Build and keep your context window
This is the keynote I prepared for PyData Amsterdam 2023. The TL;DR is that we must understand the historical context of our engineering decisions if we are to be successful in this brave new LLM world.
The text here isn’t exactly what I said, it was my notes ahead of time. My slide template is by Barbara Asboth, who also did the templates for Normconf.
Video:

Good morning PyData Amsterdam! An enormous thank you to the organizers, the sponsors, to PyData, and to you, the attendees, for coming! It’s wonderful to be able to see everyone in person again. This talk is about building and defending our context windows.

I’m Vicki, and I’m a machine learning platform engineer at Duo Security. You might know me from previous hits like the Normcore Tech, the newsletter, NormConf, the conference about totally boring problems in machine learning, What are Embeddings, a paper about weird numbers, and Viberary, a semantic search engine that surfaces books to read based on vibe.
I also used to make bad jokes on Twitter and do #devart, and you’ll see some of that here.
Today though, I want to talk to you about something I’ve been worried about over the past year. As someone who is Eastern European and works on ML infra, there are a number of things I’m worried about at any given time. Data drift,unpinned dependencies, service uptime alerts, red CI/CD builds, NaNs, and cell execution order in notebooks and whether I left GPUs instances running overnight.

But I have something I’m worried about even more than all these things: I’m worried that, in data land, we have forgotten how to deal with the two fundamental problems of computer engineering. You might know them already: Cache invalidation and naming things.
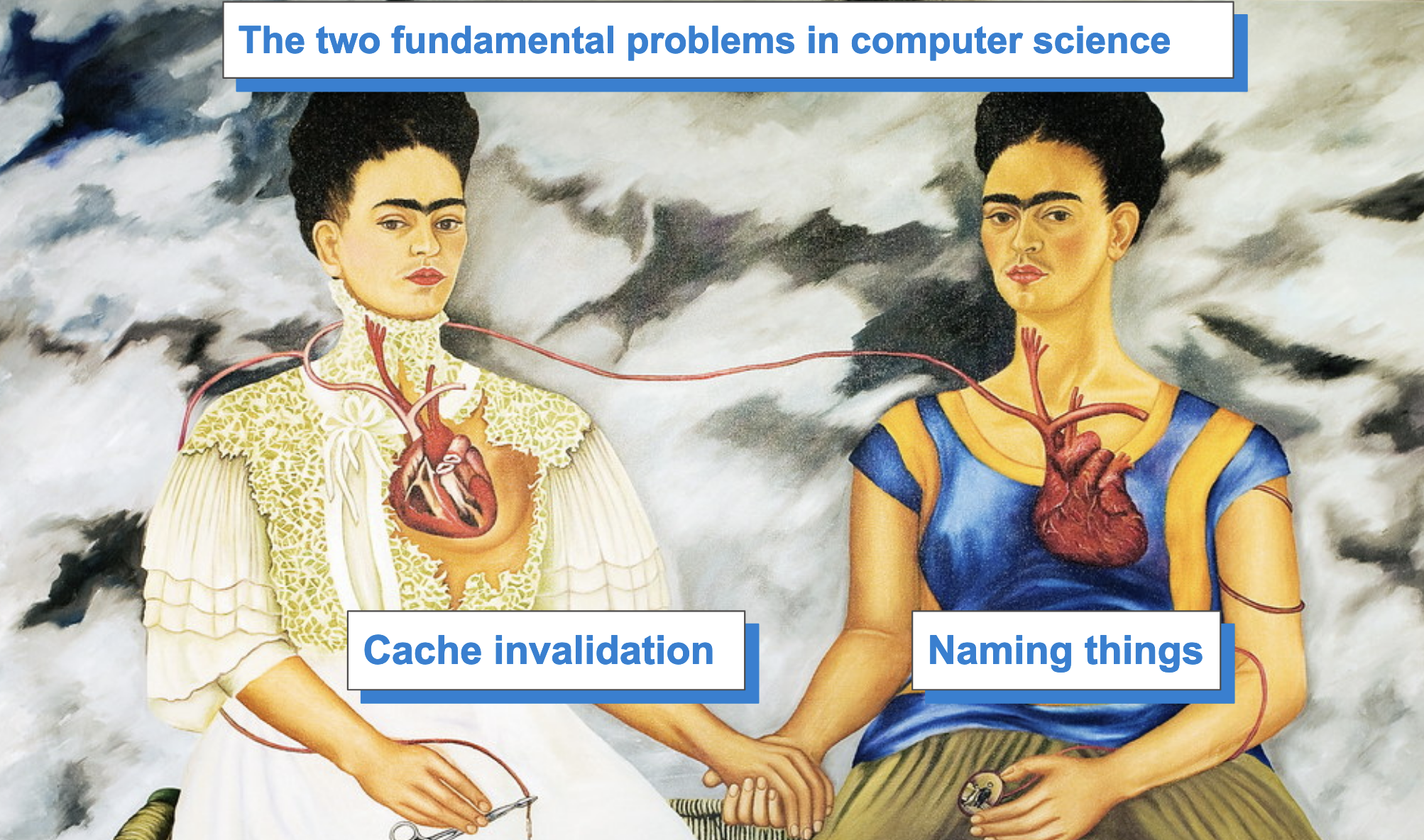
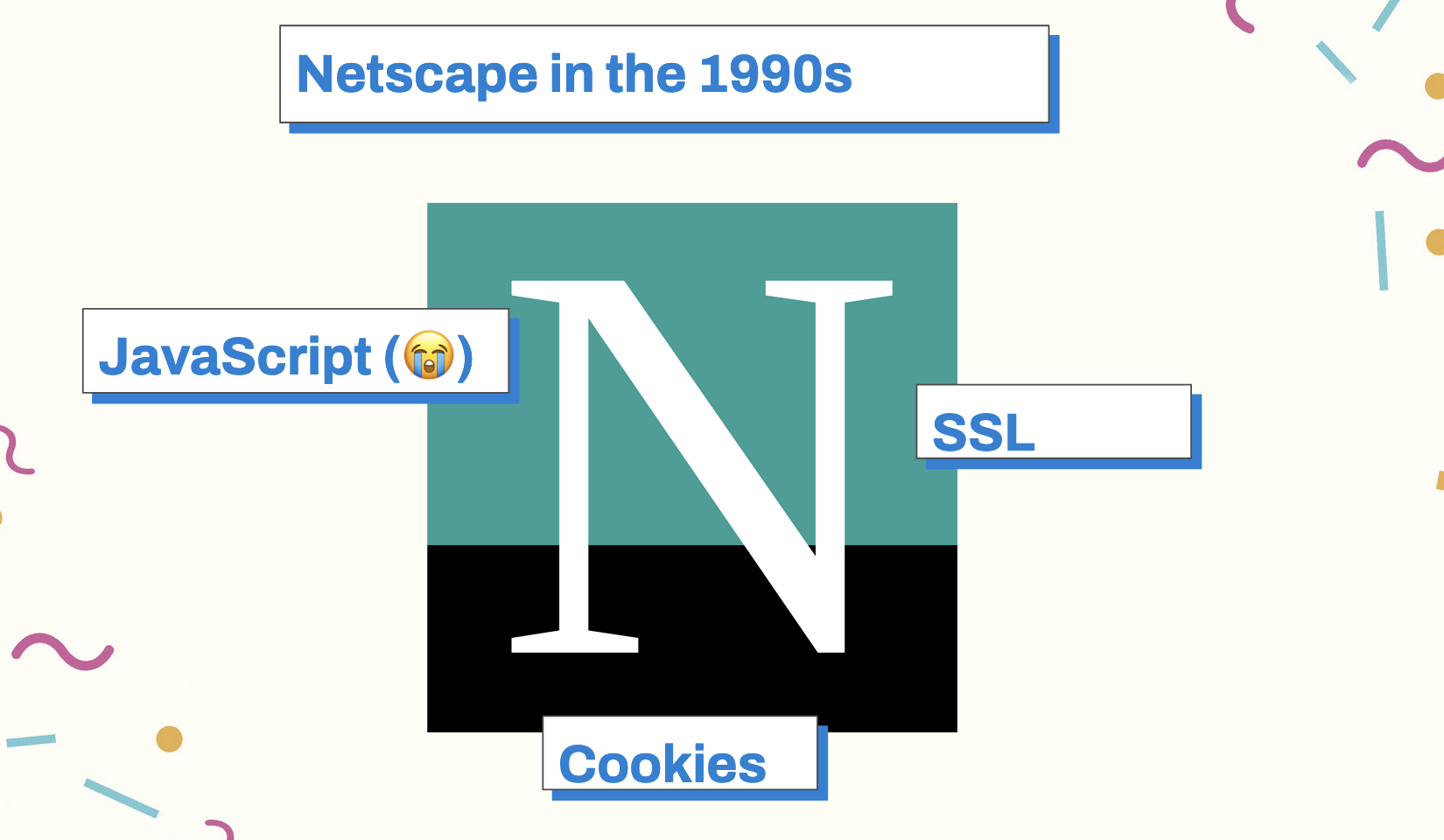
This joke concept was originally coined by Phil Karlton, a computer scientist at Netscape, in the 1990s.

A lot of important ideas that came out of Netscape at the time that shape the way we use the Internet today: JavaScript the language (unfortunately), HTTP cookies, and SSL. Karlton was responsible for architecture at Netscape, the browser.
Why are we taking a side track into early 1990s internet history? Because history is context and context is power. After all, machine learning, as Russell and Norvig write in Artificial Intelligence: A Modern Approach is the art of extrapolating patterns based on past data. And are we, humans not the initial thinking and learning machines?


Without past context, we cannot make valuable inferences about the future. We cannot train our own mental model. And training our own internal machine is just as, if not even more important than the models and data we work with.
In computer science, like in all other disciplines, ideas don’t live in isolation. They are recycled, reused and repurposed constantly, and the more we understand about where they came from, the more we can benefit from the richness of hundreds of years of past human experience to master our current tools and ecosystems.
Two Piranesis
To understand what we lose when we lose context, I want to talk about the two Piranesis.

The first Piranesi is a character from a fantasy book by Susanna Clarke, about an unnamed man who is lost in a remote, but semi-familiar world. The unnamed narrator lives in what seems to be an enormous palace. The house he describes is infinite, has hundreds of corridors and levels and halls of statues, and ceaseless rushing waters that flood different corridors and carry away the narrator’s few belongings.

We learn both through his internal monologue and diary entries that he uses to meticulously track and diagram the neverending halls of the house and its movements, that he feels he has always lived alone in the house. There are no other humans, only sea birds and fish, and the ceaseless tides at the lower levels of the house keep him company.
One of his most notable activities is looking at the statues, of which there are infinitely many in the house, many of which are allusions to classical statues or to books like Narnia, which he doesn’t understand. He lives unmoored, at the mercy of the house.

There is one other person, a well-dressed man who comes every so often to give the unnamed narrator clues about the house. We gradually learn that the narrator, in reality, has suffered from enormous memory loss, which is why he has no idea of where he is in the house or how he can get out, and also why he doesn’t recognize anything from the world we know. The man who observes the unnamed narrator, The Other calls him, jokingly, Piranesi.

This is not explained in the book, but the allusion of “Piranesi” is to the second Piranesi, the Venetian artist,sculptor, and archaeologist, Giovanni Battista Piranesi, who drew imagined landscapes of grandiose prisons in the style of Greco-Roman civilization.
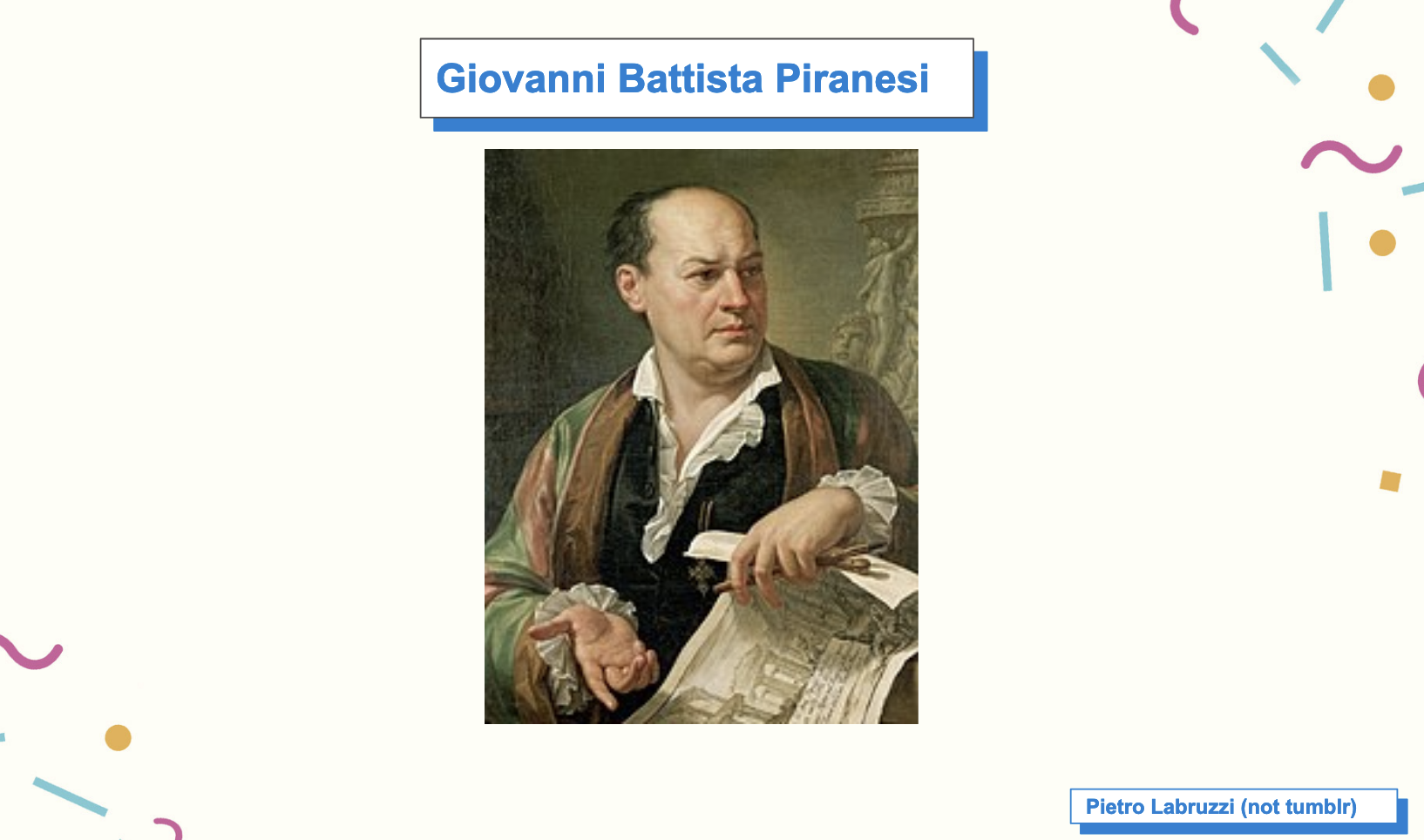
Piranesi was born in The republic of Venice in 1720 and introduced to Latin literature by his brother Andrea. He worked with his uncle in the Magistrato delle Acque, the organization responsible for restoring historic buildings. He went on to Rome to study under classical Italian engravers.
While he was studying and sketching views of the city of Rome, he was very precisely measuring all of the antique buildings in the city, which led to the publication of his book, “Roman Antiquities of the Time of the First Republic and the First Emperors.”

