So, you want to data science

The hype of data science has dominated the tech scene for the last five years, an eternity an industry when the average interest cycle for, say, a JavaScript framework is 3.7 days.
And yet, data science, (and data engineering), is still a really young field that is not easily parsed by recruiters, managers making department budgeting decisions, and even data science practitioners themselves.
Add into the mix the latest buzz around AI and deep learning, and there are a lot of misconceptions about what data science is and what data scientists do.
Inspired by machine learning myths post on Dev.to, I decided to write about some of the issues I’ve seen in the field over the past couple years.
- The data scientist is a Swiss Army knife.
A data scientist is some kind of otherwordly super-being that can write production-quality engineering code, produce PhD-level statistics analysis, display Pulitzer-winning visualizations, and understand the business logic underpinning it all, with equal aplomb.
It’s true that, in theory, data science is an interdisciplinary job where tech and business knowledge have to meet in order to process data, then make sense of it.
But the high expectations that have stemmed from the original data science Venn diagram have led companies and recruiters to believe that unless a candidate can write Java code AND do Bayesian methods AND create charts in D3, they’re no good.
More likely, data scientists’ skills are t-shaped, meaning they’re broadly exposed to a variety of skills and tools, but focused deeply on a few. Most fall somewhere in the spectrum between what’s known as A and B - analysis and building, and are either better at creating pipelines, or working with them and surfacing insights.
When someone asks what that means, I bring out this chart:
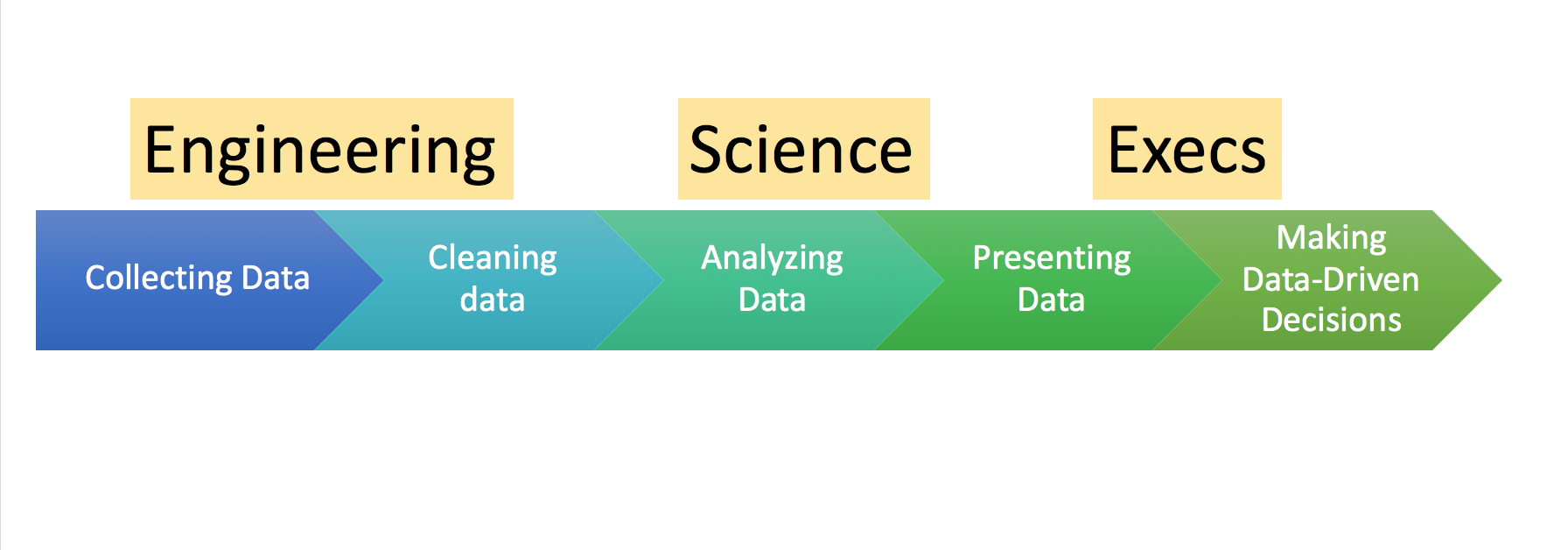
What kind of role you need will depend on what you need to do in a data pipeline. All of these roles are slightly different and require different levels of skill and expertise, depending on the kind of data you have and what kind of shape it’s in.
I, personally have not seen anyone good at everything in this diagram. Either you know stats really well, or you grok distributed systems, or you can present well to executives. Pick two. The people who know how to do all three are Jeff Dean, and you can’t afford him.
- A data scientist works alone
Along with the myth that one person knows everything, there is a myth that you only need one data scientist working in isolation, to do everything. In reality, since a data scientist specializes, as do most people, you need to have a solid team of people who complement each other’s skill sets to build a successful data product or analysis pipeline.
Ideally, you’ll have a data engineer, a data scientist, and a product owner/UX specialist (this role includes communicating with the business, documentation, and architecture), or some variation of those three roles in a number of people not to exceed five.
A data scientist also needs to be in touch with other parts of the business as much as possible, by sitting in on business meetings to understand where the questions directed to them are coming from. Organizations that see data scientists as an asset as opposed to sitting them in a corner and handing them one-off questions to answer like a report generation machine are organizations that do well.
