Building a Twitter art bot with Python, AWS, and socialist realism art
"Young Naturalists"
— SovietArtBot (@SovietArtBot) February 15, 2018
Sergiy Grigoriev, 1948 pic.twitter.com/8KdwFS6PjU
TLDR: I built a Twitter bot that tweets paintings from the WikiArt socialist realism category every 6 hours using Python and AWS Lambdas.
The post outlines why I decided to do that, architecture decisions I made, technical details on how the bot works, and my next steps for the bot.
Check out its website and code here.
Table of Contents
- Why build an art bot?
- Breaking a Project into Chunks
- Requirements and Design: High-Level Bot Architecture
- Development: Pulling Paintings from WikiArt
- Development: Processing Paintings and Metadata Locally
- Development: Using S3 and Lambdas
- Deployment: Bot Tweets!
- Where to Next?
- Conclusion
Why build an art bot?
Often when you’re starting out as a data scientist or developer, people will give you the well-intentioned advice of “just picking a project and doing it” as a way of learning the skills you need.
That advice can be hard and vague, particularly when you don’t have a lot of experience to draw from to figure out what’s even feasible given how much you know, and how that whole process should work.
By writing out my process in detail, I’m hoping it helps more people understand:
The steps of a software project from beginning to end.
The process of putting out a mininum viable project that’s “good enough” and iterating over your existing code to add features.
Picking a project that you’re going to enjoy working on.
The joy of socialist realism art.
Technical Goals
I’ve been doing more software development as part of my data science workflows lately, and I’ve found that:
- I really enjoy doing both the analytical and development pieces of a data science project.
- The more development skills a data scientist is familiar with, the more valuable they are because it ultimately means they can prototype production workflows, and push their models into production quicker than having to wait for a data engineer.
A goal I’ve had recently is being able to take a full software development project from end-to-end, focusing on understanding modern production best practices, particularly in the cloud.
Personal Goals
But, a project that’s just about “cloud architecture delivery” is really boring. In fact, I fell asleep just reading that last sentence. When I do a project, it has to have an interesting, concrete goal.
To that end, I’ve been extremely interested in Twitter as a development platform. I wrote recently that one of the most important ways we can fix the internet is to get off Twitter.
Easier said than done, because Twitter is still one of my favorite places on the internet. It’s where I get most of my news, where I find out about new blog posts, engage in discussions about data science, and a place where I’ve made a lot of friends that I’ve met in real life.
But, Twitter is extremely noisy, lately to the point of being toxic. There are systemic ways that Twitter can take care of this problem, but I decided to try to tackle this problem this on my own by starting #devart, a hashtag where people post classical works of art with their own tech-related captions to break up stressful content.
There’s something extremely catharctic about being able to state a problem in technology well enough to ascribe a visual metaphor to it, then sharing it with other people who also appreciate that visual metaphor and find it funny and relatable.
"Waiting for the build to finish"
— Vicki Boykis (@vboykis) December 28, 2017
Albert Anker, 1867 #devart pic.twitter.com/3tAO3idZq1
Debugging a memory leak. (Vincent van Gogh, 1890) #devart pic.twitter.com/A5eYvK1Zmq
— Miria Grunick (@MiriaGrunick) December 9, 2017
"Migration plan from MySQL to Mongo"
— Vicki Boykis (@vboykis) December 13, 2017
Alex Colville, 1954 #devart pic.twitter.com/ieCzv7Hfh8
"Another day, another AGILE Sprint"
— Trevor Grant (@rawkintrevo) December 19, 2017
~Peter Blume, circa 1944-8#devart pic.twitter.com/GaiueyZniS
"Machine learning engineers, data scientists, data analysts, research engineers, and statisticians hold forth on what each of their actual titles means in terms of responsibilities. "
— Vicki Boykis (@vboykis) January 14, 2018
Raphael, 1510 #devart pic.twitter.com/7uX0ompuAo
another Friday night deploy #devart pic.twitter.com/8dSgMbZqwj
— Dmitri Sotnikov ⚛ (@yogthos) January 11, 2018
VC runs into the founder of a blockchain AI startup at SoulCycle Palo Alto, 2017 #devart https://t.co/Kgnj4IcOlK
— Alex Companioni (@achompas) February 9, 2018
C# Developer Contemplates Switching to Node.js - Laszlo Mednyanszky, 1898 #devart pic.twitter.com/FwyQxmXMt5
— PoliticalMath (@politicalmath) November 27, 2017
And, sometimes you just want to break up the angry monotony of text with art that moves you. Turns out I’m not the only one.
