The programmer's brain in the lands of exploration and production

A lot of my brain space lately has been occupied by TypedPipes. A TypedPipe is the main object type that you work with in Scalding, a distributed data framework written as a wrapper in Scala around Cascading. Scalding was originally developed at Twitter, and adopted by many companies around the same time Apache Spark became popular.
A TypedPipe is a distributed array that “may or may not have been materialized to disk”, aka it’s a very large list of elements that exists mainly in the memory space of your program, where the memory space is usually the nodes of a distributed computational cluster.
Once you have access to large sets of data in a datastore like S3 or HDFS, you can work with them as TypedPipes by using functional programming methods: map, flatMap, collect, grouping, and joins, to either create the dataset you need for a machine learning model or write the modeling code itself.
Here’s the canonical hello world example, that I used to do the Map/Reduce example for wordcount of all the words in my blog.
(By the way, it’s fun to see that, once you filter the stop words out of my top 50, the “real” words are python, data, and people, which I think sums up my blog pretty well.)
On the face of it, it’s a very small and simple example. If you’re just getting started with Scalding, it should be easy to get going. But, when I started learning Scalding for working with machine learning code a few months ago and came across this example code, I was completely lost.
Understanding the concepts that underly the simple example came extremely hard to me, which was a surprise since I’ve now been writing production-grade distributed systems code using the standard hash aggregate workflows, for the last 10 years. And, I was just as interested in understanding why I didn’t understand the code as I was in learning to read it.
This Programmer’s Brain
Luckily, right around the time that I started diving into Scalding, I also started reading “The Programmer’s Brain.” by Dr. Felienne Hermans. The author is a professor of computer science whose research focuses on how people learn to program and use programming languages, and the book is wonderful.
In the book, Dr. Hermans asserts that when we get confused about the code we’re writing, there are actually multiple types of confusion happening at the same time.
As a quick primer, the human brain has several types of memory, short-term, working, and long-term. Short-term memory gathers information temporarily and processes it quickly, like RAM. Long-term memory are things you’ve learned previously and tucked away, like database storage. Working memory takes the information from short-term memory and long-term memory and combines them to synthesize, or process the information and come up with a solution.
When we’re working on code, (and by working on, we mean most often reading someone else’s code) all of these processes are going on in our brain simultaneously to try to help us make sense of the programming environment.
If it’s a programming language we know and a paradigm we’re familiar with, everything works together smoothly. But if it’s something new, we have the potential to get overwhelmed on multiple levels. Here are just a few ways that we can get confused:
Lack of information - Short-term issue
This happens when we try to understand what the variables are that are set in a program. If we see something like this: n: Int = 5 , it’s easy for us to understand that n is a number and move on to tracing the rest of the activity related to n. However, if we see n: TypedPipe = TypedPipe.from(TextLine("posts.txt")) , we might not understand what that returned object looks like, particularly if we don’t know the format of posts.txt .
The most amazing part of the human brain is that it can only store aboutseven items concurrently. Some recent research has found that it’s even less, about a byte of memory, which is why short-term memory often leans very heavily on long-term memory to add context to variables
Lack of knowledge - Long term memory issue
While short-term memory stores intermediate program variable names and short-term information, long-term memory stores language syntax and processing, it’s where our knowledge about how programming languages are structured look. This includes what specific functions do, how a programming language is structured, its API, and common architecture patterns.
So if you’ve never worked with Scala and Scalding before , you may be completely thrown off by both its syntactic sugar (when you don’t know what => does and you may not know what a Job is (the way you set up a Scalding run)) and struggle with understanding how you can run the job.
Lack of processing power - Issue in working memory
The final type of confusion happens when you can’t follow the code through a program because there are too many variables and, quite simply, you can’t hold enough ideas about the program in memory . For example, it can be hard to understand what resulting data structures or Scala collections you get from each part of a chained TypedPipe operation using .groupBy { word => word } changes the underlying data structure and what it returns, and so on through the call chain. There are ways around this, for example with the help of your IDE, but it still relies on you personally carrying a high cognitive load.