He fell in love with classical structures and styles and always longed for a return to Roman engineering principles. Some of his most lasting contributions are his sketches of imaginary prisons and monuments of the greatness of the Roman empire, things that could never be built in reality, but look like they could have been. He spent a great deal of time studying classical Rome to recreate these architectural elements as they should have been.

In completing these drawings, he preserved a sense of respect and love for the classical style of architecture. In addition to these, he also meticulously documented past Roman monuments, which were, at the time, mostly abandoned.
Because he had a strong foundation in the past, he was able to stand on that past and build beautiful new things, and, additionally, preserve the past for even us today to study. He wrote,

These skills in perserving real buildings then led him to be able to riff on the classics and create his famous series of Carceri, imaginary prisons, which is what The Other alluded to.


What do Piranesi the book, and Piranesi the archaeologist and artist have to do with the way we do engineering in the data space today? They both revolve around the concept of the importance of keeping historical memory of context.

In Piranesi the book, the narrator was initially helpless without his memory, swayed by the tides in the house and at its whims and mercies. The only thing that saved him was his diary that he kept and found old pages which allowed him to understand what actually happened. The diary rooted him to the past and allowed him to move both freely around the house, and to, eventually, leave it.
Our second Piranesi would have not been able to create beautiful, haunting new works, without carefully studying the past and bringing that context forward both for himself and, later, to us to examine and remix on.
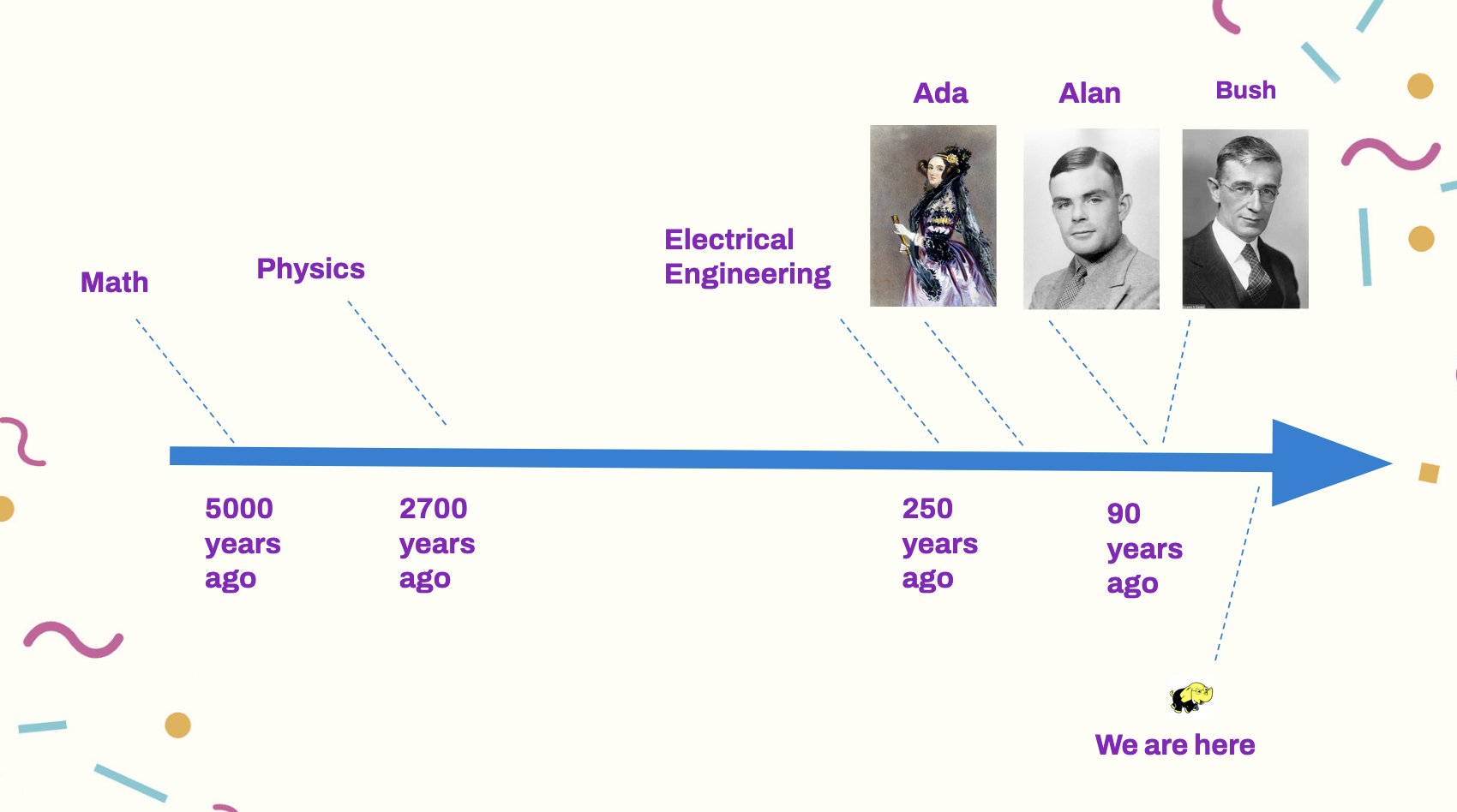
What do either of these Piranesis have to do with the two fundamental problems of computer science? Industrial software engineering is still a brand new field compared to hard sciences like math and physics - thousands of years old, and electrical engineering is 250 years old at most . Depending on how we define it, software engineering as a discipline has only been around since Ada Lovelace built the first computer. Alan Turing, the father of computer logic and Vannevar Bush, one of the fathers of information retrieval, only worked in the 1940s. The first internet connection only happened in the 1970s.
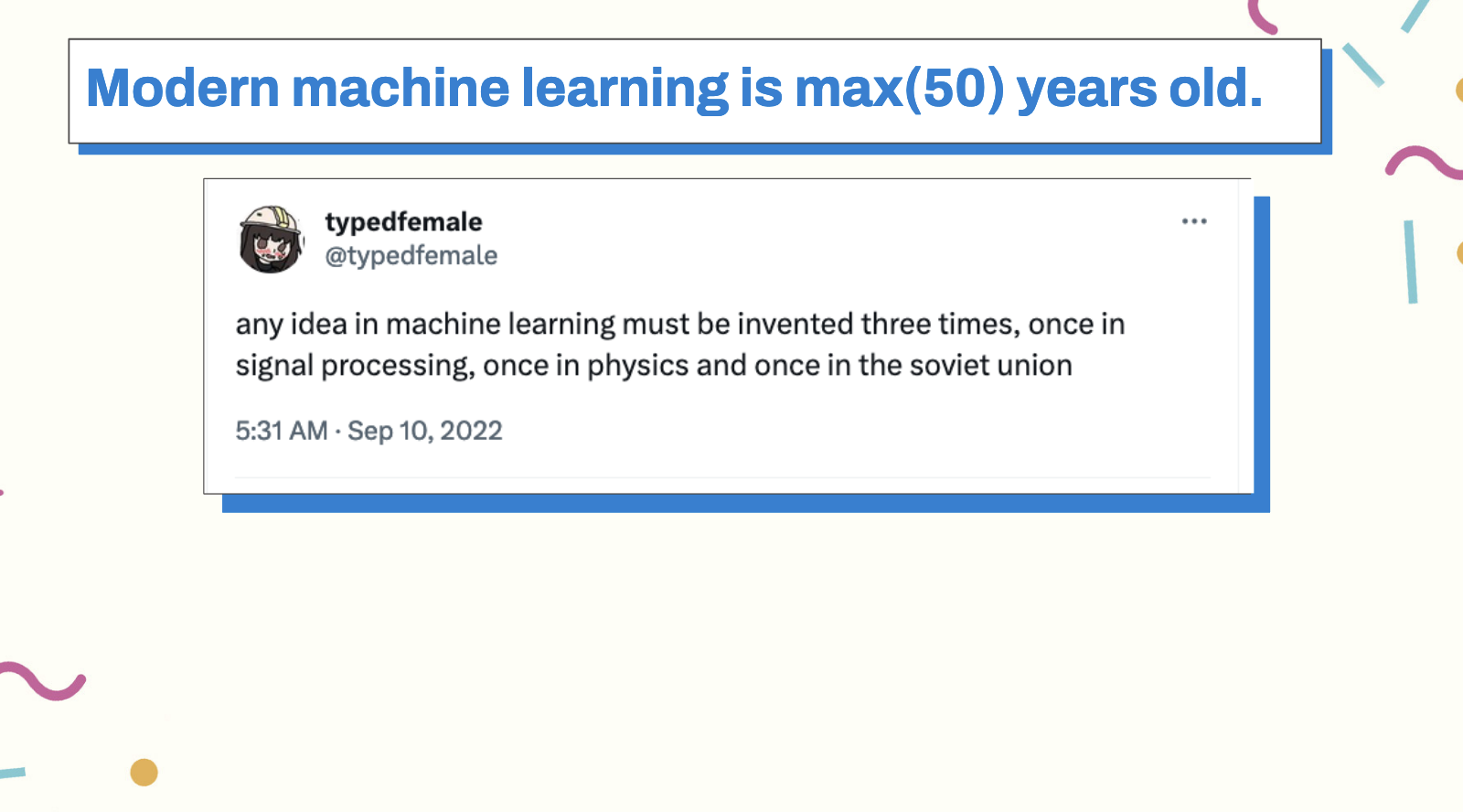
Modern machine learning is, at most 50 years old, which means the churn for ideas is unbelievably high and results in needless noise in our engineering processes. Hadoop, which we consider ancient in machine learning conferences (and which is still running in production in many places!), was released in 2006.
The data space particularly is vulnerable to this: data science is only 10 years old and already losing mindshare to areas like AI research and machine learning engineering. AI research changes every week. Everyone is talking about RAG like it’s a household term that we didn’t learn about last week and read up on just so we could make joke tweets about it.
We, like the book Piranesi, are being flooded with new terminology, new concepts, and a new landscape being created around us without any of our own input. We are at the mercy of the House of Data. Look at the latest AI landscape chart - can you even see it? (Surprisingly, this is less services than Amazon currently has in Sagemaker.)
Taking Control of the Flood

Unless, we take control and start adding to our historical knowledge of these systems by dissecting them, we will be swept away in the flood.
Ellen Ullman, a software engineer who worked on complex systems starting in the late 1970s including at startups and large companies, does this in an essay called: “The Dumbing Down of Programming: Some thoughts on Programming, Knowing, and the Nature of Easy”, which she wrote in 1998, when she wanted to uninstall Microsoft Windows NT and install Slackware Linux on her desktop.

In order to understand the insanity of what she was doing, you have to remember the situation of computers at the time. Microsoft, like it is today, was riding an all-time high in the market and in public perception. Windows was extremely popular - people even lined up at midnight to buy Windows 98.

Microsoft Windows NT Workstation reached an installed base of 15 million units. To understand how significant this was in an era where applications have hundreds of millions of users, you have to understand that only about 43% of households had personal computers at the time.
Linux, on the other hand, was new and written by a random dude who created a “free” operating system that he meant to be “just a hobby, won’t be big and professional like gnu”, and only nerds wanted it.