If you don't follow @vboykis, she does a wonderful #devart series where she tweets out art w/ hilarious tech-y titles. Chris would LOVE it.
— PoliticalMath (@politicalmath) November 27, 2017
Vicki’s #devart project is my new favorite twitter thing. https://t.co/3MwTNNKJeB
— Rian van der Merwe (@RianVDM) February 9, 2018
As I posted more #devart, I realized that I enjoyed looking at the source art almost as much as figuring out a caption, and that I enjoyed accounts like Archillect, Rabih Almeddine’s, and Soviet Visuals, who all tweet a lot of beautiful visual content with at least some level of explanation.
I decided I wanted to build a bot that tweets out paintings. Particularly, I was interested in socialist realism artworks.
Why Socialist Realism
Socialist realism is an artform that was developed after the Russian Revolution. As the Russian monarchy fell, social boundaries dissovled,and people began experimenting with all kinds of new art forms, including futurism and abstractionism. I’ve previously written about this shift here.
As the Bolsheviks consolidated power, they established Narkompros, a body to control the education and cultrual values of what they deemend was acceptable under the new regime, and the government laid out the new criteria for what was accetable Soviet art.
Socialist realism as a genre had four explicit criteria, developed by the highest government officials, including Stalin himself. It was to be:
+ Proletarian: art relevant to the workers and understandable to them.
+ Typical: scenes of everyday life of the people.
+ Realistic: in the representational sense.
+ Partisan: supportive of the aims of the State and the Party.`
In looking at socialist realism art, it’s obvious that the underlying goal is to promote communism. But, just because the works are blatant propaganda doesn’t discount what I love about the genre, which is that it is indeed representative of what real people do in real life.
"PagerDuty"
— Vicki Boykis (@vboykis) February 14, 2018
Vladimir Kutilin #devart pic.twitter.com/onfI7bOxJL
These are people working, sleeping, laughing, frowning, arguing, and showing real emotion we don’t often see in art. They are relatable and humane, and reflect our humanity back to us. What I also strongly love about this genre of art is that women are depicted doing things other than sitting still to meet the artist’s gaze.
"Young, idealistic data scientists harvesting their first models for pickling"
— Vicki Boykis (@vboykis) October 6, 2017
Tetyana Yablonska, 1966 pic.twitter.com/iSlWhTEeED
So, what I decided is that I’d make a Twitter bot that tweets out one socialist realism work every couple of hours.
Here’s the final result:
"Young Naturalists"
— SovietArtBot (@SovietArtBot) February 15, 2018
Sergiy Grigoriev, 1948 pic.twitter.com/8KdwFS6PjU
There are several steps in traditional software development:
- Requirements
- Design
- Development
- Testing
- Deployment
- Maintenance
Breaking a Project into Chunks
This is a LOT to take in. When I first started, I made a list of everything that needed to be done: setting up AWS credentials, roles, and permissions, version control, writing the actual code, learning how to download images with requests, how to make the bot tweet on a schedule, and more.
When you look at it from the top-down, it’s overwhelming. But in “Bird by Bird,” one of my absolute favorite books that’s about the writing processs (but really about any creative process) Anne Lamott writes,
Thirty years ago my older brother, who was ten years old at the time, was trying to get a report on birds written that he’d had three months to write, which was due the next day. We were out at our family cabin in Bolinas, and he was at the kitchen table close to tears, surrounded by binder paper and pencils and unopened books on birds, immobilized by the hugeness of the task ahead. Then my father sat down beside him, put his arm around my brother’s shoulder, and said, “Bird by bird, buddy. Just take it bird by bird.”