Our hol-ey neural nets
In addition to the three issues you’re dealing with at any given time, you also have the cognitive overhead of not just the language’s syntax, stored variables in memory, and language features, but you’re learning the ecosystem of the language, as well. I’ve argued before that the ecosystem you’re programming in is just as essential as the code and the very first thing you encounter when you start to write any new code:
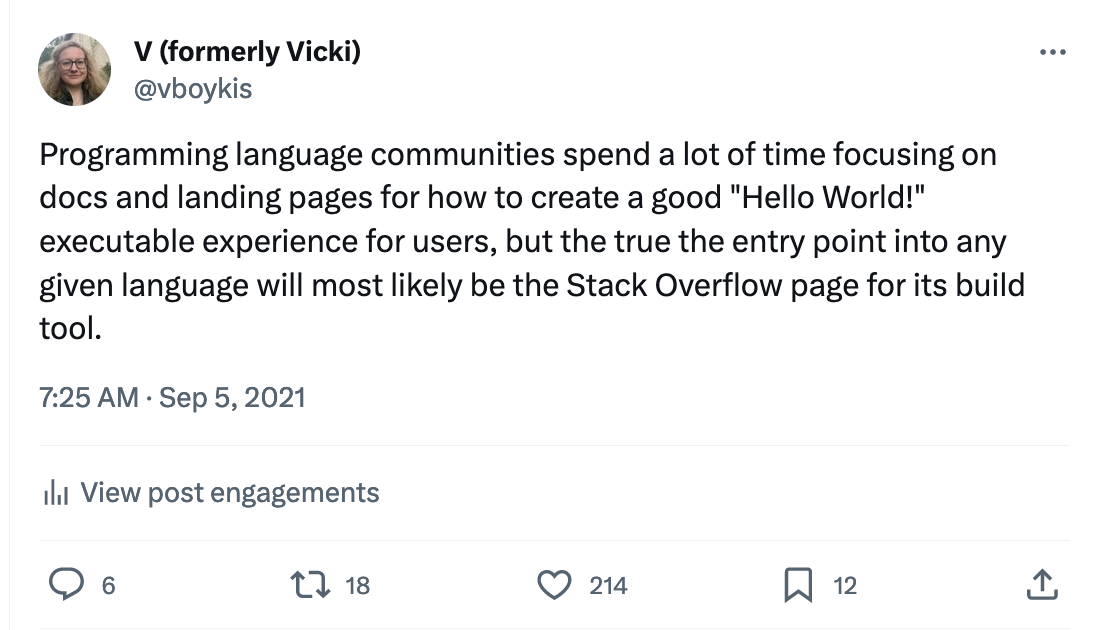
For example, for Scalding, one of the first things I had to understand was not only how to build and iterate on building an SBT project, but also how to read from a file that’s not a website (which is the canonical example given in the Scalding documentation), how to start up the Scalding REPL and how to understand where it’s reading files from (it’s the directory that you download and place the REPL into.)
Compounded with the fact that there is not nearly as much documentation for Scalding as for Spark, different Scala versions, and all of this makes a perfect storm of confusion for the Scalding beginner.
So for me, as I was learning Scalding, I was actually learning all of these things simultaneously:
- Scalding syntax
- Scalding directory and job structure
- Scalding file operations
- Scala syntactic sugar
- Functional programming core concepts
- SBT
- How all of that works wrapped in a Docker container
- How that Docker container runs in Hadoop
- How that job accesses the files in HDFS
- And then all of the MLOPs stuff on top of that(how to monitor that job, what parameters it sends to Jenkins, all of the Airflow code associated with re-running that job, and more)
This list doesn’t even begin to include the core of machine learning logic I was writing yet.
Prototyping versus Production
What made all of this harder on my working memory is that Scalding is not meant for inspecting intermediate results in the same way that Spark has. Yes, you can write out a file to disk, but you wouldn’t want to write a file every time you want to look at some results quickly in the terminal. Additionally, you can use .dump , but since you’re persisting a large amount of data locally, Scalding asks you to consider filtering as much as you possibly can before you do that, which hinders exploration.
