What should you use ChatGPT for?
I work in machine learning and read about it a lot, but ChatGPT still feels like it came out of nowhere.
So I’ve been trying to understand the hype. I’m interested in what its impact is on the ML systems I’ll be building over the next ten years. And, as a writer and Extremely Online Person, I’m thinking about how it could change how I create and navigate content online.
From the outset, it’s clear that both ChatGPT and other generative AI tools like Copilot and Stable Diffusion are already having short-term impact. First, generative AI is already being used to spam reams of trash fictional content into magazine submissions systems. and artist platforms are reacting in turn.
From the producer side, everyone is thinking about how to incorporate generative AI either as a product offering, or a way to sell their data
From the point of view of content on the internet, what we’re going to have is a hollowing out of the internet into an extreme bimodal distribution, even worse than it is now with the amount of SEO spam Google encourages. There will be a mountain of AI trash at the bottom and creators and real humans scrambling to the sliver of internet that is not covered in regurgitating Wikipedia and DeviantArt.
Second, it’s already changing the ways that professors are thinking about teaching.
What are some ways that individuals are using it? I’ve read posts about people using it to learn how to code in a new language, act as a Linux terminal, debug code, for disputing parking tickets, and write essays.
However, even after reading these use-cases I as both a writer and engineer, was at a loss to what I personally could use it for.
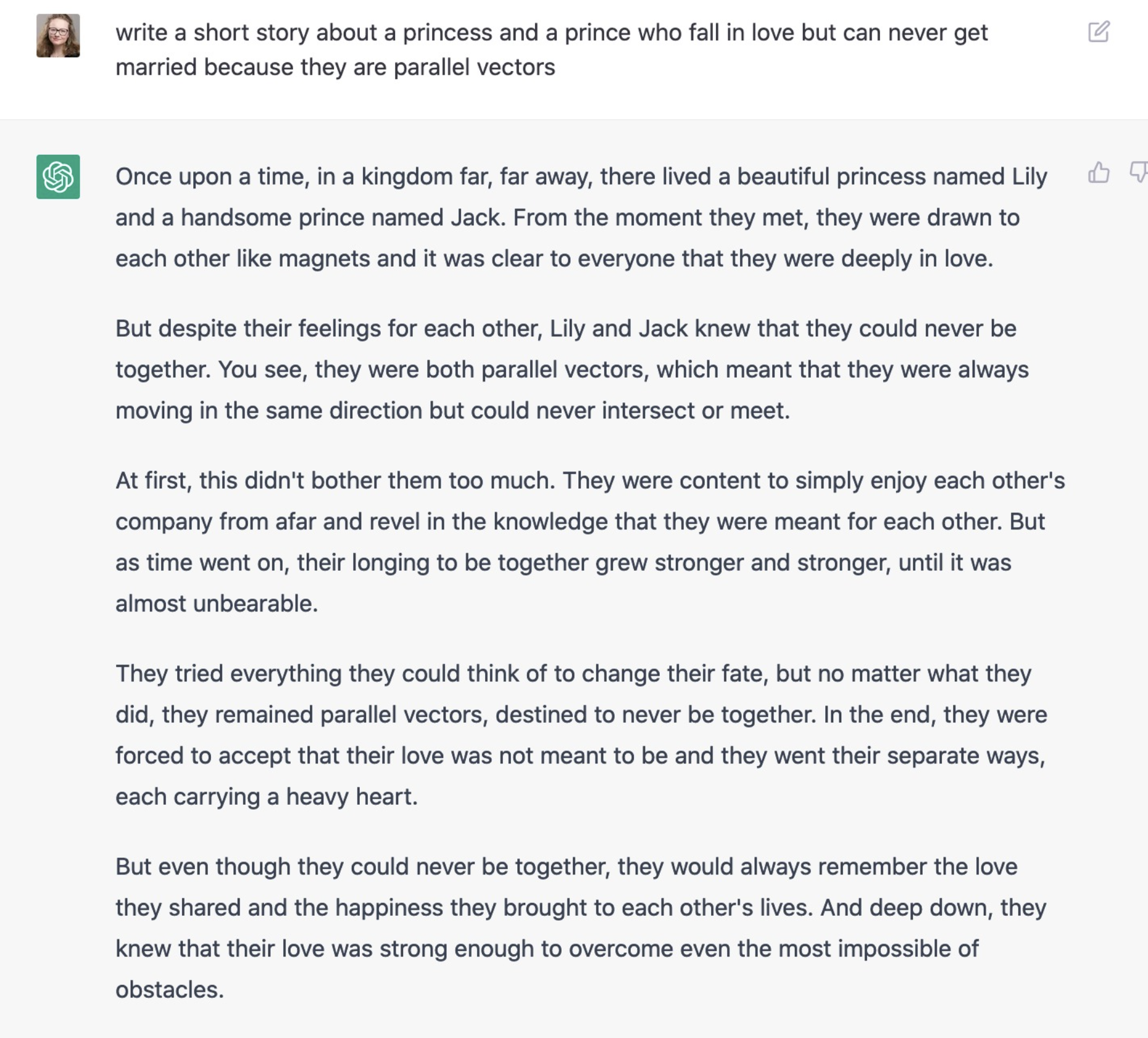
For creative endeavors, I never want to have something else come up with my writing. The holistic labor of creative writing is struggling to succinctly translate your own experiences and ideas from your mental space to the physical realm. My ideas and the ways I express them in text are the most precious things I have, the ones that differentiate me from everyone else. Moreover, in the process of generating the written form of your ideas, you come up with different ways of thinking about them.
In writing, the process is part of the product. Even in drafting this post, I initially started in a completely different direction and it was only clear to me after I was halfway through that the post would have to go in a different direction.
So I’m against the idea of using it for generating creative work. The additional effect of using it to write is that I’ve noticed I can now start to tell when someone is publishing something that has been generated with ChatGPT: it has a very flat, fact-based affect, without any personality whatsoever.
I did have some fun with it, but I wasn’t sure how I could use these snippets at all.
For technical work, I very skeptically read “The End of Programming” and tried to see if I could be convinced that ChatGPT could help me write code.
I started simple and found that it very quickly provided wrong answers to even fundamental questions.
For example, I asked it to answer a basic Python question, which it failed on due to syntax:
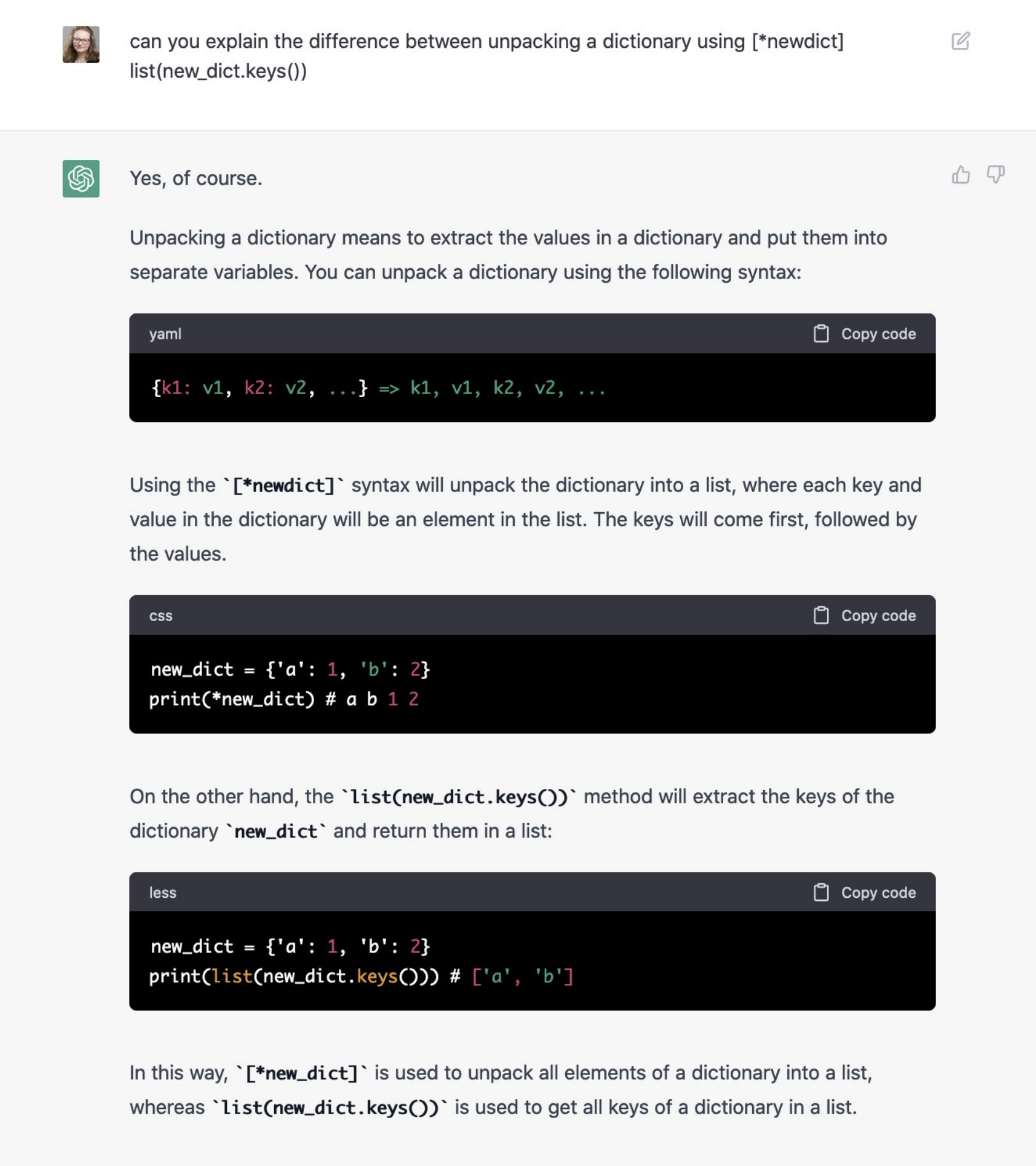
