The ghosts in the data

Bernadette Resha, Gathering of Ghosts (2014)
Something I’ve been thinking about recently as I’ve been working at a company that operates entirely remotely and mostly asynchronously during a time when most companies are working in some variation of this model is the idea of implicit versus explicit knowledge.
Explicit knowledge is anything that you can read about, knowledge that’s easy to share and pass on. Implicit knowledge is knowledge that people gain by context that’s very hard to pull out consciously. The best example of this is from this paper on language acquisition,
Children acquire their first language by engaging with their caretakers in natural meaningful communication. From this “evidence” they automatically acquire complex knowledge of the structure of their language. Yet paradoxically they cannot describe this knowledge, the discovery of which forms the object of the disciplines of theoretical linguistics, psycholinguistics, and child language acquisition.
This is a difference between explicit and implicit knowledge—ask a young child how to form a plural and she says she doesn’t know; ask her“ here is a wug, here is another wug, what have you got?”and she is able to reply, “two wugs.” The acquisition of L1 grammar is implicit and is extracted from experience of usage rather than from explicit rules.
Some time ago, Caitlin tweeted,
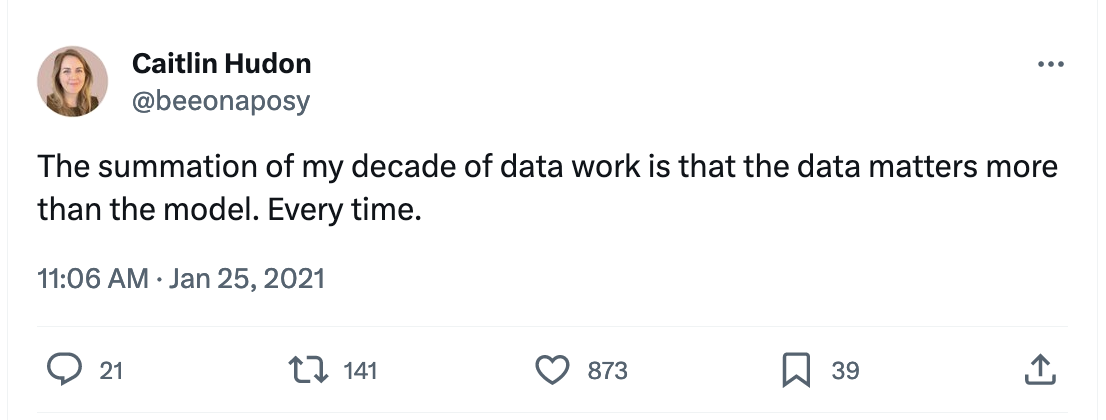
I’ve tweeted similar observations a while back:
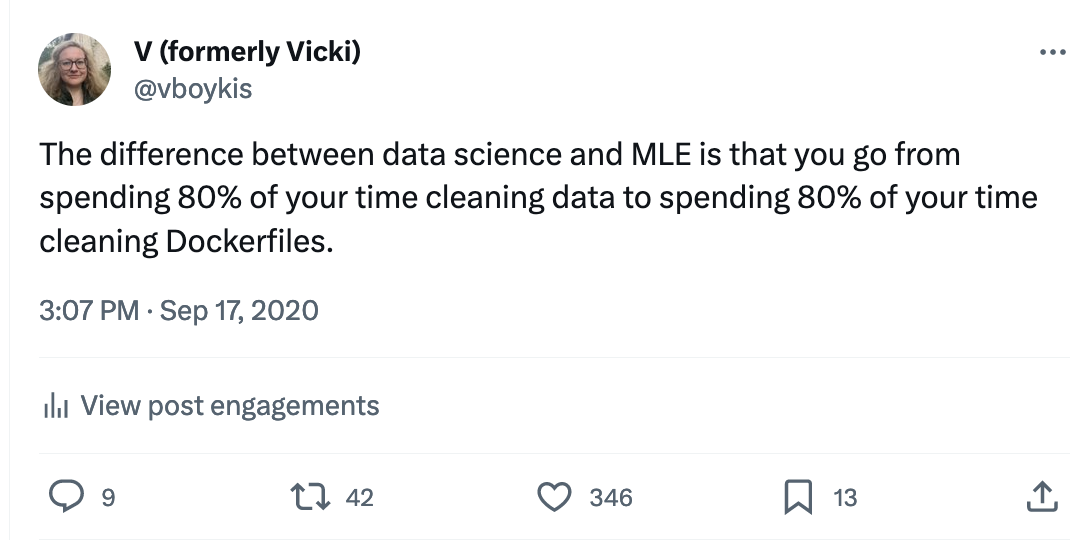
The basic block of labor of machine learning is cleaning data and setting up engineering pipelines, the detailed and tedious work of making all the pieces fit together.
