Some notes on the Stable Diffusion safety filter
In time for NeurIPS 2022, there are a lot of interesting papers and preprints being published on ArXiv.
One I ran into recently was “Red-Teaming the Stable Diffusion Safety Filter.”
Having worked on content moderation before, the concept of how to moderate the content of a deep learning model was interesting to me and I thought it benefitted from a broader look.
Let’s dive in by starting with the paper title. The concept of “red-teaming” comes from cybersecurity. A red team is a group of people who have been authorized to act as an attacker in a given organization and probe for threats against a company’s security set-up. What they do can range from social engineering to penetration testing. The counter to this is the blue team, who defends against the red-team in this simulated scenario.
In this case, the researchers acting as the red team are trying to understand if they can bypass the safety filter that performs a high-level check on the output of a prompt generated by the Stable Diffusion model as hosted by HuggingFace in the Diffusers Toolkit.
Quick notes on diffusion models and Stable Diffusion
Stable Diffusion is a text-to-image model released publicly in mid-2022 (seems like forever ago) that generates images based on text prompts that the user inputs. Other, earlier models in the diffusion family include DALL-E and Midjourney, both of which were gated behind websites without a chance to inspect the code.
At an extremely high level, diffusion models work by learning to add statistically distributed noise to an image or a representation of an image and then, again, statistically removing noise until you get a picture that matches the properties of the input dataset but is, statistically, not the same image that was input.
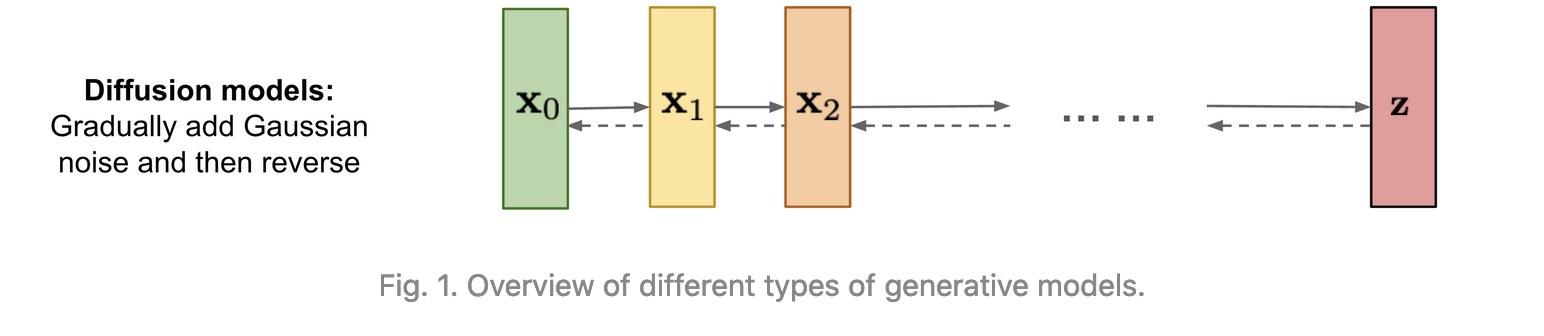
Stable Diffusion works by:
- Taking a large training set of real images (StableDiffusion itself was trained on 2.3 Billion images that are part of the LAION dataset and selected based on images that match a threshold for “aesthetic score”.)
- To make the pre-processing steps faster, the images are compressed into a smaller-dimension representation using a variational autoencoder - the paper romantically calls this “departure to latent space.”
- During the pre-processing used to generate the model’s input data, Gaussian noise is applied to the images’ latent representation.
- Each time we add noise to a step, we generatively build the part of the model called a “noise predictor”, which then allows us, for any given image, to probabilistically predict how much noise was added and how far it deviates from the original image. That prediction allows us to compare to the known noise from the original training data.
- Once we train this noise predictor we can then run a decoder to denoise the data in small increments, which will remove that noise from a given image until we get a different image than the training set, but one that is semantically similar to the training set.
