What we don't talk about when we talk about building AI apps
Every day I open my LinkedIn and Twitter (and Mastodon and Bluesky and Threads….) and am innundated with the same messages: LLMs are sent to us from above, they make everyone’s life easier, we are quantizing and pruning, going faster, getting smaller, they will change education, they will write our poetry, they will outlive us all and overthrow humanity and build a happy fruitful LLM robot society, generating art and text, a society where humans exist solely to bring them cyberdrinks with small digital umbrellas.
I am currently building a semantic search application, that doesn’t use OpenAI, but uses the same architectural patterns as most vector search applications - a query tower that encodes text to embeddings and does KNN lookup against a model with pre-encoded vectors, returning the top semantically similar results by cosine similarity using BERT sentence transformers.
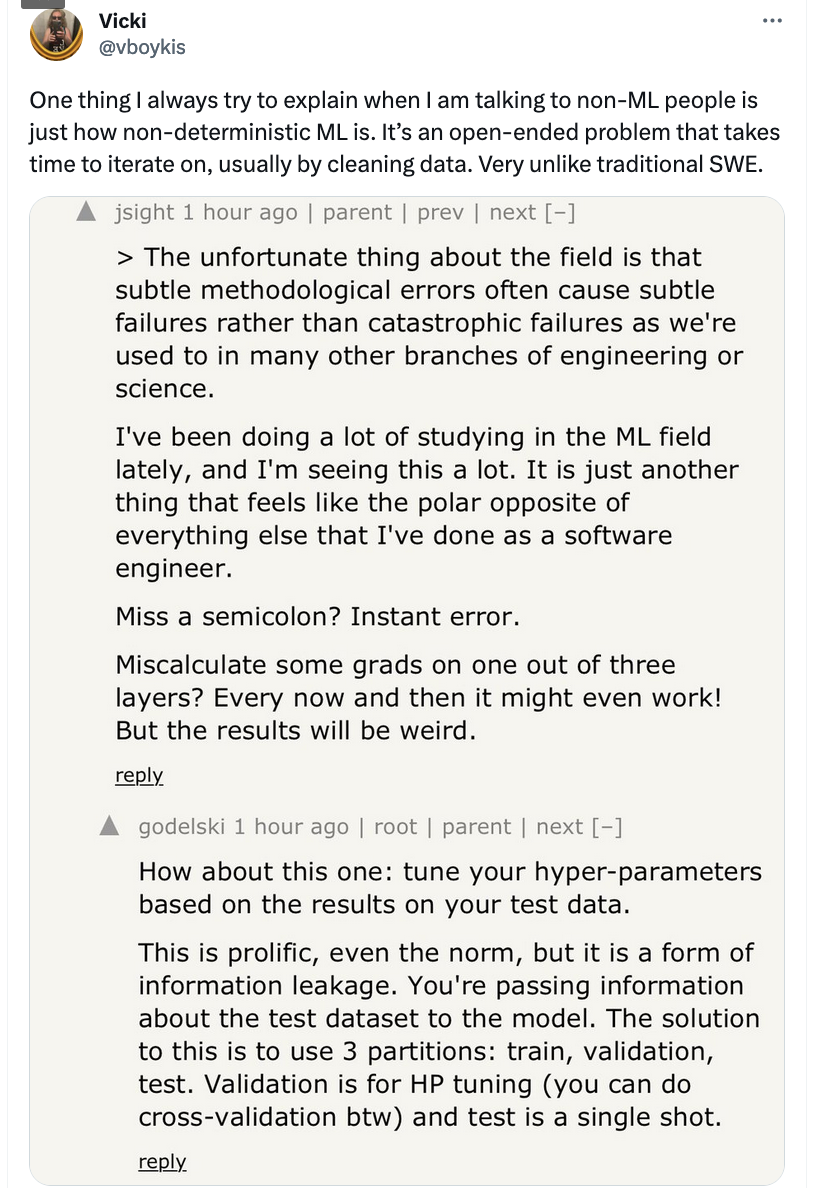
From the technical perspective, here’s what we don’t discuss when we talk about deep learning applications. Or, more specifically, here are pain points I’ve come across that I don’t see being discussed a lot - if you are developing deep learning apps and don’t have any of these issues, let me know which god you offered a sacrifice to in the woods under the pale light of the waning crescent:
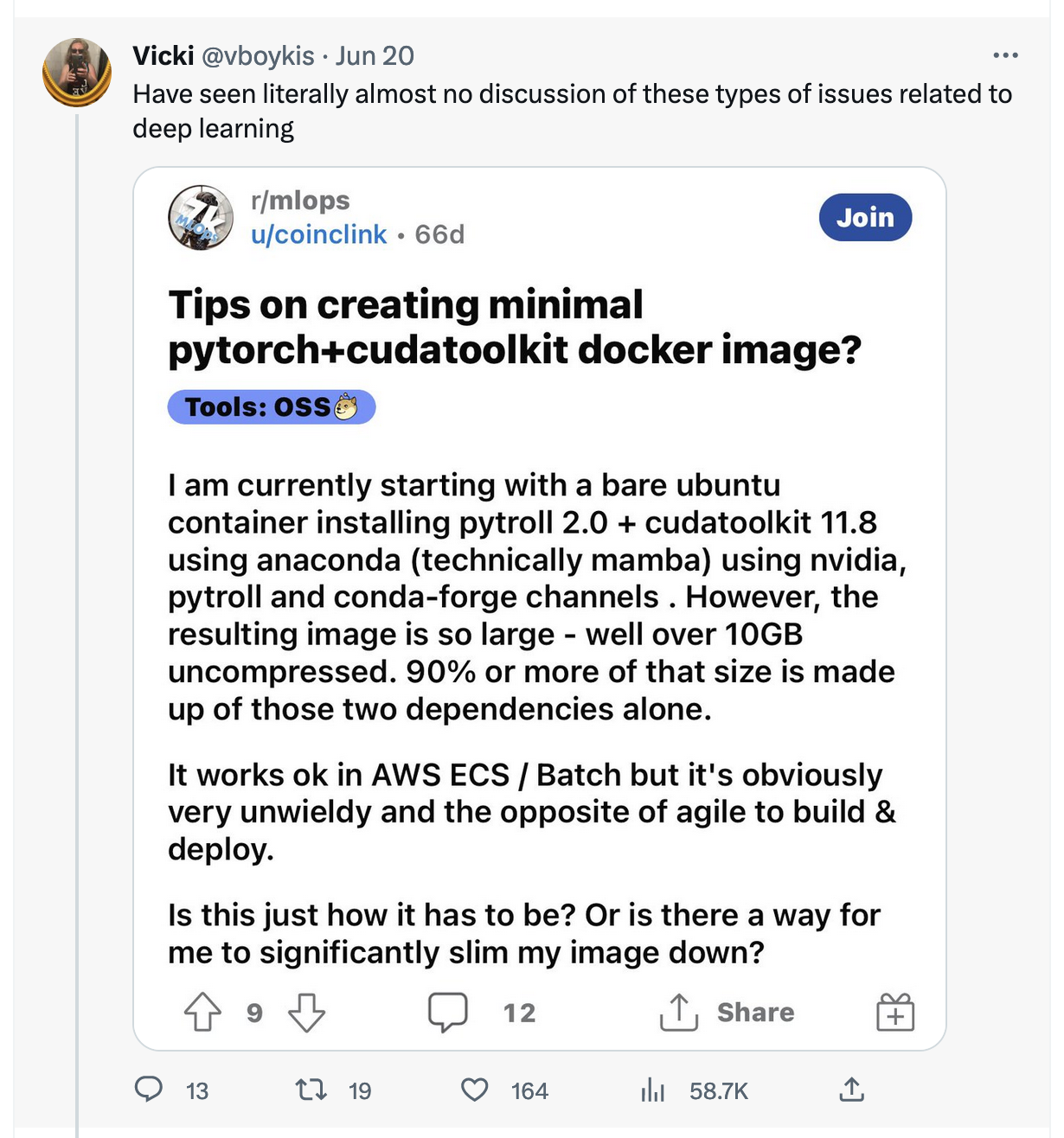
Docker images for anything involving deep learning with GPUs are enormous, sometimes as big as 10GB..