What was different was that Linux was open, the operating system available to all to introspect. But, there was a price to pay to get to Linux. In order to do this, Ullman first has to purge Windows NT from her machine. Because she was several versions behind the latest, and Microsoft wouldn’t allow her to delete without all of the components being on the same version, Ullman first had to upgrade some software, through bundles of floppy disks, then completely downgrade to a compatible version that could be deleted. Then, she had to actively reformat her hard drive.
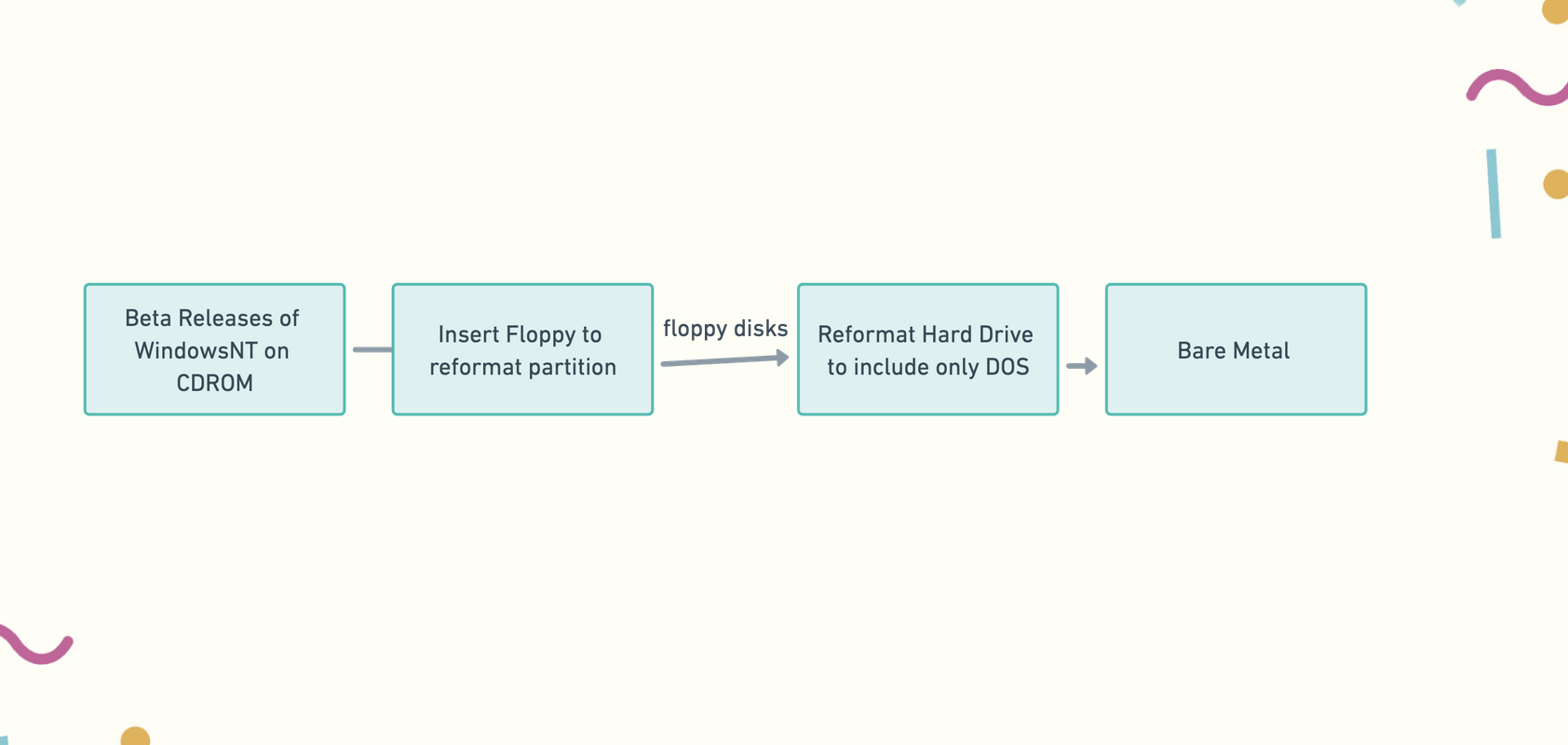
She started this process in the morning and, finally, in the middle of the night, she had just a bare machine. But, there was a cryptic error message. “no ROM basic, system halted.”

It turns out that the very first IBM-compatible PCs, were written in the BASIC language. The coding facility was located in the ROM. In the 1990s, there was no BASIC ROM in PCs but the message had never been taken out.

“No operating system, look for basic” is what the computer was saying. She said, “I had not seen a PC with built-in BASIC in sixteen years, yet here it still was, a vestigial trace.”
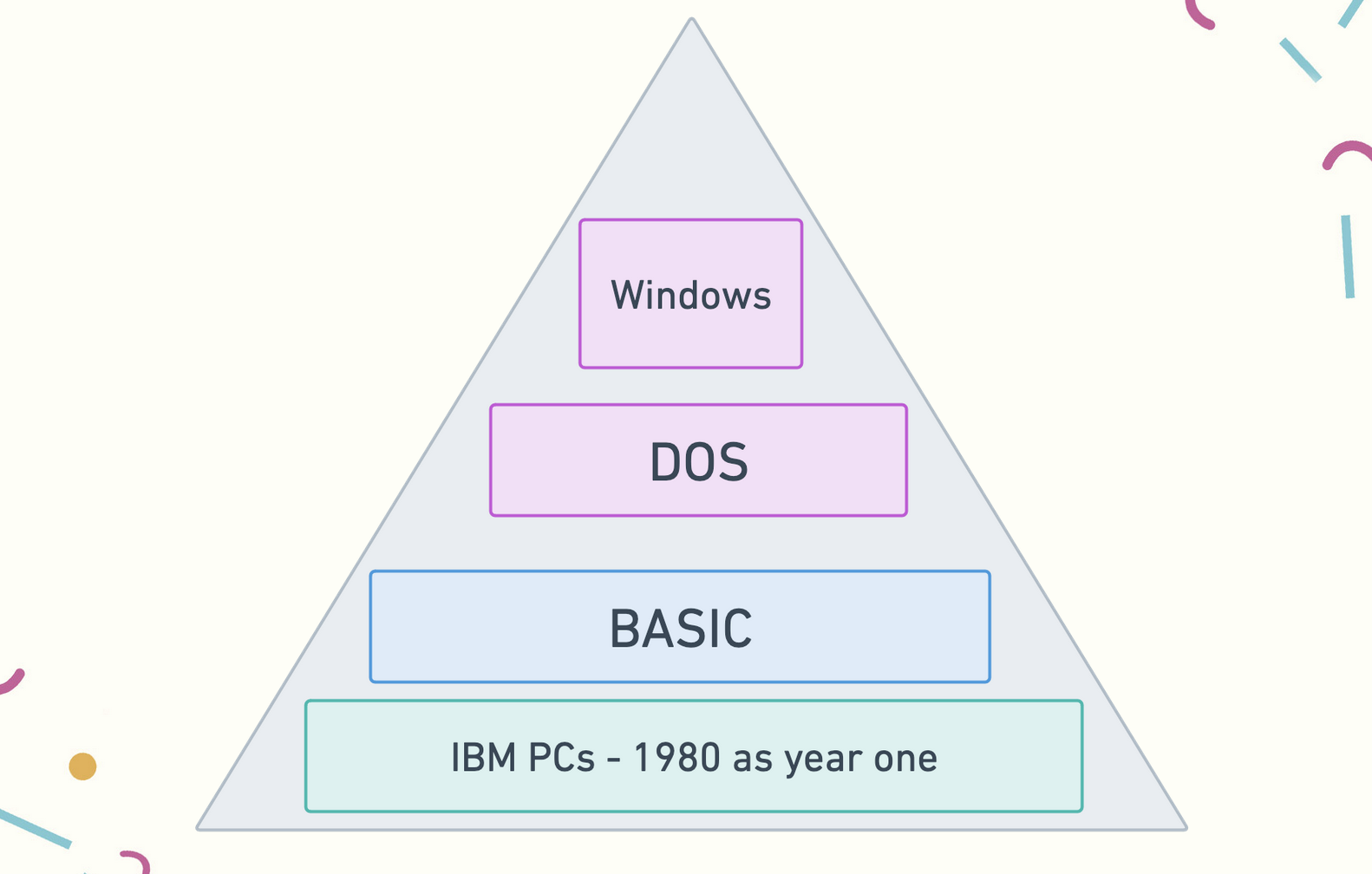
There are vestigial traces, previous patterns, archaeological remnants and clues, the Roman empire of computing around us everywhere we look. Ullman has written,

But it doesn’t have to be this way.
The Context Window

When humans have no external context as guardrails, we end up recreating what’s already been done or, on the other hand, throwing away things that work and glomming onto hype without substance. This is a real problem in production data systems. In order to do this, we need to understand how to build one.
Let’s start by talking about cache invalidation. When we build a data-intensive application, we have two problems we need to overcome: the cost of moving data and the cost of processing it, also known as understanding whether our process is I/O bound or CPU-bound.
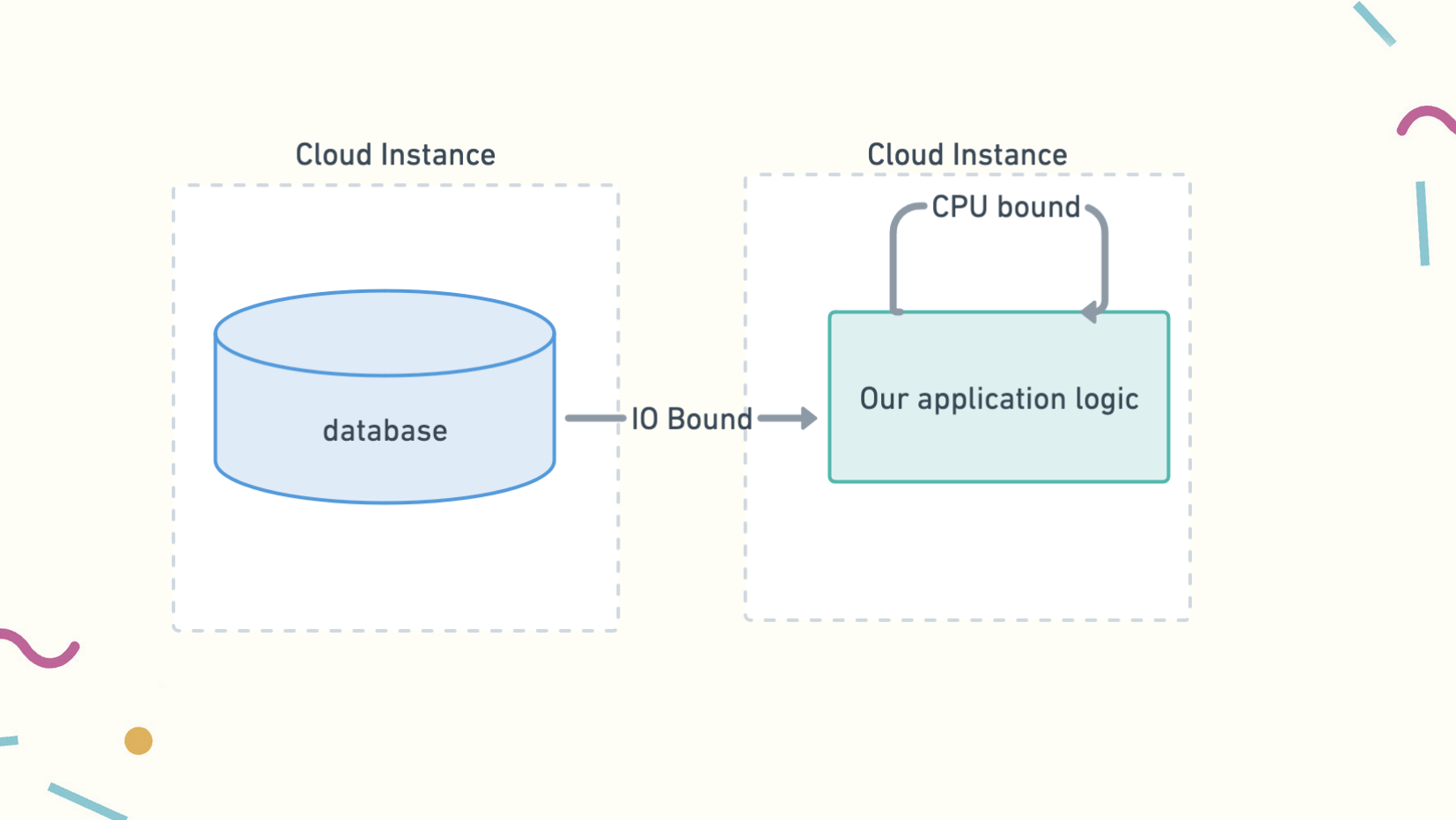
Usually, in today’s distributed and cloud-based industrial architectures, the data we need is located on one machine and the place we’d like to process it is located on a different machine. In data-intensive workloads, we incur the cost of computation and network calls when we perform expensive queries or machine learning inference on one service that calls out to our model.
This is a problem at every level of computing, and even at the level of training neural networks. For example, a recent article from ACM about model distillation, which is the process of large, teacher models compressed passed down to smaller, more flexible student models for inference.

This is part of what Sarah Hooker refers to in the Hardware Lottery as a limitation of the deep learning software and hardware architectures when she says that research ideas win because they are compatible with available software and hardware and not because the idea is superior to alternative research directions. This is true in the industrial space as well - we are always constrained by our hardware, our software, (and our budgets).

However, processing power is not a new problem - it’s been happening since the invention of the Jacquard loom, which essentially solved the problem by hard-coding global variables.

To prevent this limitation, we can pre-compute a set of results and put it into a cache, which is software that typically processes data much more quickly, with the limitation that it can only process data that fits into the memory of our machine.