And that’s how I view software development, too. One thing at a time, until you finish that, and then move on to the next piece. So, with that in mind, I decided I’d use a mix of the steps above from the traditional waterfall approach and mix them with the agile concept of making a lot of small, quick cycles of those steps to get closer to the end result.
Requirements and Design: High-Level Bot Architecture
I started building the app by working backwards from what my requirements:
a bot on Twitter, pulling painting images and metadata from some kind of database, on a timed schedule, either cron or something similar.
This helped me figure out the design. Since I would be posting to Twitter as my last step, it made sense to have the data already some place in the cloud. I also knew I’d eventually want to incorporate AWS because I didn’t want the code and data to be dependent on my local machine being on.
I knew that I’d also need version control and continuous integration to make sure the bot was stable both on my local machine as I was developing it, and on AWS as I pushed my code through, and so I didn’t have to manually put to code in the AWS console.
Finally, I knew I’d be using Python, because I like Python, and also because it has good hooks into Twitter through the Twython API (thanks to Timo for pointing me to Twython over Tweepy, which is deprecated) and AWS through the Boto library. I’d start by getting the paintings and metadata about the paintings from a website that had a lot of good socialist realism paintings not bound by copyright. Then, I’d do something to those paintings to get both the name, the painter, and title so I could tweet all of that out. Then, I’d do the rest of the work in AWS.
So my high-level flow went something like this:

Eventually, I’d refactor out the dependency on my local machine entirely and push everything to S3, but I didn’t want to spend any money in AWS before I figured out what kind of metadata the JSON returned.
Beyond that, I didn’t have a specific idea of the tools I’d need, and made design and architecture choices as my intermediate goals became clearer to me.
Development: Pulling Paintings from WikiArt
Now, the development work began.
WikiArt has an amazing, well-catalogued collection of artworks in every genre you can think of. It’s so well-done that some researchers use the catalog for their papers on deep learning, as well.
Some days, I go just to browse what’s new and get lost in some art. (Please donate to them if you enjoy them.)
WikiArt also has two aspects that were important to the project:
They have an explicit category for socialist realism art with a good number of works. 500 works in the socialist realism perspective, which was not a large amount (if I wanted to tweet more than one image a day), but good enough to start with.
Every work has an image, title, artist, and year,which would be important for properly crediting it on Twitter.
My first step was to see if there was a way to acces the site through an API, the most common way to pull any kind of content from websites programmatically these days. The problem with WikiArt is that it technically doesn’t have a readily-available public API,so people have resorted to really creative ways of scraping the site.
But, I really, really didn’t want to scrape, especially because the site has infinite scroll Javascript elements, which are annoying to pick up in BeautifulSoup, the tool most people use for scraping in Python.
So I did some sleuthing, and found that WikiArt does have an API, even if it’s not official and, at this point, somewhat out of date.
It had some important information on API rate limits, which tells us how often you can access the API without the site getting angry and kicking out out:
API calls: 10 requests per 2.5 seconds
Images downloading: 20 requests per second
and,even more importantly, on how to access a specific category through JSON-based query parameters. The documentation they had, though, was mostly at the artist level:
http://www.wikiart.org/en/salvador-dali/by-style/Neoclassicism&json=2
so I had to do some trial and error to figure out the correct link I wanted, which was:
https://www.wikiart.org/en/paintings-by-style/socialist-realism?json=2&page=1
And with that, I was ready to pull the data.