The correct answer from my terminal:
new_dict = {'a':1, 'b':2}
print([*new_dict])
['a', 'b']
print(list(new_dict.keys()))
['a', 'b']
You’ll also notice it annotates the languages incorrectly in the code headers.
I also asked it to reason about why some code to return the longest common prefix from a list of terms didn’t return correctly, and it missed the return statement in the else branch.

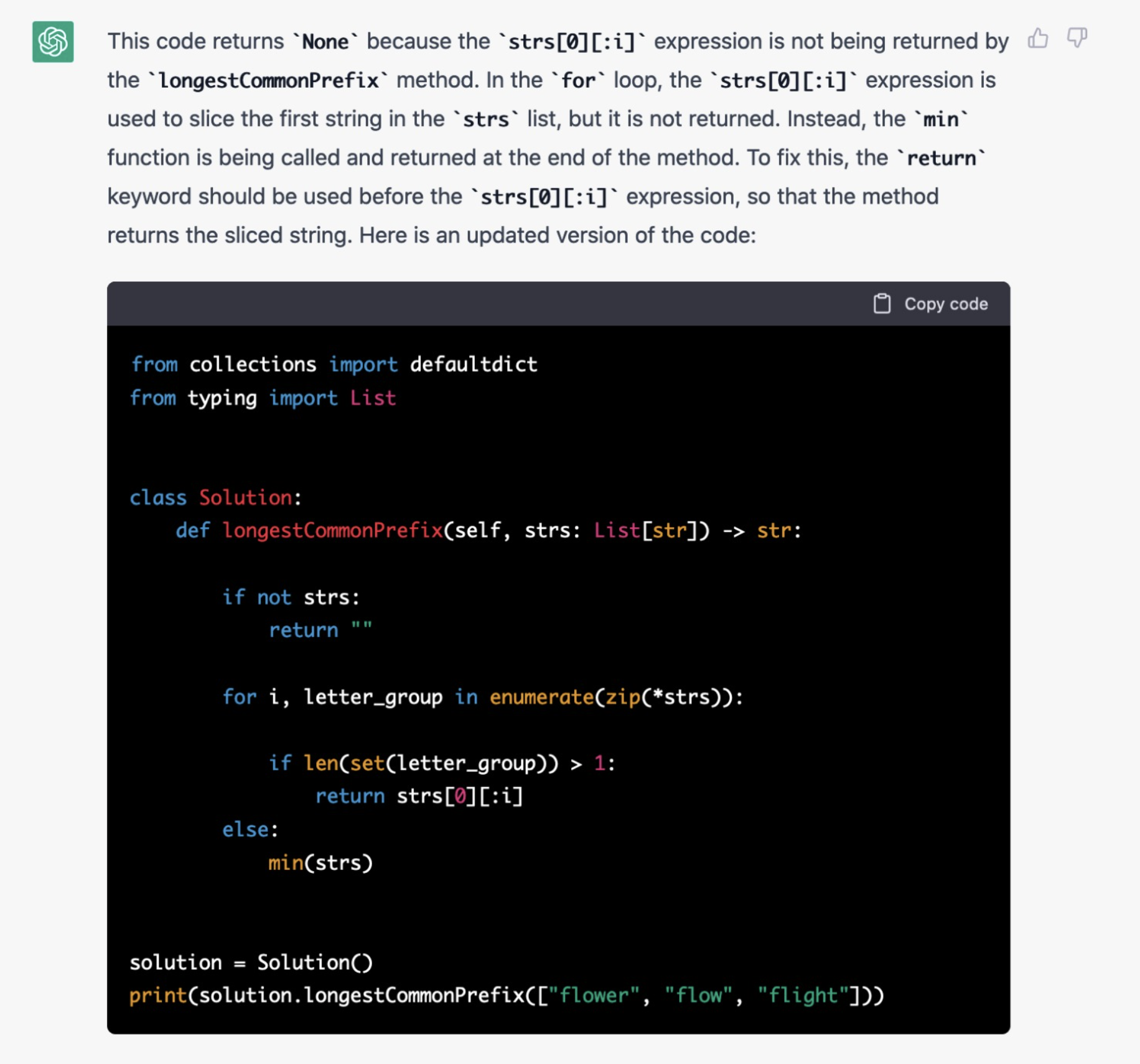
Here’s the correct solution:
from collections import defaultdict
from typing import List
class Solution:
def longestCommonPrefix(self, strs: List[str]) -> str:
if not strs:
return ""
for i, letter_group in enumerate(zip(*strs)):
if len(set(letter_group)) > 1:
return strs[0][:i]
else:
return min(strs)
solution = Solution()
print(solution.longestCommonPrefix(["flower", "flow", "flight"]))
The trick here, is that, of course in both cases, I knew the answer ahead of time and could confirm it based on my experience. If you’re learning something new, you either have to trust that ChatGPT knows what you want, or cross-reference other sources, in which case you’re performing a search anyway.
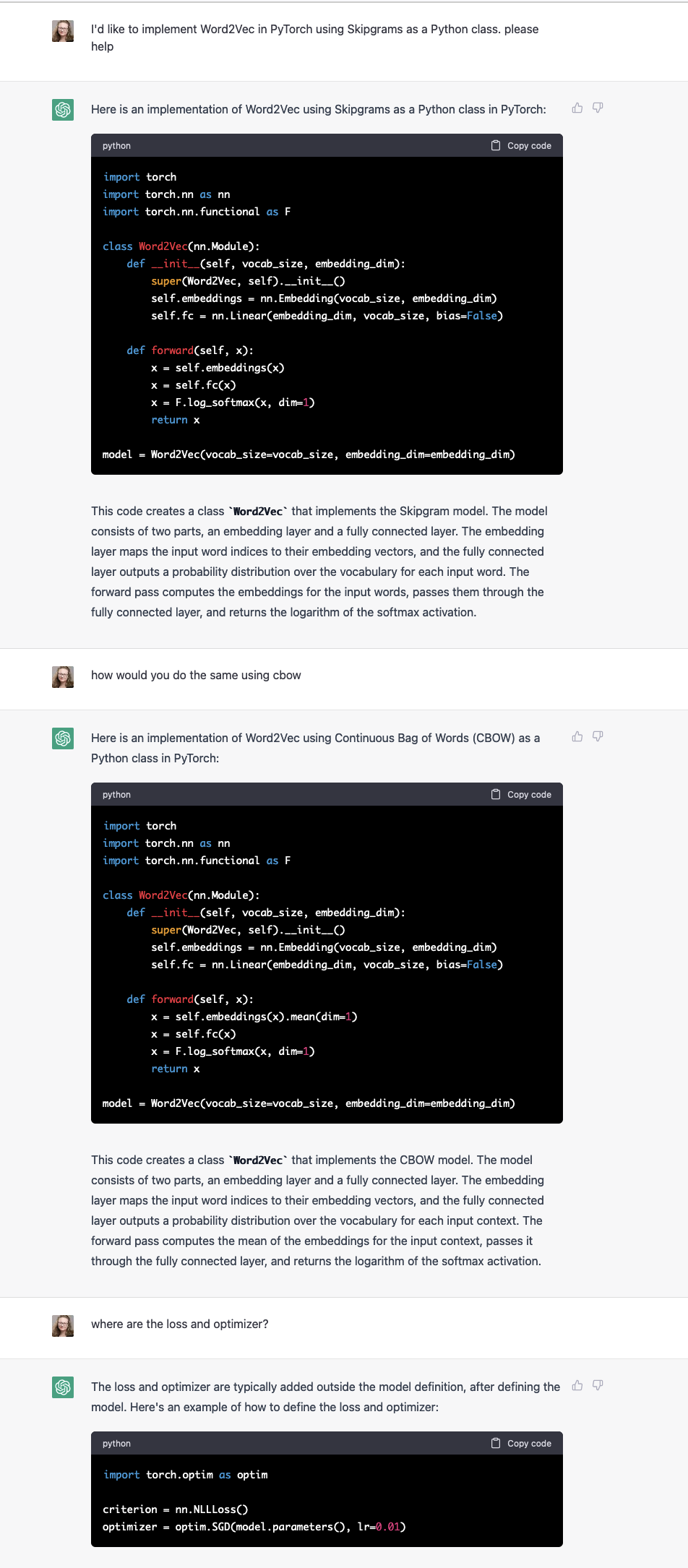
Here is another example where not knowing something would not have helped. I am looking to implementa CBOW version of Word2Vec in PyTorch, and there are no canonical examples online, and the instructions are not as detailed in PyTorch as in Tensorflow, and in fact CBOW is left as an exercise for the reader to implement.
Coming in as a relative newcomer to PyTorch, I thought this was something ChatGPT could do, and it turns out that, again, ChatGPT will get you most of the way there, but you have to draw the rest of the owl yourself.