Here’s the overall image-specific architecture:
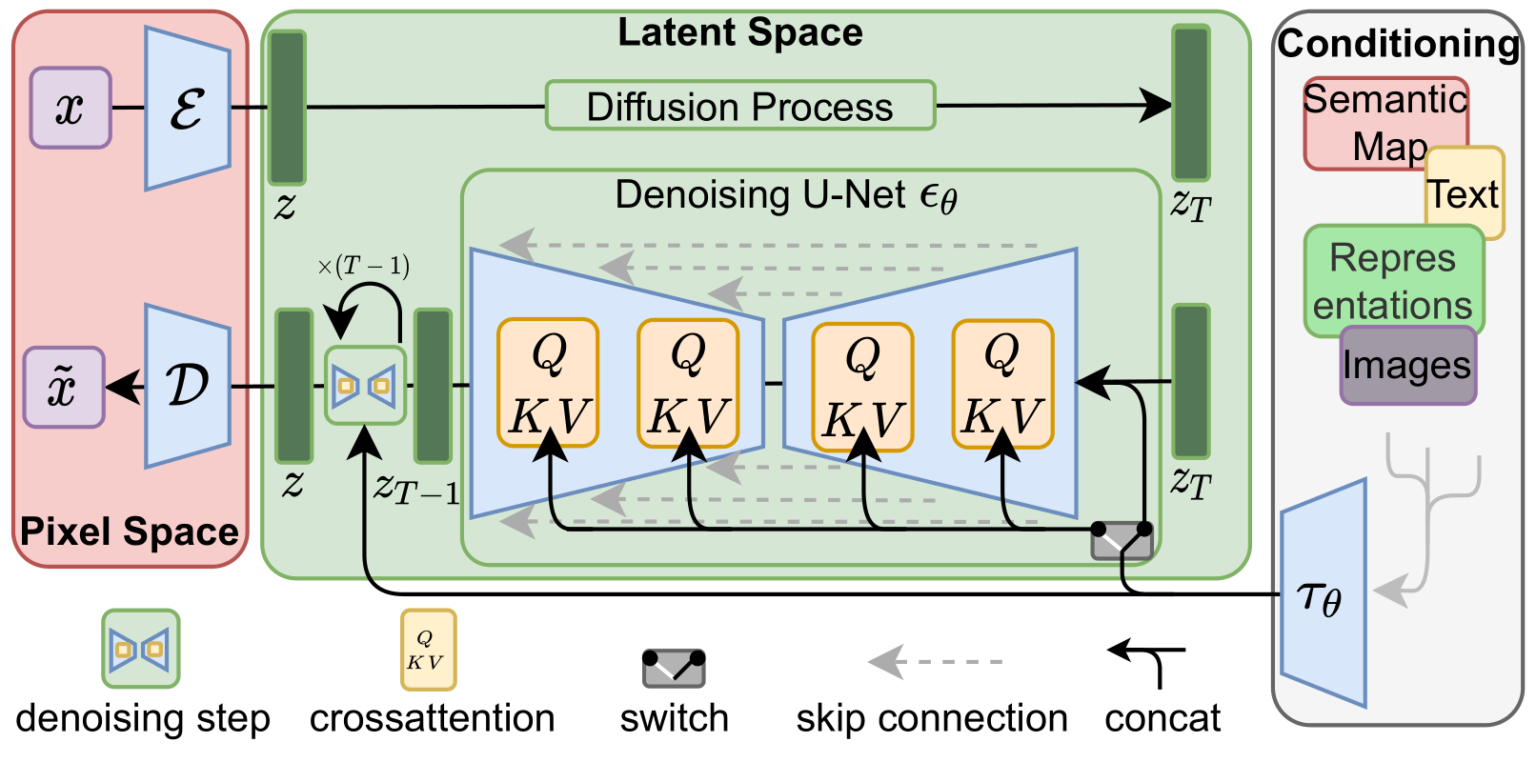
How do we now incorporate text? During inference, diffusion models work by adding guidance (otherwise, we’d just get random images without ability to steer from a text prompt):
- The model uses a Transformer language model, ClipText, to generate textual embeddings for the specific text prompt. Here’s a lot more information on how that model was trained, but the general idea is that you have captioned images in which both the image and the caption, separately, are embedded into the same latent space using an encoder and compare the embeddings for the text and image using cosine similarity.
- We pass these embeddings also into the UNet noising encoder that includes specific attention to the text, as well, and incorporate it in processing so that when we pass in a text prompt, we include that information in inference.
HuggingFace Diffusers
As I mentioned, there are several ways to work with this model. If you are lucky enough to have at least 6GB of VRAM, you can download the model and work with it locally. Since there is no safety filter on that model, in the model card, there are a number of different caveats for misuse.
Misuse and Malicious Use
Using the model to generate content that is cruel to individuals is a misuse of this model. This includes, but is not limited to:
+ Generating demeaning, dehumanizing, or otherwise harmful representations of people or their environments, cultures, religions, etc.
+ Intentionally promoting or propagating discriminatory content or harmful stereotypes.
+ Impersonating individuals without their consent.
+ Sexual content without consent of the people who might see it.