I started by using the Python Requests library to connect to the site and pull two things:
- A JSON file that has all the metadata
- All of the actual paintings as
png/jpg/jpegfiles
Development: Processing Paintings and Metadata Locally
The JSON I got back looked like this:
{
ArtistsHtml: null,
CanLoadMoreArtists: false,
Paintings: [],
Artists: null,
AllArtistsCount: 0,
PaintingsHtml: null,
PaintingsHtmlBeta: null,
AllPaintingsCount: 512,
PageSize: 60,
TimeLog: null
}
Within the paintings array, each painting looked like this:
{
"id": "577271cfedc2cb3880c2de61",
"title": "Winter in Kursk",
"year": "1916",
"width": 634,
"height": 750,
"artistName": "Aleksandr Deyneka",
"image": "https://use2-uploads8.wikiart.org/images/aleksandr-deyneka/winter-in-kursk-1916.jpg",
"map": "0123**67*",
"paintingUrl": "/en/aleksandr-deyneka/winter-in-kursk-1916",
"artistUrl": "/en/aleksandr-deyneka",
"albums": null,
"flags": 2,
"images": null
}
I also downloaded all the image files by returning response.raw from the JSON and using the shutil.copyfileobj method.
I decided not to do anymore processing locally since my goal was to eventually move everything to the cloud anyway, but I now had the files available to me for testing so that I didn’t need to hit WikiArt and overload the website anymore.
I then uploaded both the JSON and the image files to the same S3 bucket with the boto client, which lets you write :
def upload_images_to_s3(directory):
"""
Upload images to S3 bucket if they end with png or jpg
:param directory:
:return: null
"""
for f in directory.iterdir():
if str(f).endswith(('.png', '.jpg', '.jpeg')):
full_file_path = str(f.parent) + "/" + str(f.name)
file_name = str(f.name)
s3_client.upload_file(full_file_path, settings.BASE_BUCKET, file_name)
print(f,"put")
As an aside, the .iterdir() method here is from the pretty great pathlib library, new to Python 3, which handles file operations better than os. Check out more about it here.
Development: Using S3 and Lambdas
Now that I had my files in S3, I needed some way for Twitter to read them. To do that at a regular time interval, I decided on using an AWS Lambda function (not to be confused with Python lambda functions, a completely different animal.) Because I was already familiar with Lambdas and their capabilities - see my previous post on AWS - , they were a tool I could use without a lot of ramp-up time (a key component of architectural decisions.)
Lambdas are snippets of code that you can run without needing to know anything about the machine that runs them. They’re triggered by other events firing in the AWS ecosystem. Or, they can be run on a cron-like schedule, which was perfect for what I wanted to do. This was exactly what I needed, since I needed to schedule the bot to post at an interval.
Lambdas look like this in Python:
def handler_name(event, context):
...
return some_value
The event is what you decide to do to trigger the function and the context sets up all the runtime information needed to interact with AWS and run the function.
Because I wanted my bot to tweet both the artwork and some context around it, I’d need a way to tweet both the picture and the metadata, by matching the picture with the metadata.
To do this, I’d need to create key-value pairs, a common programming data model, where the key was the filename part of the image attribute, and the value was the title, year, and artistName, so that I could match the two, like this:

So, all in all, I wanted my lambda function to do several things. All of that code I wrote for that section is here.
- Open the S3 bucket object and inspect the contents of the metadata file
Opening an S3 bucket within a lambda usually looks something like this:
def handler(event, context):
for record in event['Records']:
bucket = record['s3']['bucket']['name']
key = record['s3']['object']['key']
download_path = '/tmp/{}{}'.format(uuid.uuid4(), key)
s3_client.download_file(bucket, key, download_path)
where the event is the JSON file that gets passed in from Lambda that signifies that a trigger has occurred. Since our trigger is a timed event, our JSON file doesn’t have any information about that specific event and bucket, and we can exclude the event, in order to create a function that normally opens a given bucket and key.