While I was working through these cases as part of day-to-day work, I realized something important: ChatGPT is not good at giving you concrete answers and should never be used the same way a search engine would. It will inspire you, but it will not get you across the finish line.
ChatGPT basically runs on statistical vibes.
The reason why is laid out very clearly in this fantastic paper, “Talking about large language models.”
LMs are generative mathematical models of the statistical distribution of tokens in the vast public corpus of human-generated text, where the tokens in question include words, parts of words, or individual characters including punctuation marks. They are generative because we can sample from them, which means we can ask them questions. But the questions are of the following very specific kind. “Here’s a fragment of text. Tell me how this fragment might go on. According to your model of the statistics of human language, what words are likely to come next?
ChatGPT, because it was scraped from the entirety of the internet, can do a lot, but it is not very good at it and the results, although they are getting better, are noisy.
However, whatever it generates first, before you re-direct the prompt, is a good starting point for where you want to go next, especially if you can’t think of anything, or are starting from cold-start, either in terms of data, ideas, or code.
Another thing these exercises made me realize is that I had been treating ChatGPT the way I’ve been conditioned to treat the other big text input box in my life: the search box.
In search, we have a user and a single query. The expectation is that the system returns the correct result to the user every time, and the scoring function (usually driven by machine learning) correctly ranks and guesses the results you want.
I initially compared and contrasted the two by thinking that, in search, my results were always exact and accurate after one query, whereas with generative AI, they were not.
But it turns out I as a user had two misconceptions. The first is that ChatGPT works best when you iterate on the results. The second is that, even in traditional search, we end up needing to fine-tune our queries. Marcia Bates, a prominent information retrieval researcher, wrote a very important paper that described the search user experience as one that involves berry-picking:
Furthermore, at each stage, with each different conception of the query, the user may identify useful information and references. In other words, the query is satisfied not by a single final retrieved set, but by a series of selections of individual references and bits of information at each stage of the ever-modifying search. A bit-at-a-time retrieval of this sort is here called berrypicking. This term is used by analogy to picking huckleberries or blueberries in the forest. The berries are scattered on the bushes; they do not come in bunches. One must pick them one at a time. One could do berrypicking of information without the search need itself changing (evolving), but in this article the attention is given to searches that combine both of these features.