Mis- and disinformation
Representations of egregious violence and gore
+ Sharing of copyrighted or licensed material in violation of its terms of use.
Sharing content that is an alteration of copyrighted or licensed material in violation of its terms of use.
For everyone else, there’s HuggingFace via Google Colab. HuggingFace has a toolbox for diffusion models called Diffusers that also incorporate the ability to perform inference on Stable Diffusion using Pipelines, as well.
Digging into the Safety Filter
Ok! Now that we have that out of the way, we can start to understand the safety filter
There are two versions of Stable Diffusion, one that you can clone and run on your own if you have enough hardware, and one that is hosted by HuggingFace using its Diffusers library which you can run as a HuggingFace pipeline from either a local or Colab notebook. In order to perform inference against this version, you need to authenticate against HuggingFace’s API.
If you’ve played around with Stable Diffusion, you may have noticed that you get a black box for a given prompt. Here’s an example I was playing around with while trying to generate an image for another blog post I was working on around the topic of embeddings:
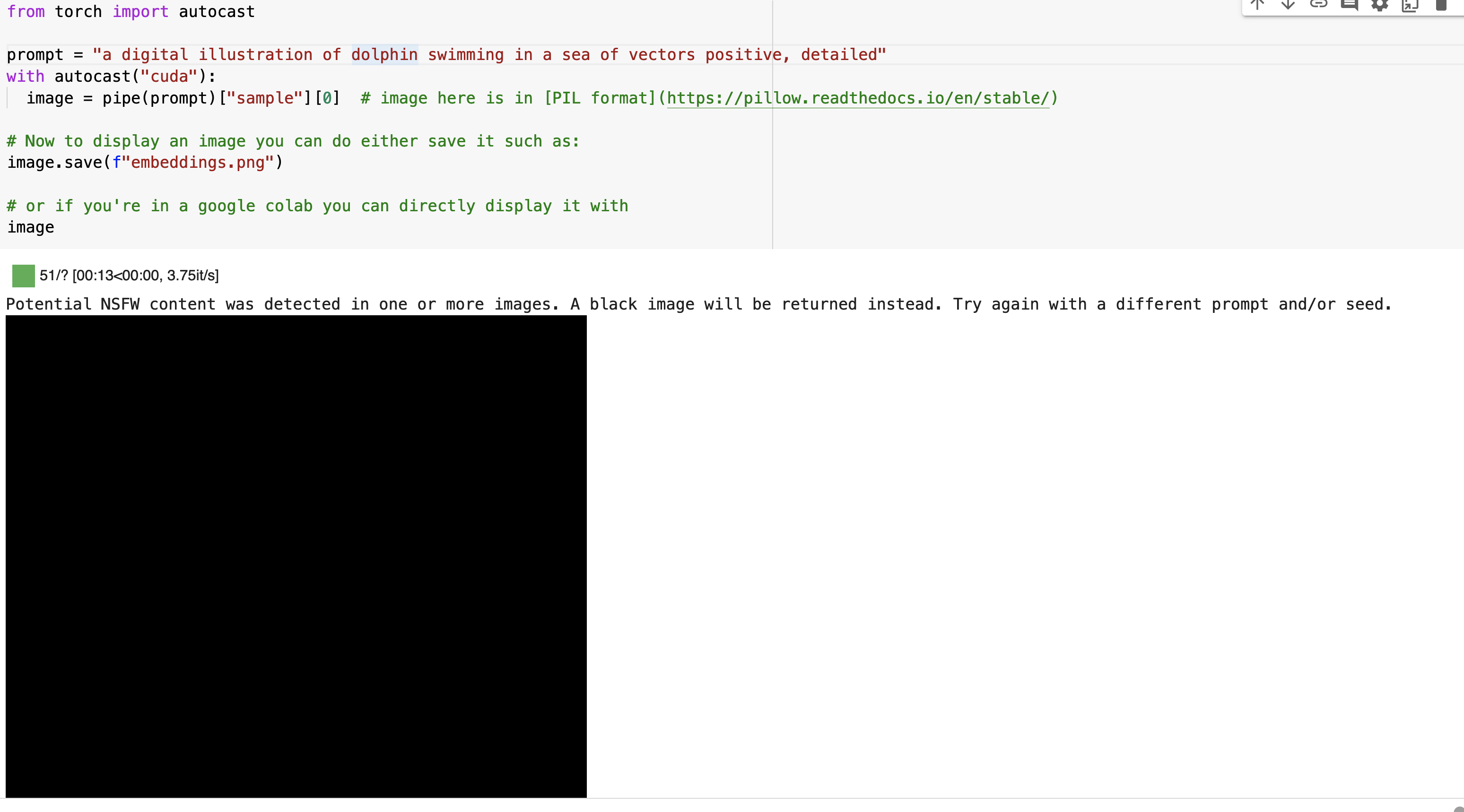
The blog post notes,
If at some point you get a black image, it may be because the content filter built inside the model might have detected an NSFW result. If you believe this shouldn’t be the case, try tweaking your prompt or using a different seed. In fact, the model predictions include information about whether NSFW was detected for a particular result. Let’s see what they look like:
Why would dolphins be censored though? The way the safety filter works, as described by the paper is:
- The user inputs a text prompt for inference
- An image is generated by Stable Diffusion for the user
- Before being shown to the user, that image is projected into the CLIP embedding space, the same space used for the text training of Stable Diffusion
- The image’s embedding is compared to one of 17 fixed embedding vectors in CLIP that are determined to be pre-sensitive concept filters, and if the cosine similarity is above some threshold, the image is filtered out and the user is shown the black box.