try:
data = s3.get_object(Bucket=bucket_name, Key=metadata)
json_data = json.loads(data['Body'].read().decode('utf-8'))
except Exception as e:
print(e)
raise e
- Pull out the metadata and pull it into a dictionary with the filename as the key and the metadata as the value. We can pull it into a
defaultdict, because those are ordered by default (all dictionaries will be orded as of 3.6, but we’re still playing it safe here.)
indexed_json = defaultdict()
for value in json_data:
artist = value['artistName']
title = value['title']
year = value['year']
values = [artist, title, year]
# return only image name at end of URL
find_index = value['image'].rfind('/')
img_suffix = value['image'][find_index + 1:]
img_link = img_suffix
try:
indexed_json[img_link].append(values)
except KeyError:
indexed_json[img_link] = (values)
(By the way, a neat Python string utility that I didn’t know before which really helped with the filename parsing was (rsplit) [http://python-reference.readthedocs.io/en/latest/docs/str/rsplit.html]. )
Pick a random filename to tweet (
single_image_metadata = random.choice(list(indexed_json.items())))Tweet the image and associated metadata
There are a couple of Python libraries in use for Twitter. I initially started using Tweepy, but much to my sadness, I found out it was no longer being maintained. (Thanks for the tip, Timo. )
So I switched to Twython, which is a tad more convoluted, but is up-to-date.
The final piece of code that actually ended up sending out the tweet is here:
twitter = Twython(CONSUMER_KEY, CONSUMER_SECRET, ACCESS_TOKEN, ACCESS_SECRET)
try:
tmp_dir = tempfile.gettempdir()
#clears out lambda dir from previous attempt, in case testing lambdas keeps previous lambda state
call('rm -rf /tmp/*', shell=True)
path = os.path.join(tmp_dir, url)
print(path)
s3_resource.Bucket(bucket_name).download_file(url, path)
print("file moved to /tmp")
print(os.listdir(tmp_dir))
with open(path, 'rb') as img:
print("Path", path)
twit_resp = twitter.upload_media(media=img)
twitter.update_status(status="\"%s\"\n%s, %s" % (title, painter, year), media_ids=twit_resp['media_id'])
except TwythonError as e:
print(e)
What this does is take advantage of a Lambda’s temp space:
TIL that AWS Lambda Functions have miniature file systems that you can use as temporary storage (https://t.co/egCKwu6GJB).
— Vicki Boykis (@vboykis) January 3, 2018
Pulls the file from S3 into the Lambda’s /tmp/ folder, and matches it by filename with the metadata, which at this point is in key-value format.
The twitter.upload_media method uploads the image and gets back a media id that is then passed into the update_status method with the twit_resp['media_id'].
And that’s it. The image and text are posted.
Development: Scheduling the Lambda
The second part was configuring the function. to run on a schedule. Lambdas can be triggered by two things:
- An event occurring
- A timed schedule.
Events can be anything from a file landing in an S3 bucket, to polling a Kinesis stream.
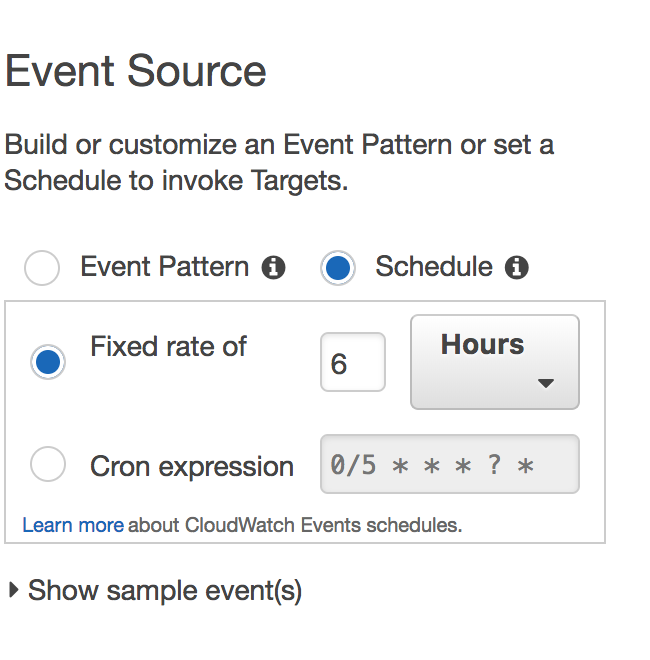
Scheduled events can be written either in cron, or at a fixed-rate. I started out writing cron rules, but since my bot didn’t have any specific requirements, only that it needed to post every six hours, the fixed rate turned out to be enough for what I needed:
Finally, I needed to package the lambda for distribution. Lambdas run on Linux machines which don’t have a lot of Python libraries pre-installed (other than boto3, the Amazon Python client library I used previously that connects the Lambda to other parts of the AWS ecosystem, and json. )
In my script, I have a lot of library imports. Of these, Twython is an external library that needs to be packaged with the lambda and uploaded.