- A good data scientist can only do analysis
It’s true that a single person can’t do absolutely everything in the data science toolchain. But, from the perspective of an individual practitioner, saying that you can only do statistical analysis is not as valuable as being able to carry that analysis through to other environments and to the final location for the data and the model.
It doesn’t mean that you need to be able to write production-quality code. But it does mean you need to understand the considerations your model will need to run under, and to be able to understand the constraints people further down in the data pipeline face.
- The data scientist as the genius:
Even though companies often don’t understand what they need from a data scientist, I often see many positions asking for a PhD in statistics or machine learning.
Unless you are doing ground-breaking research at SpaceX or CERN, you probably don’t need a PhD, because most of the problems in industry revolve around questions like these:
- We have customers, but we don’t understand them. How do we understand them better?
- How do we get more people to click on thing X or Y?
- How do we move our data to Hadoop? Should we move our data to Hadoop? How much
- How do we count the number of products we sell? How do we increase the number of products we sell?
- We have data in two different places. How do we get it into one place?
For example, here’s a typical ad I see these days (a composite of several I’ve seen lately):
Qualifications:
Masters or PhD in a quantitative/analytical discipline required (e.g. Computer Science, Statistics, Economics, Mathematics, Finance, Operations Research or similar field)
3+ years in a Data Scientist role
Highly skilled with Python, Java, and SQL.
Demonstrable experience in developing Machine Learning and Deep Learning algorithms
Proven track record of developing, maintaining, and deploying data services.
Experience with Hadoop stack (Hive, Pig, Hadoop Streaming) and MapReduce.
Experience with Spark.
Develop dashboards, reports, charts, graphs and tables displaying the outcomes of analyses for use by internal and external stakeholders.
Ability to work autonomously and take ownership of a project.
If you find a data scientist who fulfills the union of all of these circles, they’re either lying or you can’t afford them, because there is no way someone can have spent enough time to be an expert at everything listed. If they have a PhD, they probably haven’t spent as much time in industry and therefore can’t be highly-skilled at Python or Java. If they have a proven track record of deploying data services, they probably don’t have much machine learning experience. If they’re developing dashboards, they’re not doing deep learning and statistical analysis, they are essentially a report builder.
The real problem here is that the company doesn’t understand what they’re looking for, and therefore has lumped everything all together.
The reason you hire a data scientist, fundamentally, is to increase your company’s revenue in some way, by optimizing some data process you had no insight into before.
Unless you’re at a company whose revenue is dependent on cars driving themselves or on breakthroughs in medical research, you don’t need a deep learning specialist, or even deep learning itself.
There was a great podcast recently about how good data scientists come from all sorts of backgrounds, which don’t all entail writing papers about deep learning.
If you’re only looking for PhDs OR people who have had ten years in industry OR Java developers OR R experts OR ex-Googlers, you’ll miss the people working in all corners of industry and across academic disciplines who have worked with synthesizing analysis and know the pain of trying to make sense of data intimately, which is all data science is, at its core.
- You need a data scientist
This brings me to the question of whether you even need a data scientist at all. Remember, you’re hiring a data scientist because you want them to provide some value from your datasets by answering questions: should we build out product x? Will City Y be a competitive market for us? How many widgets do we make a day, and is that an efficient number? How happy are our customers?
If you can’t figure out whether you have enough data available to answer these questions, and whether the data is well-organized enough to do so, the data scientist won’t be able to, either.
Or rather, the data scientist will, but they’ll spend all their time doing janitorial data anthropology, which is extremely important work, but probably not why you hired a data scientist.
If that is the kind of work you need, make it clear up-front, or your hire, who was ready to solve business problems, will become extremely frustrated trying to figure out why they’re labeling training data for the fifth week in a row.
- You need a data scientist to work on deep learning with big data
This is probably the most pervasive myth of the hype cycle. Just as you don’t always need a software developer to work with Go and microservices on containers, you don’t need a machine learning engineer specializing in Julia who works on neural nets.
Remember what I wrote before - most data science problems are similar and simple, and both Ferraris and Civics can travel on the same highway, Civics sometimes more efficiently. I’ve also written before about big data problems, and why you should think long and hard about whether you need that Hadoop cluster.
- Data science is a growing field and there is a lot of opportunity.
Unfortunately, the same hype cycle that has driven up the demand for data scientists has also driven up the supply. If you’re just entering the field, it’s going to be harder for you to break through and get a job than it would have been in 2012.
That doesn’t mean you shouldn’t try, it just means you’re up against 50, 60, even upwards of 200 people for a junior-level position, which is something you want to keep in mind.
That there is a lot of opportunity in data - data analysis is not going to go away for companies. But it now comes in different forms, such, as, particularly, data engineering. The more engineering you know and understand how to do, the more valuable of an addition you are to any data team.
- Data scientists, engineers, and AI will make all our jobs obsolete.
There has been an endless barrage of articles in the media lately about how AI is going to take all of our jobs.
This is pretty at odds with how the data industry is today, because I and most of the data scientists I know spend an inordinate amount of time cleaning data. Even when the data is clean, it gives wrong answers, weird answers you didn’t expect, and results in things like TayBot.
This is just the nature of data: a byproduct of messy, human-generated processes that will take a long time to resolve and an even longer time to fully replace.
As an industry, we have a really long way to go to understand what our data means, how to analyze it, and even how we, as data practitioners fit into the meaning of what data science is these days. Rest assured that we need a long time to figure it out.