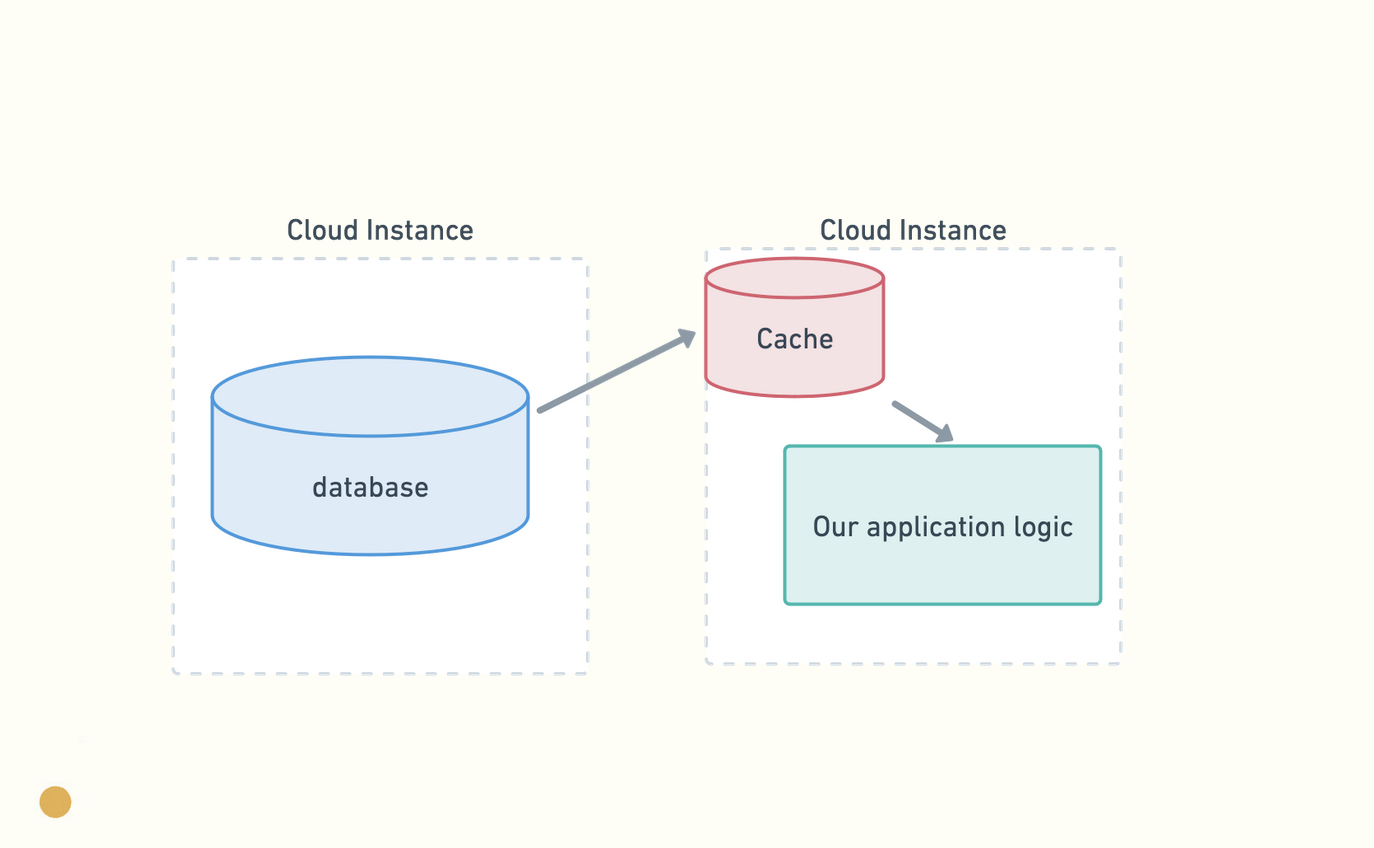
A cache is, essentially, an in-memory lookup table that’s faster than retrieving values from a hard drive. Or, in other words, it’s a dictionary.

Instead of constantly hitting the database to get our values, we can save some of the computation and movement overhead by keeping that data in cache and doing a lookup at inference time. We’ve been using caches forever, in fact since the days of Netscape, and in the browser, which is why Phil Karlton joked about them. Any given time you access any web application, you’re accessing several levels of cache.
Let’s take an app like ChatGPT as an example. When we ask it a question, the application has to authenticate, reach out to the chat endpoint, and query an instance of the model, perform the lookup, and return results and add them to cache, all within milliseconds based on the user’s expectations of latency for a search/chat app. This becomes really expensive to engineer well at scale. So expensive in fact, that some estimate that it costs OpenAI about $700k a day to run ChatGPT, or $70 million over the time that it’s been online.
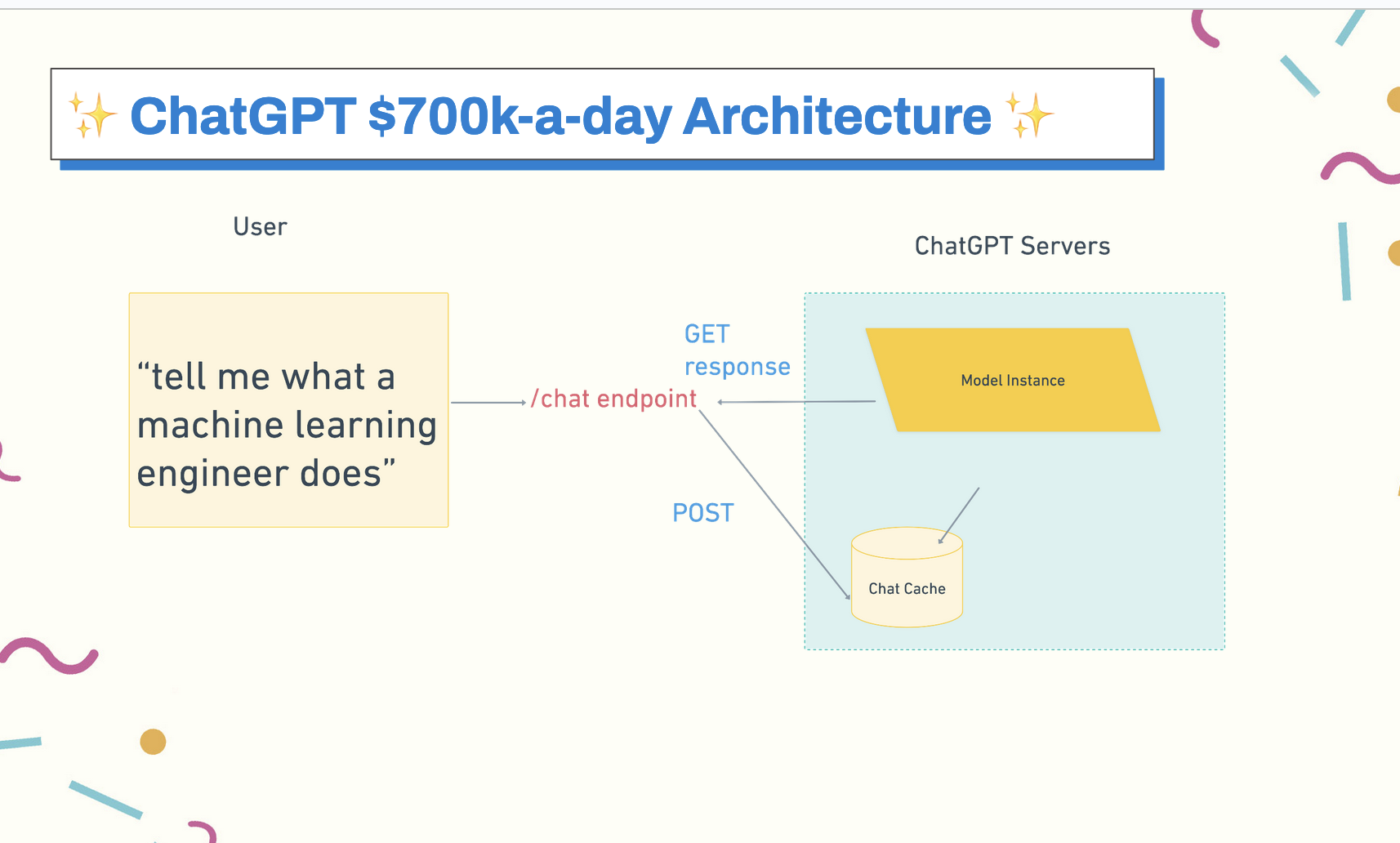
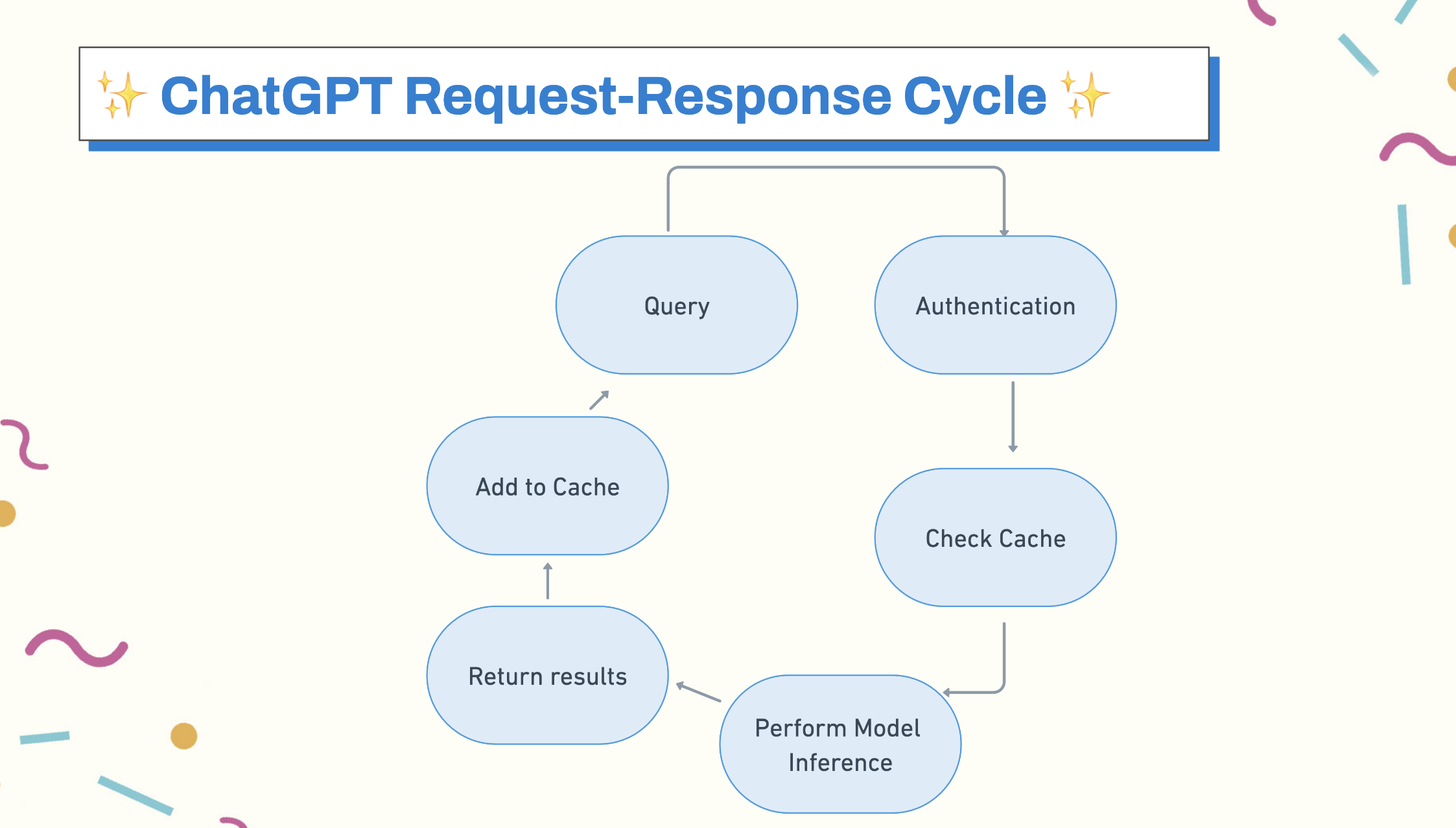
What we can do is cache some of this. We can’t predict a future user query: who knows what types of stuff we’ve all put into ChatGPT. But, we can cache past queries, which is how ChatGPT keeps track of all of your past conversations and can bring them up quickly. And, we can cache common enough queries for single words, or we can also cache different queries, but ones that happen in the same timeframe. Elasticsearch does this on a per-query basis, as an example.
This access pattern is really useful because we often need to move elements in and out of cache, particularly if we need lists of items or results from our machine learning models, or other computationally expensive operations. It’s much faster to store results in cache if we need them in a high-scale web environment.
Now our data is accessible quickly and we have what are known as cache hits: a query hits the cache and returns results immediately in response. However, now we have a problem: we are relying on the cache to consistently be up-to-date when we ask it for data. Otherwise, if there is no data in the cache, the application will try to reach out to the database, which can take a long time. Or, it will simply error out and stop running, depending on how it’s written. This is a cache miss.
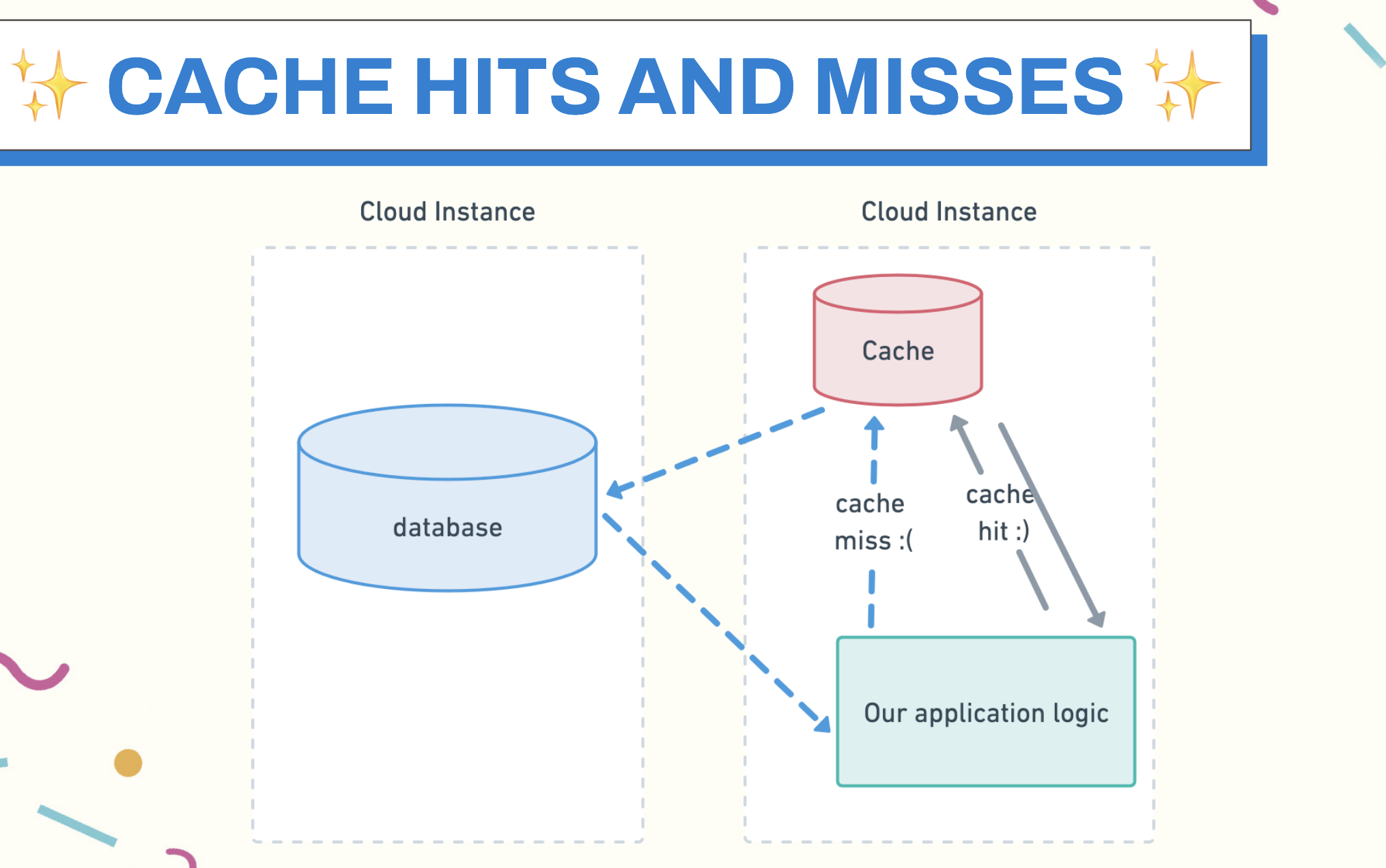
Without the cache, which condenses the data from the global state, the system is much slower and is flying blind. The system becomes our first Piranesi. In machine learning, and particularly in LLMs, this pattern of building up a cache to populate fast-retrieval for app data is similar to building a context window. The “context window” is a term that comes to us from the natural language processing community. The context window, very simply, is a range of tokens or words around a given word that allow us to understand the meaning of that word.