This is really important, because it turns out that the ML systems we were conditioned on for the past twenty-five years are also just faulty, and even more so lately, we just have learned how to navigate around them and to mitigate information loss.
ChatGPT and its ilk are still brand new and we are just starting to grasp around its edges to understand its its limitations and impact.
So, for myself, my rules for engaging with ChatGPT are to give it small, inconsequential things it can iterate well on and that I have the ability to check:
- Give it tasks that I know I will be checking manually anyway and for those tasks to be easy to introspect
- Use it for bootstrapping research for technical topics that I will eventually be rewriting anyway (I did not use it for research or to write this post, though)
- Always assume that its first results will not be the final answer to whatever I need and that the amount of refinement I end up doing will likely result in more manual work anyway.
A perfect use case for this criteria I’ve found recently is generating charts in LaTeX. I’m currently in the process of writing a machine learning paper in LaTeX and found that I wanted to translate a blurry crop of Chollet’s machine learning rules into one that was rendered correctly in my document:
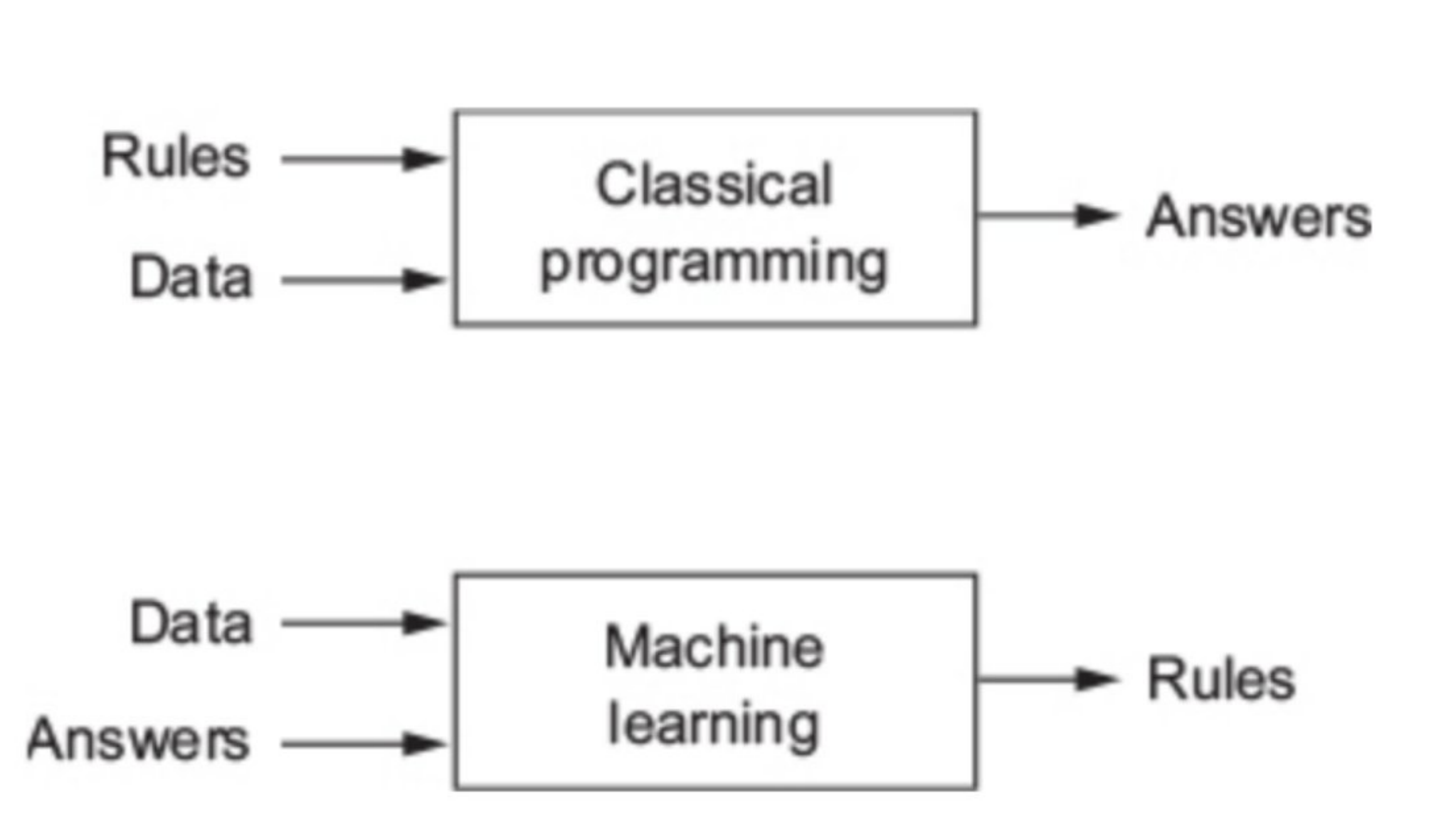
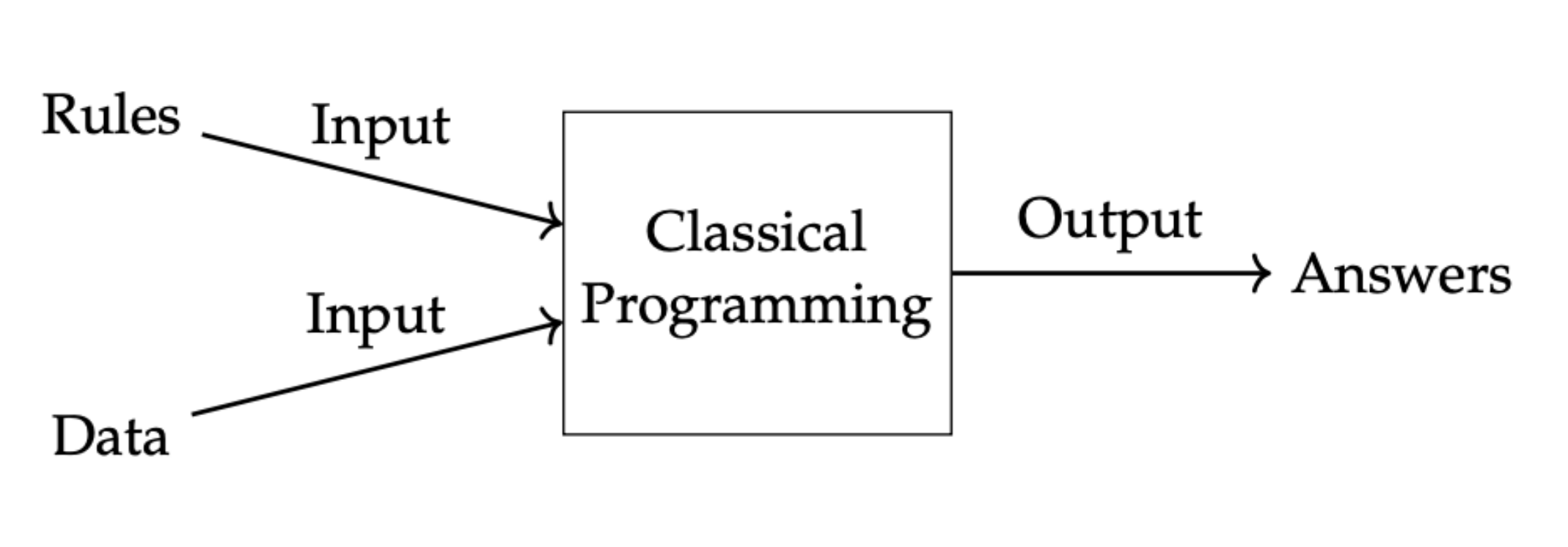
After going back and forth with it a bit to generate the entire diagram, I got:
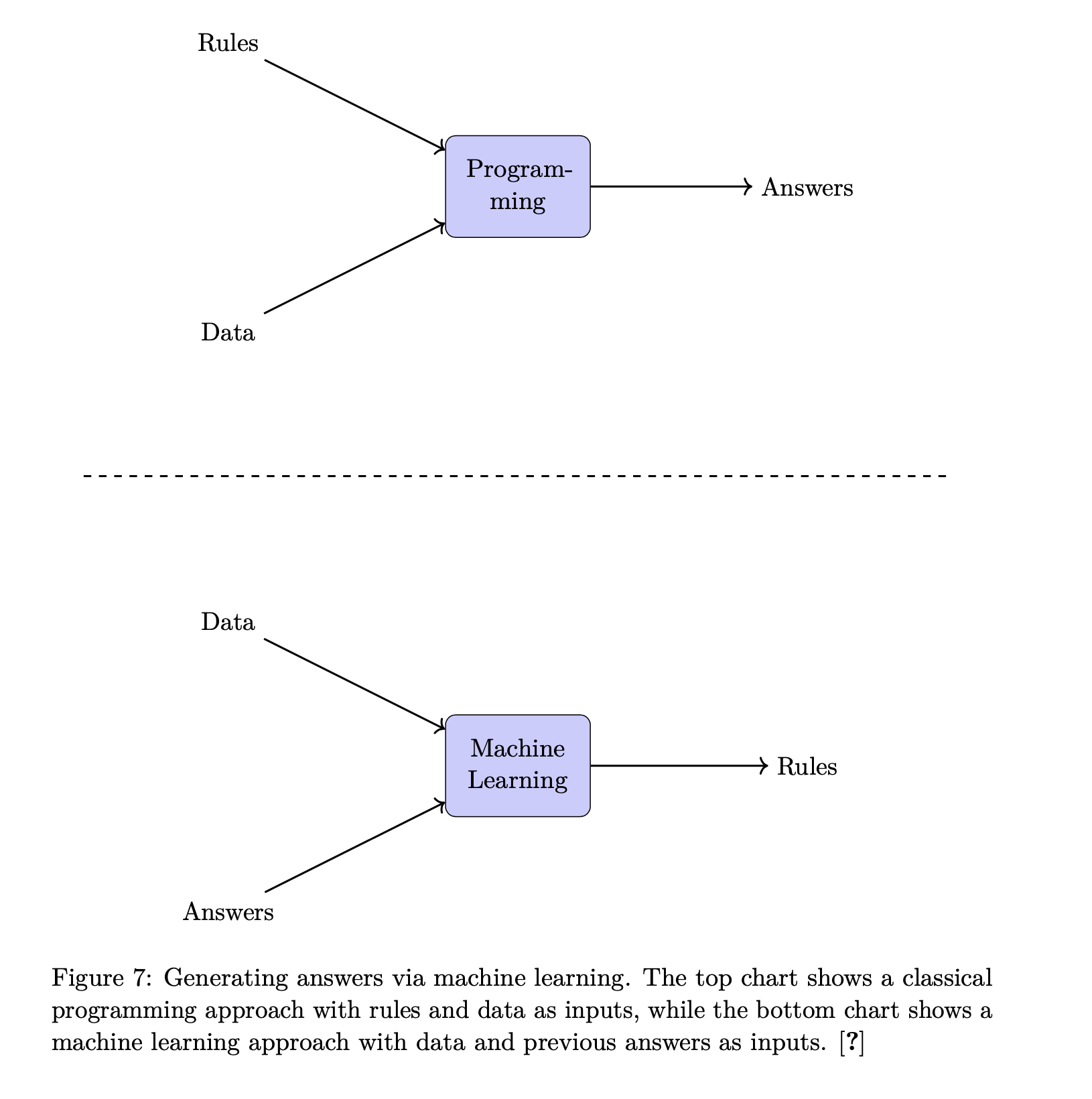
Note the caption here: you still have to watch very, very carefully because I didn’t mean for it to write about “previous” inputs, the two charts have nothing to do with each other.
Some other good use-cases people have found in the programming space include generating training data gold sets for use in downstream models, which works great because you don’t have to check the validity of the fake data, writing and checking regex and crontabs, formatting tables into Markdown (or from Markdown into different formats), and hundreds of other small tasks that make developer life less miserable.
Whether any of this continues to hold true depend on the model updates the researchers make to ChatGPT, as well as how it becomes implemented. Will it be available to individual users in a free tier, or will it eventually be gated for everyone? Will it be part of Microsoft’s Azure API and OpenAI’s API, meaning that its power is now limited to developers? Will it all be locked away at big companies through consulting engagements with Bain?
All of this remains to be seen and if you read this post a month from now, the facts might have radically shifted - the examples I originally intended as “things that ChatGPT got wrong” seem to have actually been fixed.
What is clear to me is that we are in a new paradigm for the way we navigate content, whether through this model or other ones that are released soon. Upon prompting, the new universe gives us results, but those results are more directional vibes than concrete answers. It is up to us to figure out how to direct them in ways that we want for the best results and navigate the noise.