from twython import Twython, TwythonError
Deployment: Bot Tweets!
So I packged the Lambda based on those instructions, manually the first time, by uploading a zip file to the Lambda console.
And, that’s it! My two one-off scripts were ready, and my bot was up and running.

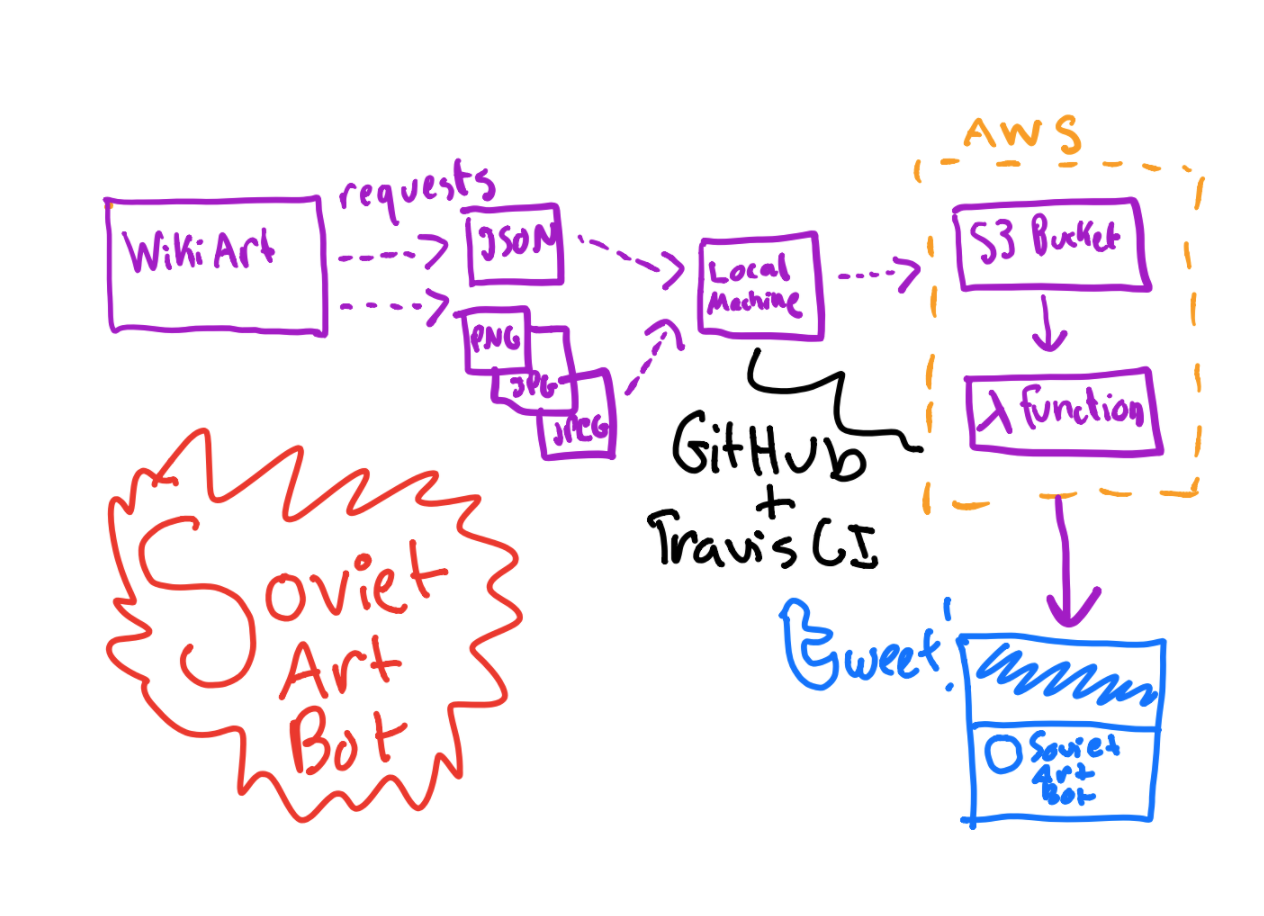
And here’s the final flow I ended up with:
Where to Next?