Since Scalding is a heavy-duty workhorse framework that’s meant to move lots of data in a distributed manner with type safety versus being a platform for data exploration, it’s harder to dump out stuff to screen or logs. Instead the better practice is to follow the types as you write them.
As a developer who’s previously written a ton of good lold REPL-based Python code, Jupyter Notebooks, PySpark, Spark Scala, Lambdas, and even lots of cloud JSON and YAML, I’m used to being able to intermediately inspect any results I have and iterate on them in my code base, change some code, run it again, and look at the results again very quickly, and working this way proved to be a huge adjustment in my mentality.
As I was working through it, I wanted to understand a bit better about these two ways of development. The types versus no types paradigm as described in this great tweet is probably one of the most important tradeoffs I know in development, and something I’ve been thinking about recently as I’ve been writing more Scala.
I think this tradeoff is at the heart of the “two-language” problem in data science:
The “Two-Language Problem” is a very typical situation in scientific computing where a researcher devises an algorithm or a solution to tackle a desired problem or analysis at hand. Then, the solution is prototyped in an easy to code language (like Python or R). If the prototype works, the researcher would code in a fast language that would not be easy to prototype (C++ or FORTRAN). Thus, we have two languages involved in the process of developing a new solution. One which is easy to prototype but is not suited for implementation (mostly due to being slow). And another which is not so easy to code, and consequently not easy to prototype, but suited for implementation because it is fast.
In other words, you can either be easy for prototyping or easy for production. You usually can’t be both. Now, some will argue that there are languages that fit both purposes, and it’s true, there are cases of prototyping languages in production and production languages used for prototypes, but by trying to fit one in another, we lose something of the properties of both.
A very recent example of this is the implementation of type annotations for Python. They are wonderful and I cannot function without them in any of my codebases anymore, but I would never use them in exploration, because at that stage I just don’t know enough about my data to guarantee them, and they slow me down as I’m playing and learning about my data.
Where all of this gets interesting is understanding where the data landscape is moving. Data work in companies started with statistics, with compiled analyses, with hand-crafted libraries. A lot of this work took place in prototypable languages and ecosystems, and a lot of the developers who worked in the early days of data science, yours truly included, are used to operating mostly in prototype languages and environments with regards to data.
However, what’s happening more and more is two things. First, more and more of data work is becoming engineering work. And more engineering work than ever is not writing libraries, but gluing together libraries that we’ve now commoditized and put together to work in the cloud.
At the same time, in trying to keep up with that movement, for those used to working very iteratively and quickly with data in the data community, we’re also moving a lot of workflows that were purely exploratory in nature into production, which is why we now have these ideas of, for example, Jupyter Notebooks as production environments, and the increased use of the DataFrame as a first-class data object (and, now, also the Pandas API for Spark!) for moving large amounts of data as well.
Where learning Scalding caught me was, as is the case for much data tooling these days, coming from the land of exploration, to the land of production, and the differences were very large.
Overcoming the programmer’s brain
Back to our brains: how can we make sure that any codebase we work with becomes less confusing for us? The Programmer’s Brain gives some wonderful high-level ideas about how to combat confusion at work, and there are a couple that have really struck with me as I make my way through Scalding and Scala. First is to write down code syntax so that your brain remembers it for next time, and processes it, instead of copying and pasting, which is something that I’m constantly guilty of.
Second, is reading and adding what “Programmer’s Brain” calls beacons in the code, which could be comments, but, more generally, are places in the code that your mind can anchor against and do the work of chunking, or processing groups of information. These could be very clear variable names, or well-defined methods.
Something that helped me with this was installing and using Ammonite, a very, very good Scala repl that breaks down syntax and functions in the same way that using a notebook might. For example, here’s a small script I put together to actually get the input data for my Scalding job.
What also helped tremendously was reading a lot of other Scalding code in our internal repo for comments and examples.
And third, when you’re overwhelmed, go easy on yourself and understand that you’re overwhelmed and why that’s the case, and then work on addressing that by climbing out of the local minima of suckiness, which is what this post was all about.
#data science #distributed systems #code #engineering #java #scala