People spend an inordinate amount of time engineering these Docker images to work correctly in the cloud and on production environments
These same images take forever to start on CI runners and as a result increase the iteration time of deep learning work, which is already very handwavey and as a result needs to be iterative
The amount you need to learn about CPUs/GPUs is not insignificant and takes a long time on top of all the general MLE concerns: good modeling, ML architecture, data engineering, distributed systems, statistics, and monitoring.
If you are doing anything where you embed vectors in an n-dimensional dense space, you need to be mindful that the model you encode with and the model you run inference on have the same vector size. This might seem like a ridiculously obvious observation at first, but I’ve now seen an entire category of silent failures because the query and lookup reference vector were not exactly the same size. It’s equally important that the query and corpus vectors are encoded with the same model so that embedding lookup happens in the same embedding space, otherwise the results won’t make sense.
Model artifact storage and versioning takes forever, even if you’re using tooling. It’s a pain to move around 5GB parquet files. This of course becomes easier once you have an ML platform and is exactly the reason many feature and model stores were developed but dealing with model artifacts generally is very clunky, particularly since we generally don’t version control them.
The speed with which anything in the deep learning ecosystem evolves, particularly in libraries like HuggingFace, combined with how hard it is to create reproducible Python environments when versions don’t align leads to a special kind of dependency hell that sometimes ensures the only good way to have a reproducible version of an environment is to freeze it in a docker image. I can’t find the tweet anymore, but this is exactly what I saw someone suggest to do for academic papers published with Python so they remained reproducible long after the packages were no longer maintained.
When it works it’s fantastic. But I just got an M2 machine which I thought I might be able to run encoding on to avoid spinning up AWS images and giving Jeff money, but everything broke because of the movement to arm64 architectures. For example, MKL, which I need for ONNX with Transformers Optum is Intel-only.
If I do somehow get it to work, I’ll need to develop two Docker images now: one for local development and one for my staging server that runs on DigitalOcean, which means more GitHub actions. And you can’t test GitHub actions locally, anyway. Maybe kind of? But not entirely.
I don’t think I’m alone here. My project is just a small hobby project, but the normcore problems of neural nets and LLMs in production are a whole genre of issues that are not getting coverage proportional to what people are actually experiencing. Just take a look at this logbook of researchers training an LLM, OPT-175 at Meta, which reads like a thriller.
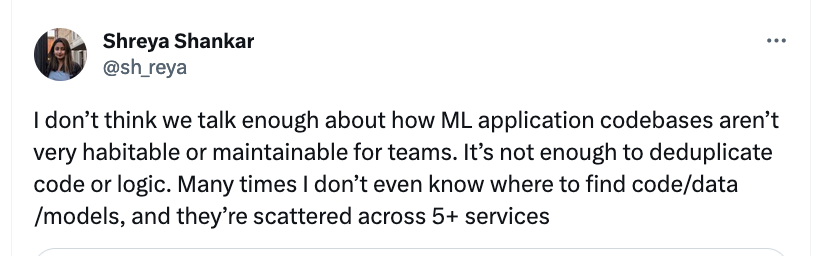
This also doesn’t include any of the traditional, normcore concerns of machine learning in production: concept drift, SLAs for large services, working with Kubernetes, guarantees of distributed systems, and YAML config file drift. Finally, we haven’t talked at all about the UI involved for users navigating search bars and text boxes, which I’ve spent just as much time thinking about as the model itself.
I am not blaming anyone who develops in the ecosystem for these problems. Everyone is working with a very deep and cloudy stack and doing the best they can, particularly in the pressure cooker environment of open-source ML tooling that has only accelerated since the release of ChatGPT.
But I think it’s important to talk about these issues publicly - they are not sexy and they are not LinkedIn-worthy, but these are the problems that make up our days and our lives on the bleeding edge.