There’s a lot I still want to get to with Soviet Art Bot.
The most important first step is tweaking the code so that no painting repeats more than once a week. That seems like the right amount of time for Twitter followers to not get annoyed.
In parallel, I want to focus on testing and maintenance.
Testing and Maintenance
The first time I worked through the entire flow, I started by working in a local Python project I had started in PyCharm and had version-controlled on GitHub.
Me, trying to explain the cases when I use PyCharm, when I use Sublime Text, and when I use Jupyter Notebooks for development. pic.twitter.com/CEC0WlymlC
— Vicki Boykis (@vboykis) January 18, 2018
So, when I made changes to any part of the process, my execution flow would be:
- Run Wikiart download functionality locally
- Test the lambda “locally” with
python-lambda-local - Zip up the lambda and upload to Lambda
- Make mistakes in the Lambda code
- Zip up the lambda and run again.
This was not really an ideal workflow for me, because I didn’t want to have to manually re-uploading the lambda every time, so I decided to use Travis CI, which integrates with GitHub really well.. The problem is that there’s a lot of setup involved: virtualenvs, syncing to AWS credentials, setting up IAM roles and profiles that allow Travis to access the lambda, setting up a test Twitter and AWS environment to test travis integration, and more.
For now, the bot is working in production, and while it works, I’m going to continue to automate more and more parts of deployment in my dev branch. (This post was particularly helpful in zipping up a lambda, and my deploy script is here.
After these two are complete, I want to:
Refactor lambda code to take advantage of
pathlibinstead of OS so my code is standardized (should be a pretty small change)Source more paintings. WikiArt is fantastic, but has only 500ish paintngs available in the socialist realism category. I’d like to find more sources with high-quality metadata and a significant collection of artworks. Then, I’d like to
Create a front-end where anyone can upload a work of socialist realism for the bot to tweet out. This would probably be easier than customizing a scraper and would allow me to crowdsource data. As part of this process, I’d need a way to screen content before it got to my final S3 bucket.
Which leads to:
- Go through current collection and make sure all artwork is relevant and SWF. See if there’s a way I can do that programmatically.
And:
- Machine learning and deep learning potential possibilities: Look for a classifier to filter out artworks with nudity/questionable content and figure out how to decide what “questionable” means. Potentially with AWS Rekognition, or building my own CNN.
Other machine learning opportunities:
Mash with #devart to see if the bot can create fun headlines for paintings based on painting content
Extract colors from artworks by genre and see how they differ between genres and decades
Conclusion
Software development can be a long, exhausting process with a lot of moving parts and decision-making involved, but it becomes much easier and more interesting if you you break up a project into byte-sized chunks that you can continuously work on to stop yourself from getting overwhelemed with the entire task at hand. The other part, of course, is that it has to be fun and interesting for you so that you make it through all of the craziness with a fun, finished product at the end.