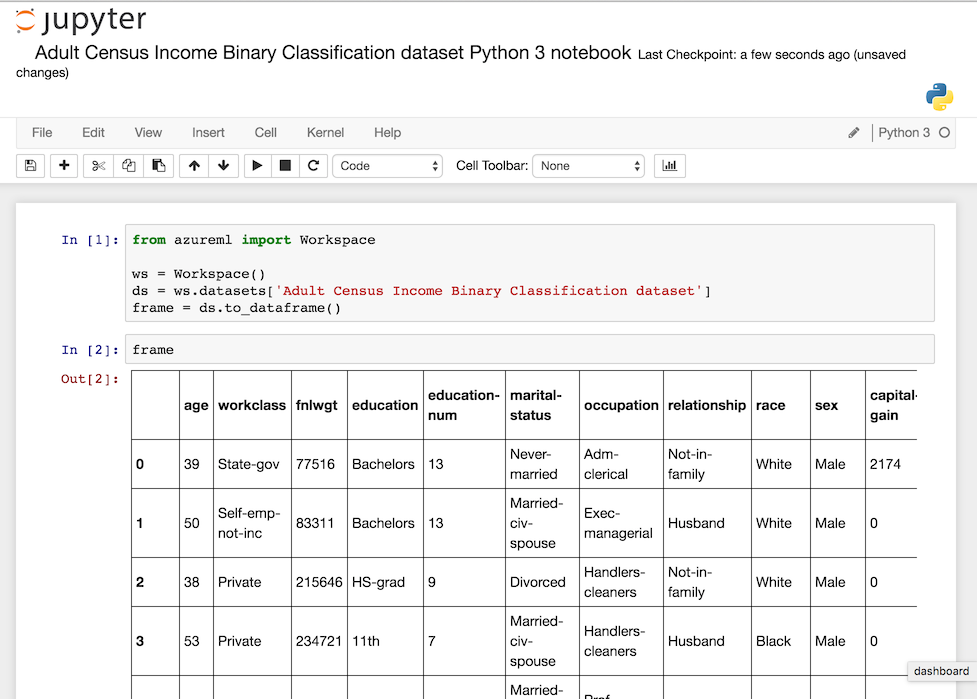
The Cortana Intelligence Gallery also has a bunch of “experiments”, or what I would call data products that you can import and use as templates for your projects. This is probably the best feature of the platform, the fact that you can build on others’ pre-existing work and figure out the best way to structure your machine learning.
At first glance, it’s pretty impressive, even if overwhelming to navigate: the Cortana Gallery is related to AML but located in a completely different location separate from the main product, and which takes a bit of time to find. There are also way too many options of what you can do. But in general, it seems extremely usable. I begrudgingly admitted that Microsoft was doing something with user experience in mind, something that had really cool potential.
Using Azure ML with your own data
After browsing around, I was ready to put my own data to work. Here’s where the going got hard. I had about ~2GB of csv file data that was not entirely clean (i.e. needed another response variable coded, needed some punctuation fixed, and needed some number formatting), so I wanted to import it, clean it, and run it through a simple random forest generator.
Trying to upload 2 GB of csv took forever and froze the app. I think part of this was related to sanitizing data inputs, but AzureML didn’t generate any error messages beyond the fact that the data didn’t load. Already this was a show-stopper. If I couldn’t move 2GB, how could I move 10 or 15 if I needed to later? In the AWS universe, larger files can be mounted as EBS volumes that can then be shared across the AWS ecosystem depending on how you permission them. But in the Azure universe, I wasn’t sure what the equivalent was. People seem to be having similar issues with different formats, including zip.
Here’s where the conflict between Microsoft’s desire to be a cool, open-source company, and the fact that their MO for the last 20 years has been to be inherently hostile to other platforms really started to come into focus. The other options seemed to be to load the data into SQL Server on Azure, which I had to download a complete set of separate npm packages for, since Windows doesn’t play nice with Mac. The command line options detailed in much of the official Microsoft documentation didn’t work on my machine and I had to fiddle around for about 40 minutes to get it to work. I then tried to use a version of the bcp utility, which also didn’t work until I downloaded RazorSQL and ended up forcing it through JDBC connection strings. The data then uploaded, but SQL server, on Azure at least, is extremely finicky about datatypes, so I had to do some additional wrangling on my local machine to make sure the load didn’t error out.
You could, theoretically, use the Azure Table Service or a Hadoop cluster, but I didn’t test either of those out. By the time I’d gotten a sample of data up and running, I was already 8 hours into my trial and extremely frustrated. The UI of AML is an extremely beautiful mirage; it seems to work with the data they have pre-populated, but getting your data in yourself means either picking a small, error-free dataset (my final load ended up being something like 15k rows), or going through all the traditional ways of ETL data cleaning before getting it to work. The main issue, I think, is that Machine Learning Studio uses an internal data type called Data Table to pass data between modules, and this Data Type has very strict parameters on what it allows to pass in as data.
Once I had a sample of the data uploaded, it ran quickly (<2 min), generated some data profiling, and I was able to run a simple decision tree and random forest model with the ability to pick training/test size, evaluate the algorithm, and do some visualization afterwards. But trying to run the data with longer samples took an extremely long time, sometimes more than half an hour, without any status dashboards to see what was happening behind the scenes.
Once the data was loaded, everything seemed to work pretty well, but the frustrations I’d had at dealing with the Mac-hostile command line modules, the inability to peek into the Data Table to see how it was handling data type conversion, and no status messages really soured me on the product.
I looked around online to see if I was the only person having problems like this; maybe I just didn’t read the documentation carefully enough. But it looks like both latency and tracing errors are common concerns for the product.
Results
In general, ironically, I think AML is great if you’re not a data scientist, in the same way Excel is great if you’re not a developer. It allows you to get hands-on very quickly within an environment that’s geared towards guiding you in a way that makes sense to non-technical people. The templates of the possible algorithms are great to see all the steps that go into making what is usually a black box model, the visualization of the data inputs is great for high-level managers, and the whole thing can be saved and shared across teams. This makes it a really nice transparent advocacy tool for what data science can do for an organization. A big plus are the Python notebooks, which can be shared and used collaboratively with others without having to spin up your own server, like a Google Doc.
It is not good for actual data scientists, because the platform is extremely limiting. As someone who’s constantly writing and testing code, I want to be able to see what the algorithm is actually doing, make changes, and test those changes. If there is a data import error, I want to be able to test that specific line numerous times until it imports correctly. I want to be able to do all of this seamlessly, not by dragging and dropping things. I also want the code to be reproducible for the next person. In one of the environments I shared with my coworkers, I wrote “PLEASE DON’T CHANGE ANYTHING,” in all caps, because I wasn’t sure how them playing around with the code would change it. There is probably permissioning around different views and dashboards, but I’d prefer version control.
Another critical issue is that you need to run the entire model at once, a process that could potentially take an extremely long time if you have a lot of data you’re testing. The Microsoft team is supposedly working on this.
In addition, if I’m going to be running R or Python code, I’d prefer to do it on my own local environment that I already have set up with the libraries I’m used to, not on a shared sever where it’s a pain to figure out where the data is coming from and going into. Unless I have terabytes of data in Azure, I’m having a hard time figuring out a use case where I’d want to work on a Jupyter notebook in the cloud.
The bottom line is that this product, while representing the hope of the new Microsoft, can’t shake its old culture of catering to Windows users with different use cases than technical users first. So, as of summer 2016, I’m still hesitant that the new Microsoft has emerged.