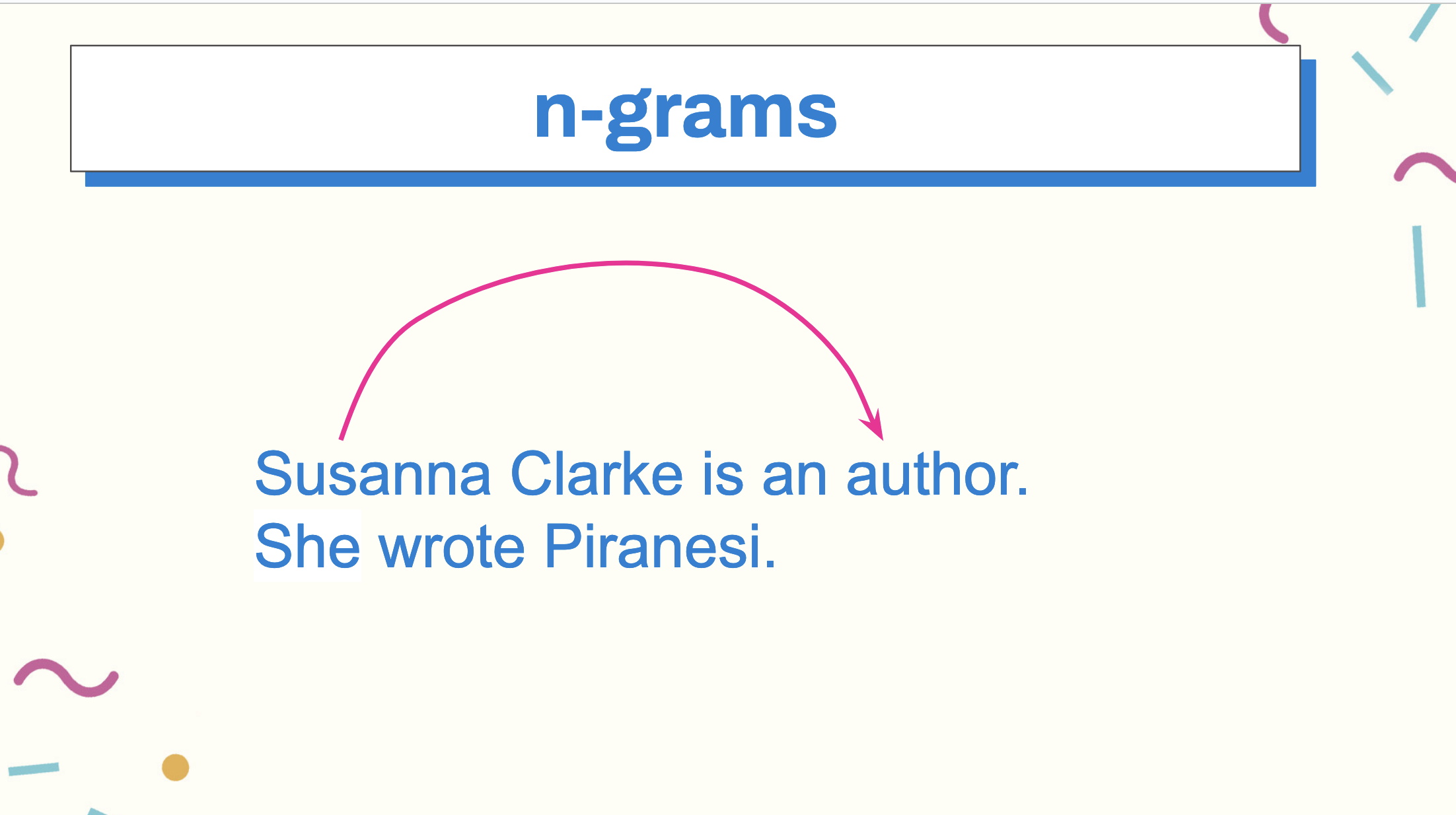
We keep that context window “in memory” when we train models, and again, in LLMs, when we formulate our queries against them. For example when we say, “Susanna Clarke is an author. She wrote Piranesi”, in our minds, we need the context window of the first sentence, Susanna Clarke,” to understand that, in the second sentence, “She” is referring to Susanna.

Humans can infer this because our brains are constantly processing things in cache. In The Programmer’s Brain, Felienne Hermans, a professor of computer science whose research focuses on how people learn to program writes that when we get confused about the code we’re writing, there are actually multiple types of confusion happening at the same time.
As a quick primer, the human brain has several types of memory, short-term, working, and long-term. Short-term memory gathers information temporarily and processes it quickly, like RAM, or much like a cache. Long-term memory are things we’ve learned previously and tucked away, like database storage patterns. Working memory takes the information from short-term memory and long-term memory and combines them to synthesize, or process the information and come up with a solution.
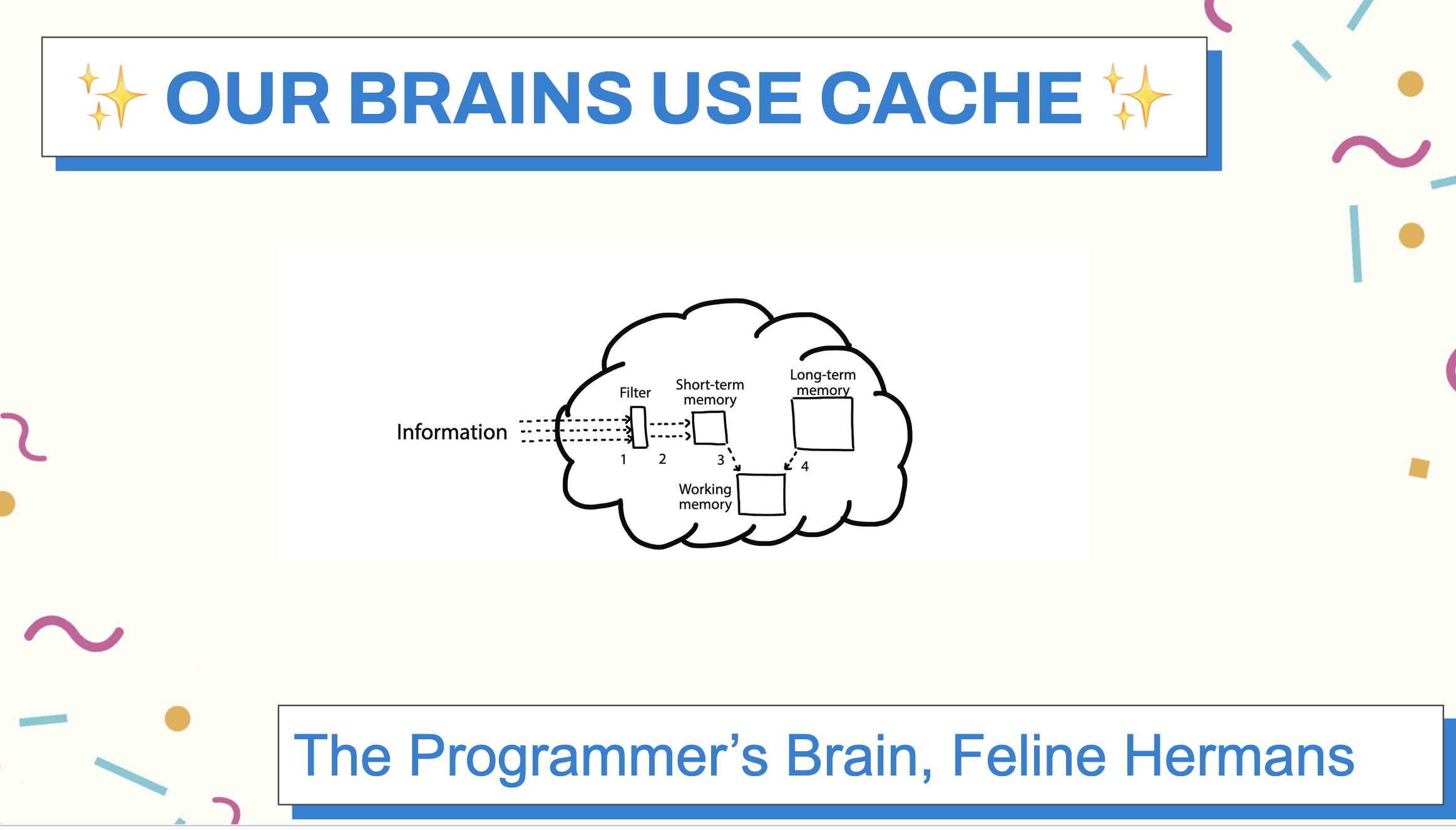
When we’re working on building software, (and by working on, we mean most often reading someone else’s code) all of these processes are going on in our brain simultaneously to try to help us make sense of the programming environment.
It turns out that humans can also lose our context windows pretty quickly, because we can really only hold 7 things in working memory.
If you were following the news in November of last year, even as ML practitioners, ChatGPT seems like it came out of nowhere. The entire industry turned on its ear. The fact that it could generate limericks in the style of Shakespeare made it an unbelievable party trick that started slowly to turn into potentially useful applications. One of my friends said, “I’ve been working in machine learning for 15 years and I’m not sure I understand how to now interpret what this means for modeling.” At the time, I wrote,