However, there is no way you can learn this, except to have to deal with a lot of data that’s not clean, and to build a lot of models. So, this very fundamental fact is not immediately obvious to people new to the field until they’ve gained the experience. And, what’s worse is that there’s no guide, pamphlet, textbook, or course that will give you this piece of implicit knowledge. Implicit knowledge is also what David has called, brilliantly, “ghost knowledge, " or, “knowledge that exists within expert communities but is never written down and basically doesn’t exist for you unless you have access to those communities.” Here’s his full post on it and why it happens:
The core problem that causes all of this is that there’s a leaky pipeline of knowledge from epistemic communities to the outside world. In order for you to discover a piece of knowledge:
It has to be interesting enough for someone to think it is worth writing down. It has to be interesting enough that it gets accepted (though if not, it may end up on a random blog post if you’re lucky). It has to be interesting or well organised enough that it gets surfaced in a way you can find. It has to be accessible enough for you to be able to find it (e.g. it can’t use super technical terms that you’ll have no way to ever discover without access to an expert).
Having clean data is in this category of “ghost knowledge” that, if you’ve been working in data for a long time, you know painfully from your own experience. It’s only extremely recently that this knowledge started being written down in a codified way. And by recently, I mean that there was a paper published by Google in January 2021.
Here’s the first part of the abstract:
AI models are increasingly applied in high-stakes domains like health and conservation. Data quality carries an elevated signifi-cance in high-stakes AI due to its heightened downstream impact, impacting predictions like cancer detection, wildlife poaching, andloan allocations. Paradoxically, data is the most under-valued and-glamorised aspect of AI.
This is probably the first time I’ve personally seen something formally stated about the need for having clean data as impacting model performance.
Mulling over this fact, I wondered what else was ghost knowledge in the data community, and so I asked.
What I found was a wealth of learnings that people wrote from painful personal experience. The replies generally fall into two categories: the ghost knowledge in dealing with data and the ghost knowledge in dealing with people.
Inspired by the replies, I wanted to write about a few key important implicit observations I’ve made in my own data career.
The power law
What they tell you in statistics classes is that you’re assuming the population you’re drawing from is normally distributed. In other words, your data follows a bell curve, where most of the people fall somewhat close to the mean, with a few outliers.
There is a whole set of implications in assuming your data is distributed this way. I.e. if you assume a “normal” model of society, you can do this kind of math on it to get the answers you need from data.
Real life phenomena, as I’ve seen them in industry, mostly do not follow a bell curve. Most of the data that people deal with across industries involves activities that people do: people on your platform, people clicking things, people receiving vaccines or medical treatments, restaurant visits, etc. And all of that data looks like this:
{kind=link}
This essentially means that a few people do some activity a lot, and the rest not as much at all.
Here are some real world examples:
And much, much more. This means that we can’t deal with the data in the same way, particularly for smaller samples of data, because
Gaussian and Paretian distributions differ radically. The main feature of the Gaussian distribution … can be entirely characterized by its mean and variance … A Paretian distribution does not show a well-behaved mean or variance. A power law, therefore, has no average that can be assumed to represent the typical features of the distribution and no finite standard deviations upon which to base confidence intervals . .
There are both statistical and business implications for how you deal with this rule. In particular, it means that paying attention to tail-end phenomena is just as as important as understanding an “average” user.
And, once you see this pattern in your data, you’ll never be able to unsee it.
Collecting data
How do you actually get this data that you’re looking to analyze? Most of the time, it is very, very hard and encompasses most of the work of any given data project.
First, you have to build a pipeline to collect the data. Then, you have to clean the data.
What makes it harder is that dealing with data is like dealing with a moving river (perhaps that’s the reason we’ve developed so many water terms around our data processes - data lakes, streams, and putting all of it in the cloud.) Data is ephemeral and constantly shifting as users input data, engineers log different things, and you gain or lose access to storage.
You don’t do the process of verifying the data once, you do it many times because a lot of times some process upstream will change. As long as you don’t control the upstream process, you don’t control your data.
What’s even more amazing is that there is no standard process in the tech industry to clean data. This problem is so pervasive that there are now hundreds of SaaS solutions. There is no book on how to clean data, what kind of constraints to set to make sure the data is clean, or even what kind of tools to use.