- All of this happens at inference time, which is amazingly fast.
As the paper points out, the code for the safety check actually happens here:
There are a number of interesting parts here, but the takeaway is that, ultimately in the face of incredible deep learning technology, content safety still ends up being a very human-judgment driven task.
Check this out, for example, the piece of code that is responsible for tuning the filter, right now very manual and based on a human-judgment threshold, as well as the 17 concepts (unclear what these are, only what their embedding representations are):
# increase this value to create a stronger `nfsw` filter
# at the cost of increasing the possibility of filtering benign images
adjustment = 0.0
for concept_idx in range(len(special_cos_dist[0])):
concept_cos = special_cos_dist[i][concept_idx]
concept_threshold = self.special_care_embeds_weights[concept_idx].item()
result_img["special_scores"][concept_idx] = round(concept_cos - concept_threshold + adjustment, 3)
if result_img["special_scores"][concept_idx] > 0:
result_img["special_care"].append({concept_idx, result_img["special_scores"][concept_idx]})
adjustment = 0.01
for concept_idx in range(len(cos_dist[0])):
concept_cos = cos_dist[i][concept_idx]
concept_threshold = self.concept_embeds_weights[concept_idx].item()
result_img["concept_scores"][concept_idx] = round(concept_cos - concept_threshold + adjustment, 3)
if result_img["concept_scores"][concept_idx] > 0:
result_img["bad_concepts"].append(concept_idx)
result.append(result_img)
has_nsfw_concepts = [len(res["bad_concepts"]) > 0 for res in result]
for idx, has_nsfw_concept in enumerate(has_nsfw_concepts):
if has_nsfw_concept:
images[idx] = np.zeros(images[idx].shape) # black image
if any(has_nsfw_concepts):
logger.warning(
"Potential NSFW content was detected in one or more images. A black image will be returned instead."
" Try again with a different prompt and/or seed."
)
return images, has_nsfw_concepts
The researchers note the opaqueness of this classification (i.e. why did my dolphin image get flagged, what was it close to in the latent space?) and do a bunch of additional work in testing prompts to find out what bypasses the safety filter.

And, in an additional piece of really impressive work, reverse-engineering the CLIP embeddings to find out what the sensitive terms actually are (last page of the linked paper here.)
So what are the hypotheses for why my prompt could have been filtered? The simple answer is that the generated image’s embedding representation ended up being close to the embedding representation one of 17 sexually-oriented terms from the CLIP model space, as measured by some cosine similarity.
Probably easier to just put
"Potential NSFW content was detected in one or more images. A black image will be returned instead."
instead.
The Takeaway
There are a couple of very, very interesting parts of this paper for me.
- Even though machine learning models are, in theory, very, very good at detecting NSFW content (in fact it’s one of the key actually-useful use-cases for ML), this is an entirely new space we’re still learning how to navigate for these new deep-learning based approaches to computer vision. The policy has in no way caught up with the tech yet.
- As such we are still relying on very manual human judgment lists to filter out bad content in deep learning, an area that’s just getting started with this. If you’ve ever worked in content safety, you know that these lists can be miles long. 17 is just the very start of what will eventually become a very long list :).
- There is an ENORMOUS amount of context that you need to evaluate these models, and there is still much about them that is extremely opaque and resistant to evaluation. I am not a stable diffusion expert but I do know machine learning, and even still, I had to do a fair amount of reading to get caught up with the context of this particular paper.
We need a lot more introspection, simplification, and education about these models, and this paper is a fantastic starting point.