I, myself, like a lot of the industry overnight, became Clarke’s Piranesi. My context window for reacting to ChatGPT was just this:
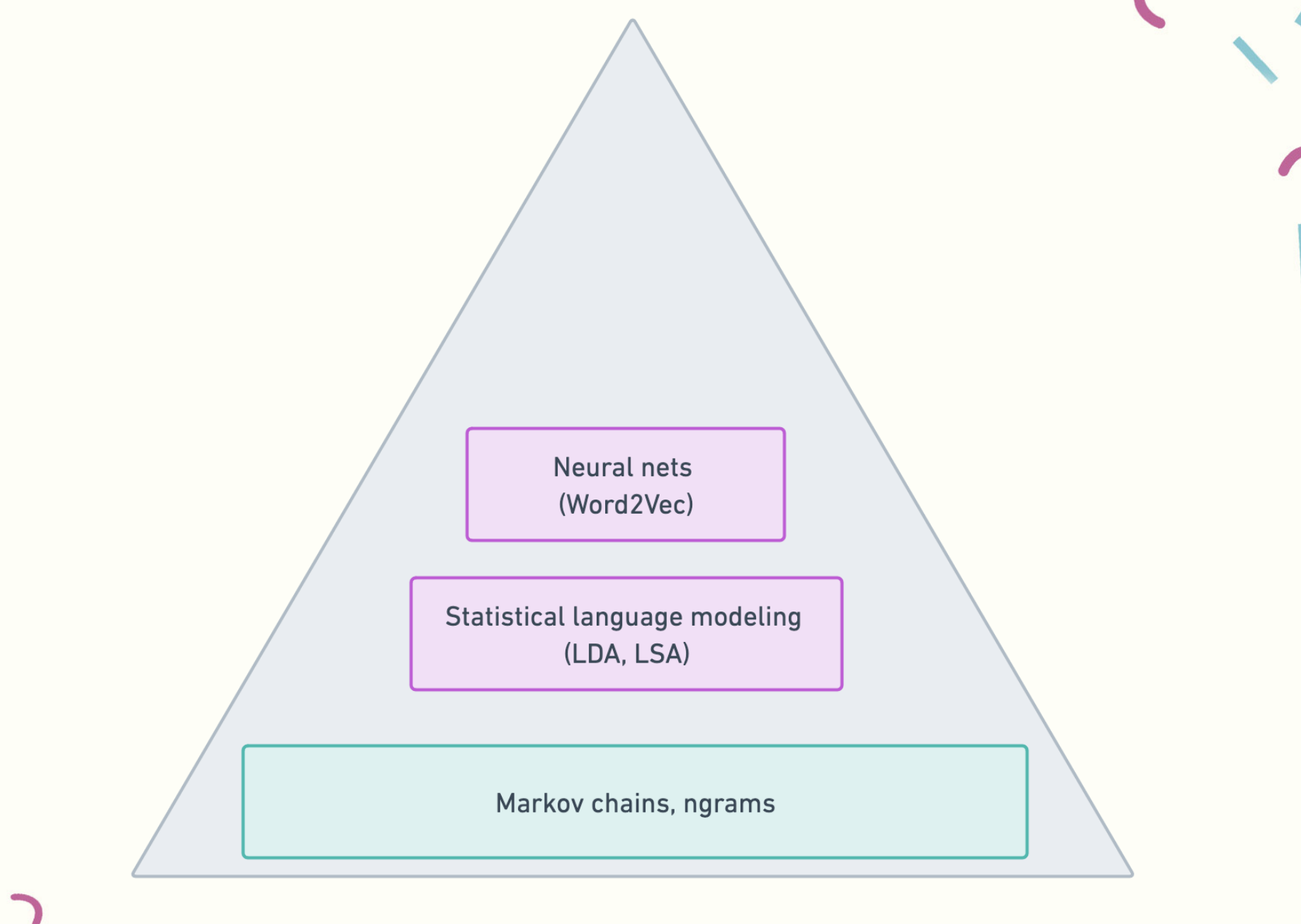
However, once we got over the initial shock and started to look into it, it became clear that what LLMs are doing with context windows is nothing new. If we start building our information cache with the very beginning of understanding documents in context, if we dig deep into the collective memory bank of engineering and science culture, we will find Markov chains.

Markov chains are a classical method in statistics that predict the next action given the previous action. First-order Markov chains don’t carry any more state than the previous action. So if we know there is a .7 chance to move from E to A, and a .3 chance that we’ll experience E again, we can predict what the next action is.
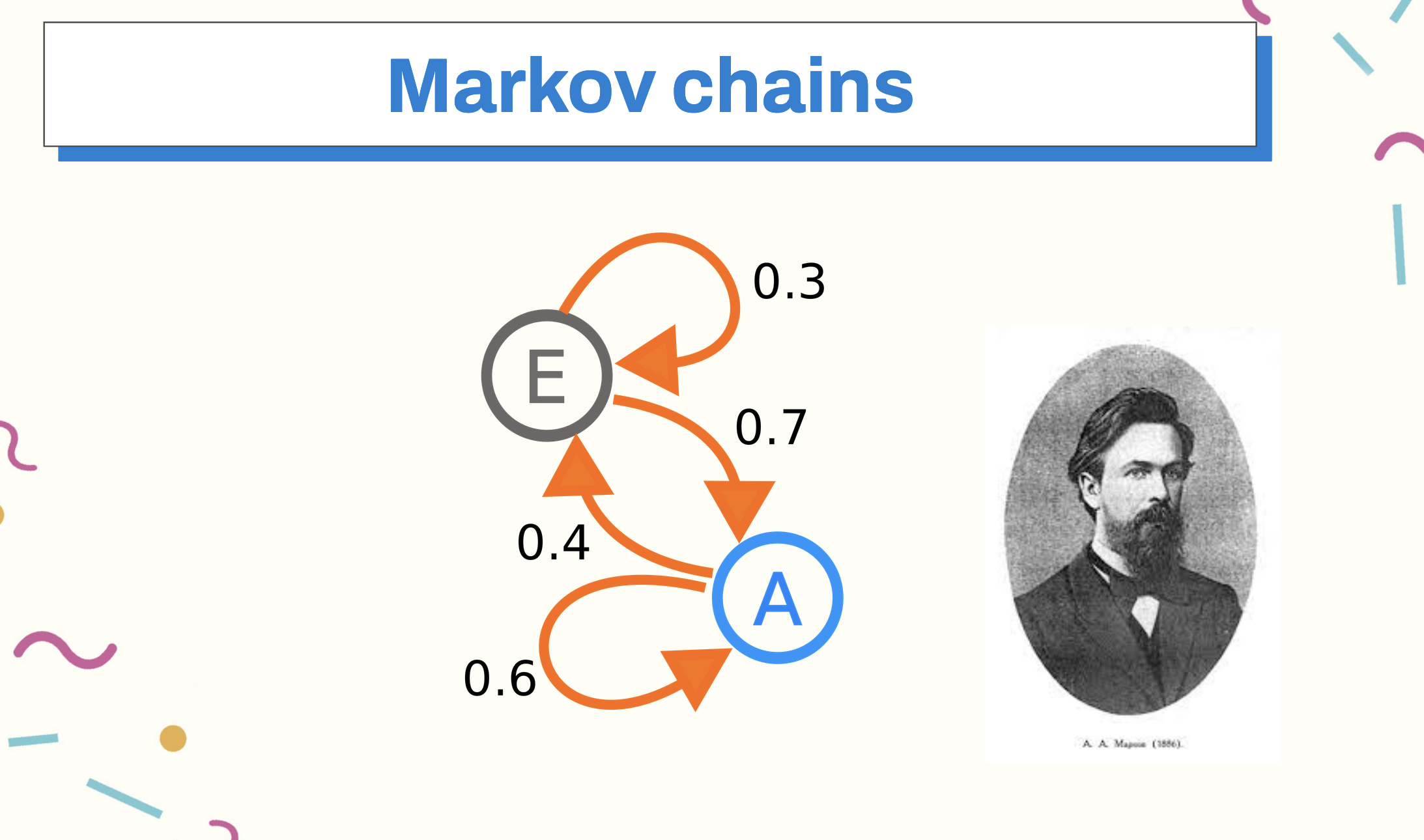
LLMs are not Markov chains. But they are similar enough that it matters, and moreover, Markov chains have been favorite toy problems for programming. In The Practice of Programming, a classic book by Kerninghan and Pike released in 1999, they go over Markov chains as a way to statistically generate words.

In 2015, I created a Markov chain generating probable Hacker News headlines based on a training data set with an insanely simple and embarrassing script that I’m only going to show for a second and then never again to the internet at large.

Using this script, I was able to generate probable sounding Hacker news headlines: You can see the results are not very good, and Markov chains were a baby GPT, but I was also only a baby machine learning engineer, so we were perfect for each other.
Markov chains are nowhere near LLMs if you know that we’ve been trying to do context prediction for a long time, and probabilistic models of text sequences (and not only, Markov chains have been used extensively in physics, economics, and math), large language models slowly start to lose some of their mystique.

So, ok we’ve built the first stage of our context window.
From Markov chain generation, we moved on to ngrams, which, instead of looking only at the previous state, look at the state of n-1 words, building the context around the word we care about. Google started to use these for statistical machine translation, speech recognition, and spelling correction.
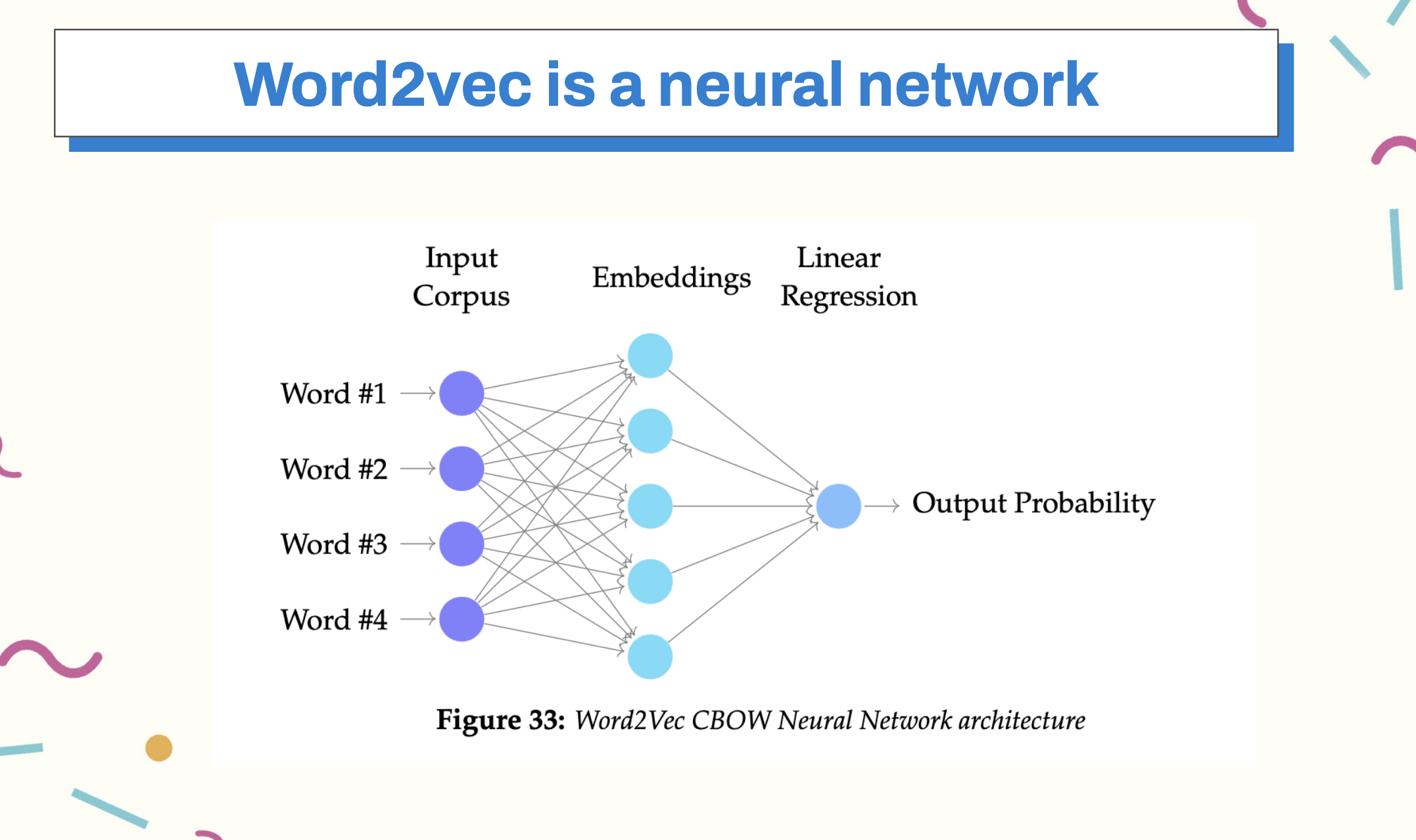
However, as our vocabularies and context windows became larger, so did our computation sizes. To get around the limitations of earlier textual approaches and keep up with growing size of text corpuses, in 2013, researchers at Google came up with an elegant solution to this problem using neural networks, Word2Vec.
Word2Vec is a family of models that has several implementations, each of which focus on transforming the input dataset into vector representations and, more importantly, focusing not only on the inherent labels of individual words, but on the relationship between those representations - building context between various parts of the text.
There are two modeling approaches to Word2Vec - cbow and skipgrams, both of which generate dense vectors of embeddings but model the problem slightly differently. The end-goal of the Word2Vec model in either case is to learn the parameters that maximize that probability of a given word or group of words being an accurate prediction in the text.
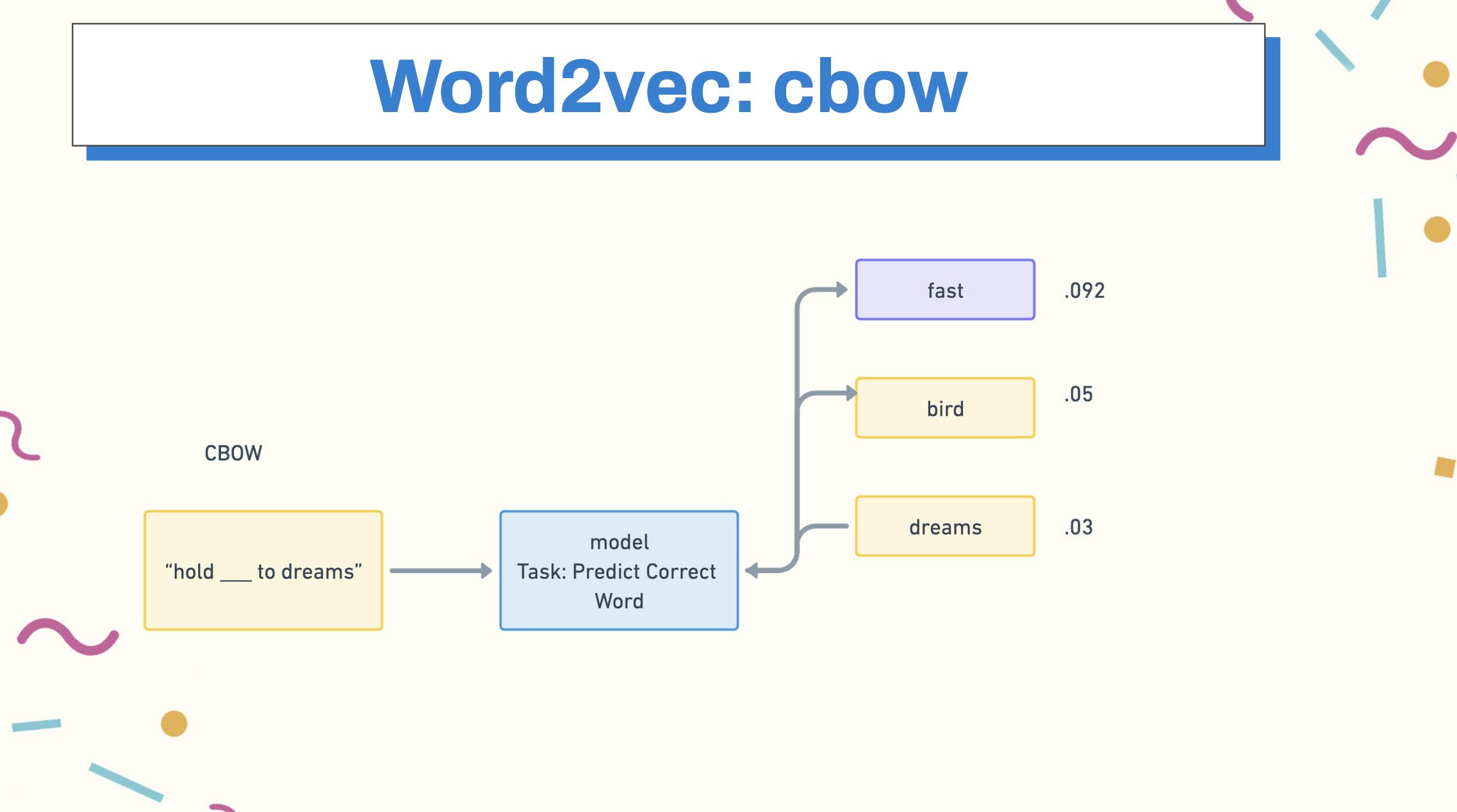
Let’s look at the case of CBOW: In training CBOW, we take a phrase, let’s say for example, “Hold fast to dreams for if dreams die, life is a broken-winged bird that cannot fly” and we we remove a word from the middle of a phrase known as the context window, for example, fast. When we train our model, we train it to predict the probability that a given word fills in the blank.