It could be as simple as a bash script that you run that removes duplicate lines, or it could be an Airflow pipeline that checks the validity of tables in Redshift on a daily basis, or it could be a number of one-liners in Pandas, or it could be enforcing specific data constraints at the point where your data is actually generated.
The best way to understand the true scope of what it takes to clean data and keep it clean is to understand how different companies do it.
A couple subsets of the data is a hard problem: Dealing with dates is going to bite you at some point. Randy had a really good post about this a while back. Here’s another excellent post about it.
No one ever gets time right all the time and the first time you get it wrong, you’ll never forget it, as happened to me when I was presenting an analysis to executives and realized that I had forgotten to convert the time to UTC.
Data work is programming work
I’ve been talking about this for a while, but the longer we are into this thing called machine learning, and we’re just in the steam-powered days, still. The further we get away from working with small data sets, and more with large, complicated (often) cloud-based, based distributed systems, the more we’ll all have to become developers and adapt development best practices.
What are the best practices of data development today? Good work that is easily named and easily reproducible. Notebooks where applicable, written, tested modules the rest of the way. Version control for code. And documentation.
The thing we have to keep in mind though, is that the needs of programming and data work are fundamentally different. As I said,
The friction between analytics work and engineering work always will be that engineering sees data as an insignificant byproduct of writing code and analytics sees writing code as an irritating hassle to get to the data.
Developers writing apps need them to be stable and traceable. Analysts looking at the data need it to be clean. It’s in the incentive for the developer to have fast-working, reliable apps at the expense of accurate data (for example, adding clear, detailed activity logging is important but often an afterthought), and it’s in the incentive for analysts to have good data, even if that means pausing some process to fix it.
This means that there will always be a conflict between moving quickly to ship features on a given application and logging those features and making sense of them. It’s up to the data professional to navigate that chasm and make sense of it.
Working with people is hardest of all
Software engineering is really, really hard. There is a lot of thinking involved, a lot of moving parts. You have to understand how complex systems work, reason through the statistics, and keep up with the latest frameworks in the field.
And yet, dealing with people is even harder, and often, the heart of either success or failure for machine learning products.
The one thing that is never covered in any class is that you will have to deal with workplace politics, and how successful you are at navigating this hierarchy will determine how you’re perceived at work just as much as the actual quality of your work.
Workplace politics exist at every workplace regardless of size or shape or industry, and are simply a manifestation of the natural inner workings of human relationships, carried out in a structure where hierarchy is enforced by who you report to and who pays you.
And there is hierarchy in every company, from a tiny two-person startup, to companies that practice holocracy, to large conglomerates whose motto used to be “Don’t be evil.”
The best resources that I know for learning how to navigate these structures are by talking to coworkers and observing people who are good at corporate politics, but more importantly, becoming good at navigating human relationships, on a day-to-day basis.
What do those who you look up to in the company do? What kinds of things do they say? How do they help people?
Some good secondary resources are reading anonymous forums like Reddit’s compsci career questions, r/sysadmin, r/data science sometimes, Ask A Manager are also all solid ways to learn about corporate politics.
And, here are some good general posts. Rands has a fantastic collection of articles which have since been turned into books about how people in organizations work. Here’s an example. Lara has some good posts about how to understand your manager’s perspective and work well with them. If you can work well with your manager and understand how to make them successful, you can achieve almost anything. My favorite recent post is one by Julia, “Things Your Manager May Not Know.”
And finally, there is Venkatesh’s excellent (but cynical) post, from over 10 years ago, on corporate power structures.
People usually do not operate based on the data
The final thing I’ve learned is that companies operate mostly on gut instinct. Many will tell you that they’re data-driven. People love this idea, of making decisions based on The Numbers, and want to belive it about themselves. I want to believe this about myself!
But oftentimes, data will serve mostly as supporting evidence for a gut check, and the gut check depends on a lot of factors, including whether you trust the person presenting the data, what your view of the company is, and what corporate politics are at play.
This is not to end on a discouraging note - it doesn’t mean that you can just make up numbers and expect to get somewhere. What it means is that it’s important to establish yourself as knowledgeable, trustworthy, and able to clearly communicate what you’re talking about, regardless of what job you’re in, because the discussion around the data will be just as important as the data itself.
Or rather, a more optimistic way to think about this is that the analysis or dashboard is (and should be) the beginning and framing of a conversation, not the end of it. And if you frame it correctly, it’s yours to lead.
If you have any other pieces of ghost knowledge, feel free to shoot me an email or a tweet.