Word2Vec became one of the first neural network architectures to use the concept of embedding to create a fixed feature vocabulary.
However, in Word2Vec, information flows from encoding to embedding and output layers without feedback between the latter two. This limitation prevents the model from understanding long-range context and handling out-of-vocabulary words, or text that wasn’t in the original input. Word2Vec also struggles with polysemy, where words have multiple meanings in different contexts.
An important concept allowed researchers to overcome computationally expensive issues with remembering long vectors for a larger context window than what was available in RNNs and Word2Vec before it: the attention mechanism, combined with previous ideas like the encoder/decoder architecture. The encoder/decoder architecture is a neural network architecture comprised of two neural networks, an encoder that takes the input vectors from our data and creates an embedding of a fixed length, and a decoder, also a neural network, which takes the embeddings encoded as input and generates a static set of outputs such as translated text or a text summary. In between the two types of layers is the attention mechanism, a way to hold the state of the entire input by continuously performing weighted matrix multiplications that highlight the relevance of specific terms in relation to each other in the vocabulary.

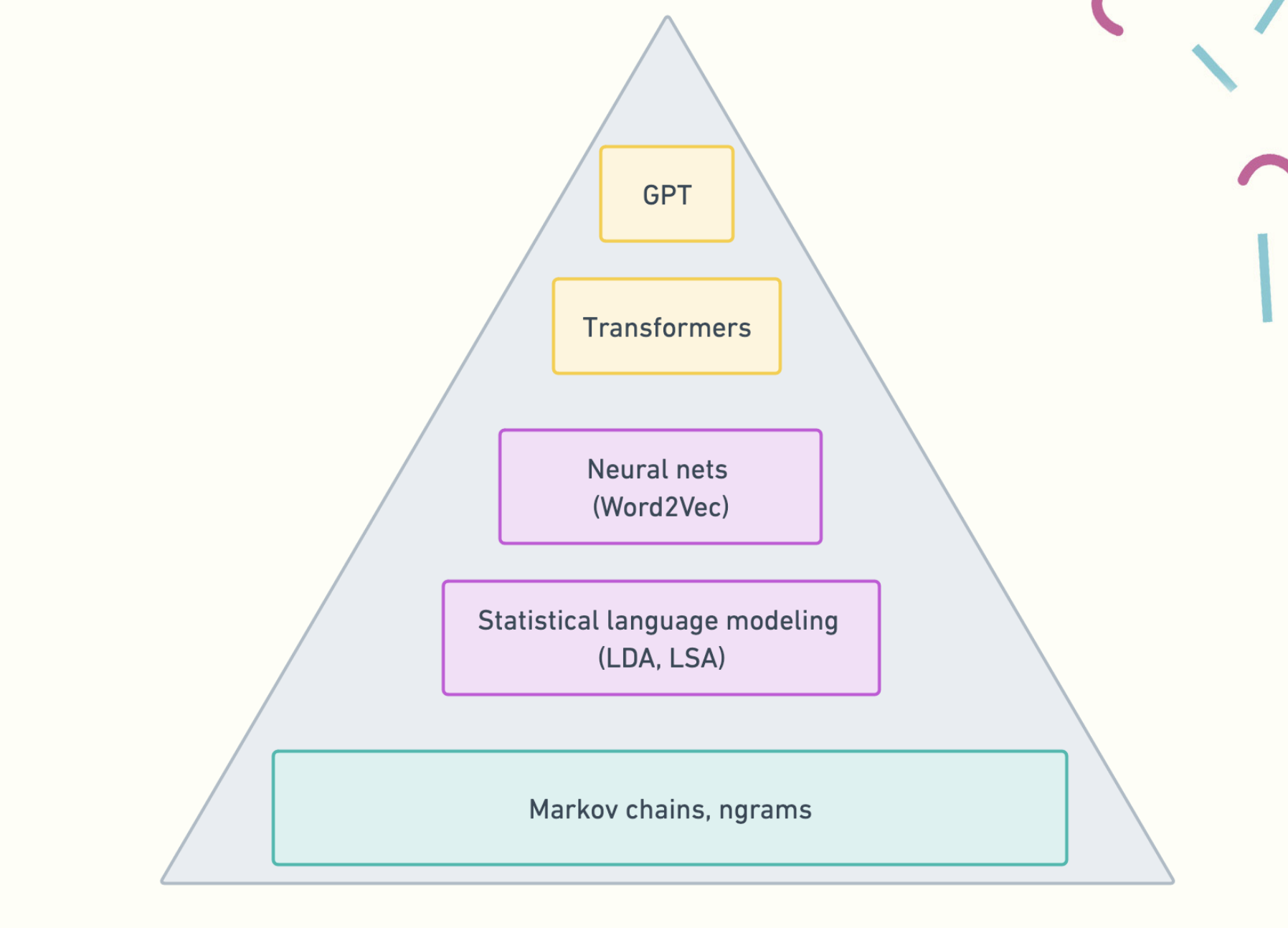
We can think of attention as a very large, complex hash table that keeps track of the words in the text and how they map to different representations both in the input and the output.
So what attention is really just a hashmap or since this is PyData, a dictionary. Which is what a cache also is at its very heart.

In fact, there is a reason that Redis, one of the most-often used pieces of software in caching, expands to Remote Dictionary Server.
In ChatGPT4, Bard, and other Large Language Models what we are doing when we train them is increasing the scope or richness of the context window so that they know about the text, and also the input vocabulary we have. And in, retrieval, we’re also trying to increase the context windows we pass in.
And now, to bring this all back to LLMs and ChatGPT it turns out that, just like some of the hardest problems in human memory are how to keep context windows and in Transformer models how to keep attention, some of the hardest problems in LLMs are actually how to operate caches.
In March, ChatGPT experienced a data leak precisely because of cache invalidation.

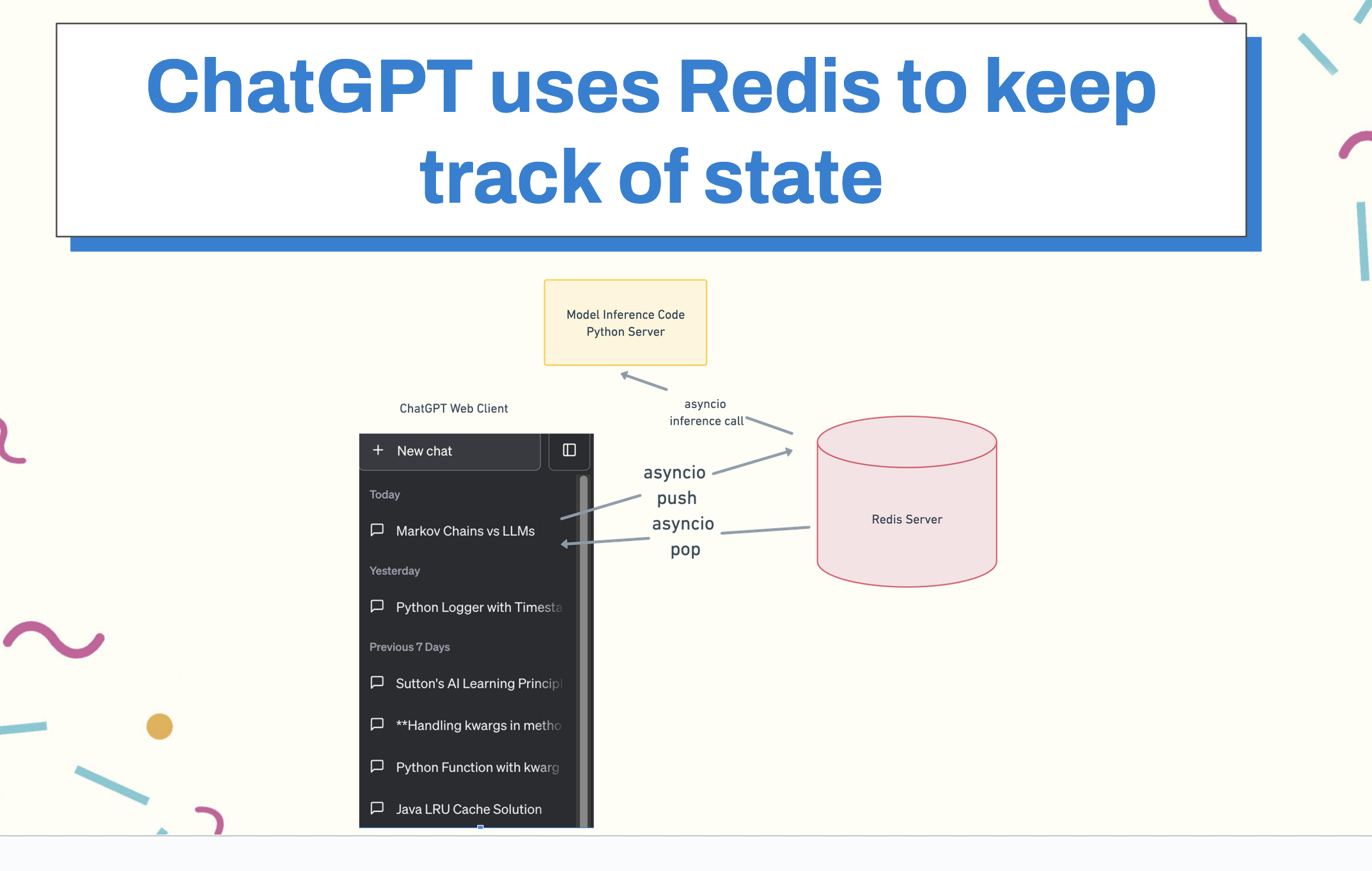
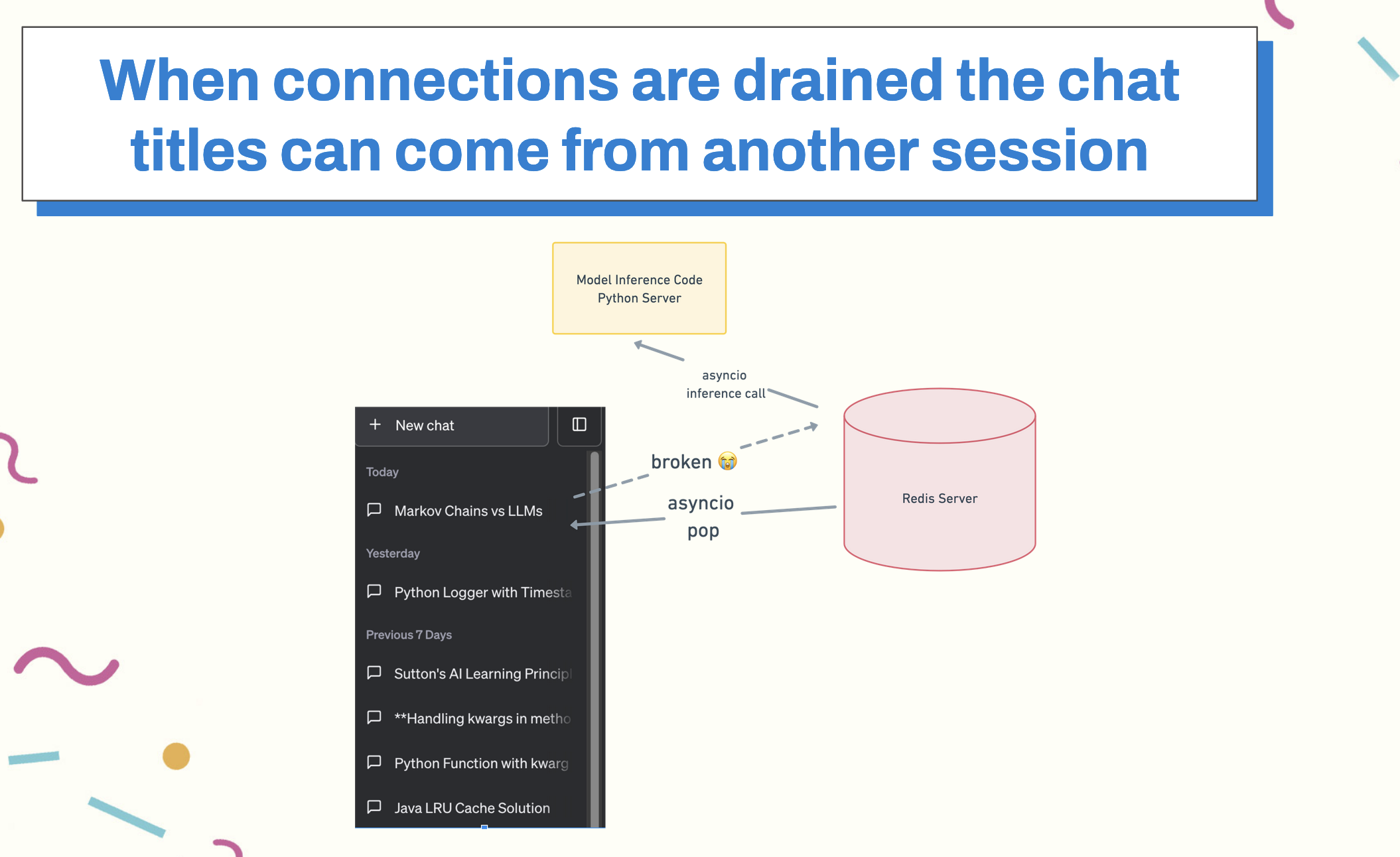
ChatGPT uses Redis to keep track of your chat history state and user information so that it doesn’t have to perform expensive queries to retrieve your chat history every time. The chat history, on the sidebar, is hot-loaded from Redis using the py-redis library. Py-Redis uses asyncio, a Python async management framework, to maintain connections between the Python server and the Redis cluster, which recycles stale connections. Those connections behave as two queues, where the caller pushes a request onto the queue and pops a response from the outgoing queue, which returns a connection to the pool.
If the request is canceled after it’s pushed onto the queue but before the response is popped, the connection is corrupted and the next, unrelated response that’s dequeued can receive stale data. If that data happens to match, it will return bad data to unrelated users. So it’s a cache miss, but where the cache miss propagates other user’s chat titles into your chat history: a context window of the very, very wrong kind.
Now we’ve made a full circle, cache, context window, and how our minds work are interconnected.


Naming Things

So much depends on the context window: how we understand LLMs, how we process them, and even how we deploy them. In order to work through the hype of LLMs and do good data work today, we need a good context window. And, if we don’t have a good context window, we also can’t do the second part, which is naming things.
Let’s start by talking about just why it is that naming things is really important, and equally hard Think about how many times you’ve sat over a variable name. Should it be Cache or DataStore? Vector or List? GetActions or PullActions? Why is this process so challenging?
There’s a neat little book that came out recently called, appropriately, “Naming Things” by Tom Benner that talks about this process. Benner writes that naming things is hard because there are a lot of expectations on us, the namer. We, the namer, need to know
- exactly what the thing does
- The term for the thing both in a business and technical context and
- The name will be reused throughout the codebase
When we name things, we need to think about how easy the name is to understand - aka the name should not have multiple meanings and can’t be redundant throughout the codebase, the name needs to be consistent with other parts of our codebase, and yet it also needs to be distinct enough to name the context of that thing.

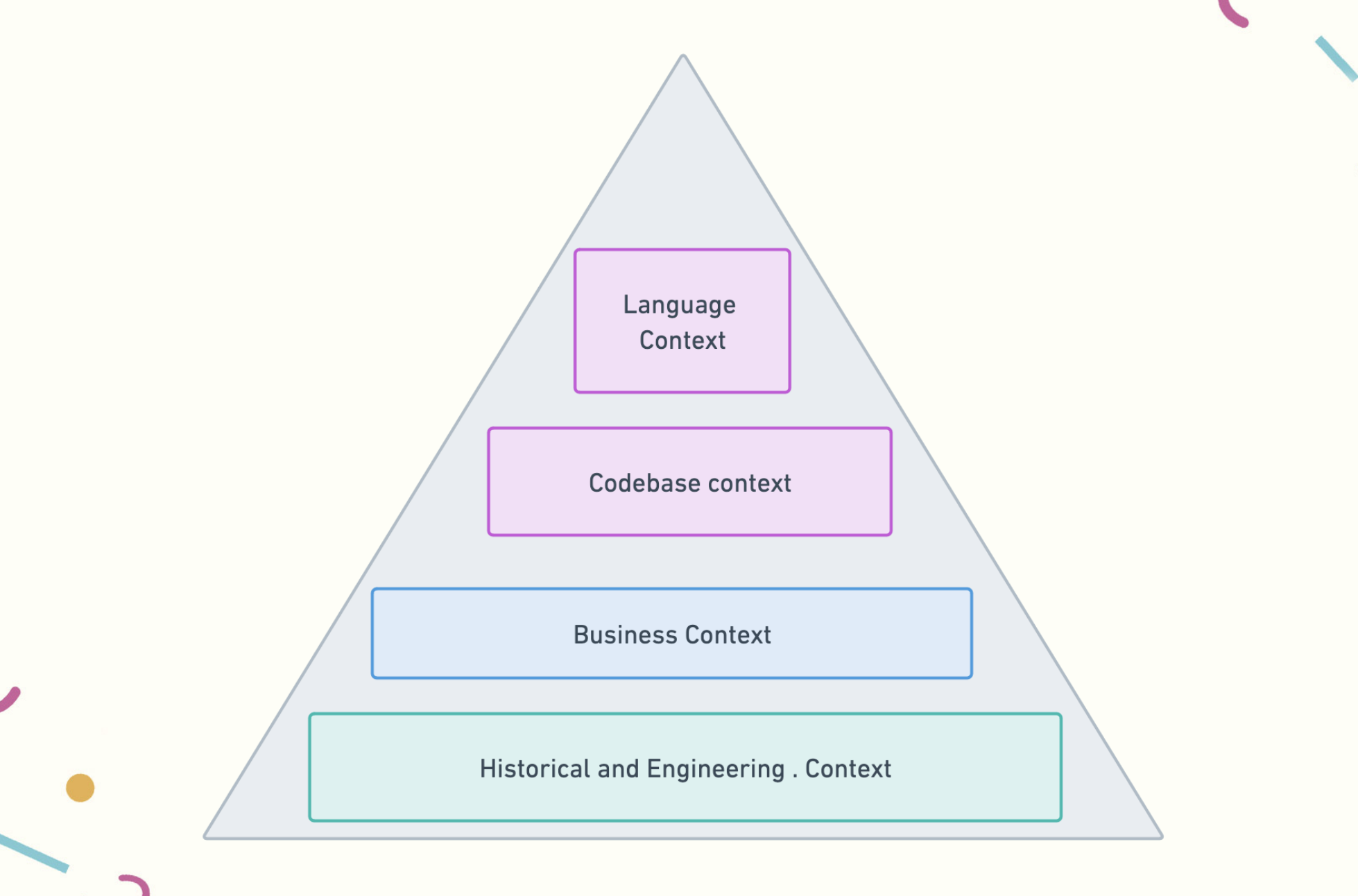
Then, we also have the external industry context of the name, particularly if we’re working with code that’s open-source, or will be read by practitioners like us across the organization. And finally, when we look at names, it should make sense
What we’re doing when we pick a good name is reconciling context windows on more than two dimensions, and in fact, on likely four dimensions, with the fifth, unspecified dimension being our own personal preferences. When we perform these levels of thought, we are really putting our Programmer’s Brain to work.
It turns out that, when we name things, we really are just also building up a context window! And the more historical context we have from reading different codebases across different industries, and from keeping the historical context window from our own industry, the more successful we’ll be in our own codebases.
Of course, we could just do this with ChatGPT. But we won’t be as successful!
For example, let’s hypothetically say we’re working on, a semantic search library that takes a vibe query, vectorizes the query and performs lookup, in, say a cache, that also has a search module which stores all your learned embedding vectors and then returns the results via a Flask API.
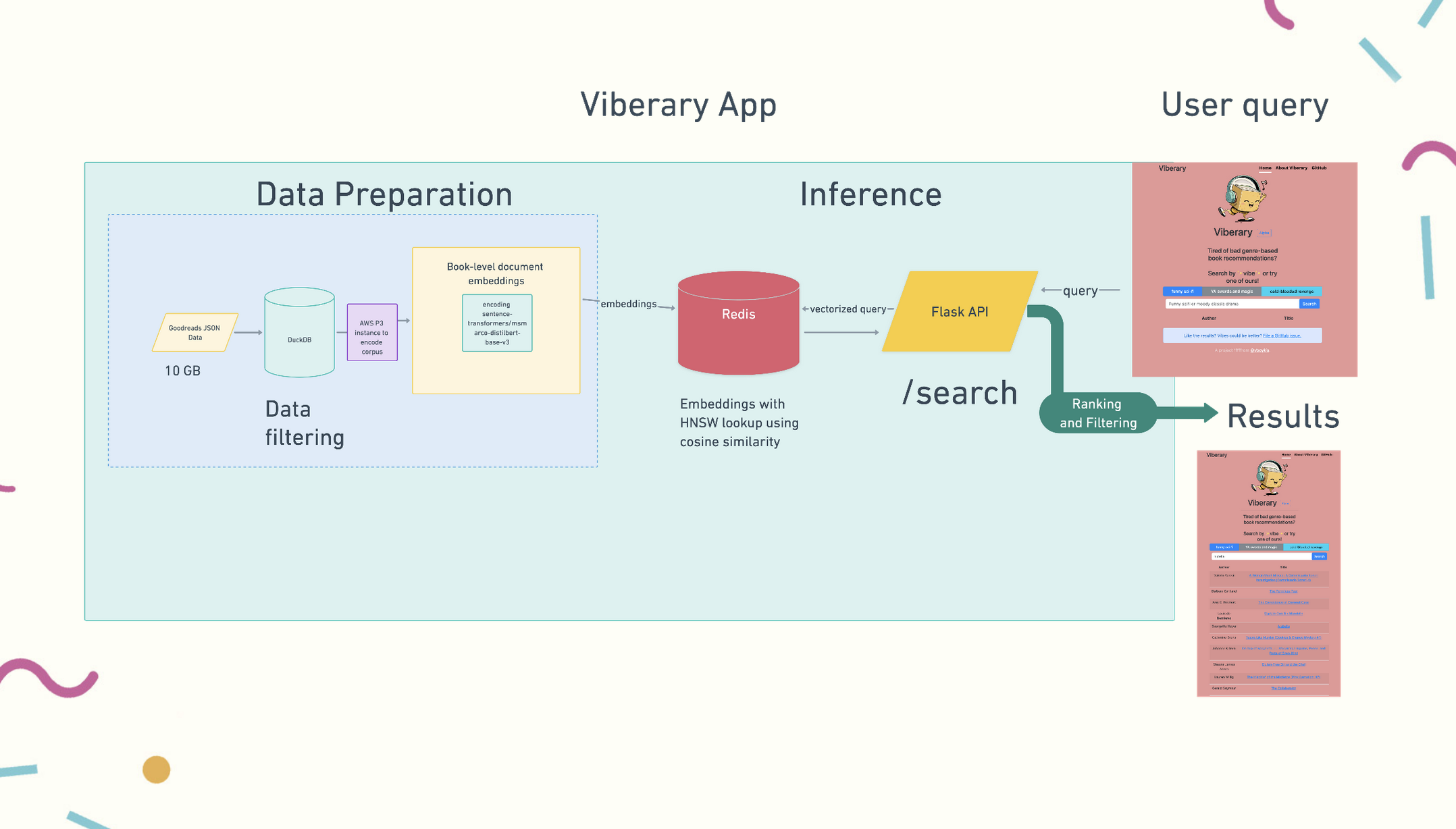
Something you might want to write is a module or class that repopulates the cache with embeddings. What would you call such a class, one that takes a static file of embeddings generated via sentence-transformers and writes them to redis, where an API call will perform a nearest-neighbors search?

If we look about rules for how we should name classes, we ideally want classes to be “nouns”, consistent with the rest of our codebase.
We could call it something like EmbeddingsWriter. Seems ok, but what if we want to write something other than embeddings later on? How about DataWriter? Too Generic because we could be writing different kinds of data, and it’s not clear where. How about VectorPutter. Next time, absolutely. If we were working in Java, instead of Python, I’d be giving this presentation at JavaData Amsterdam, and likely we could use some term like VectorSetterFactory, which makes complete sense in the context of that language.


What helps us here is building our context window. For decades in information retrieval, both within search and recommendations a common pattern has been to write a large amount of data to a data structure called an index. For example, in one of the first papers on industrial recommendation systems, Tapestry paper architecture, one of the first recommender systems, written in 1992, which was used to recommend email messages from newsgroups to read (it turns out we were overwhelmed with data even at the very beginning of the internet), has a structure it calls an Indexer, which the paper describes as,

“Reads documents from external sources such as electronic mail, NetNews, or newswires and adds them to the document store. The indexer is responsible for parsing documents into a set of indexed fields that can be referenced in queries.”
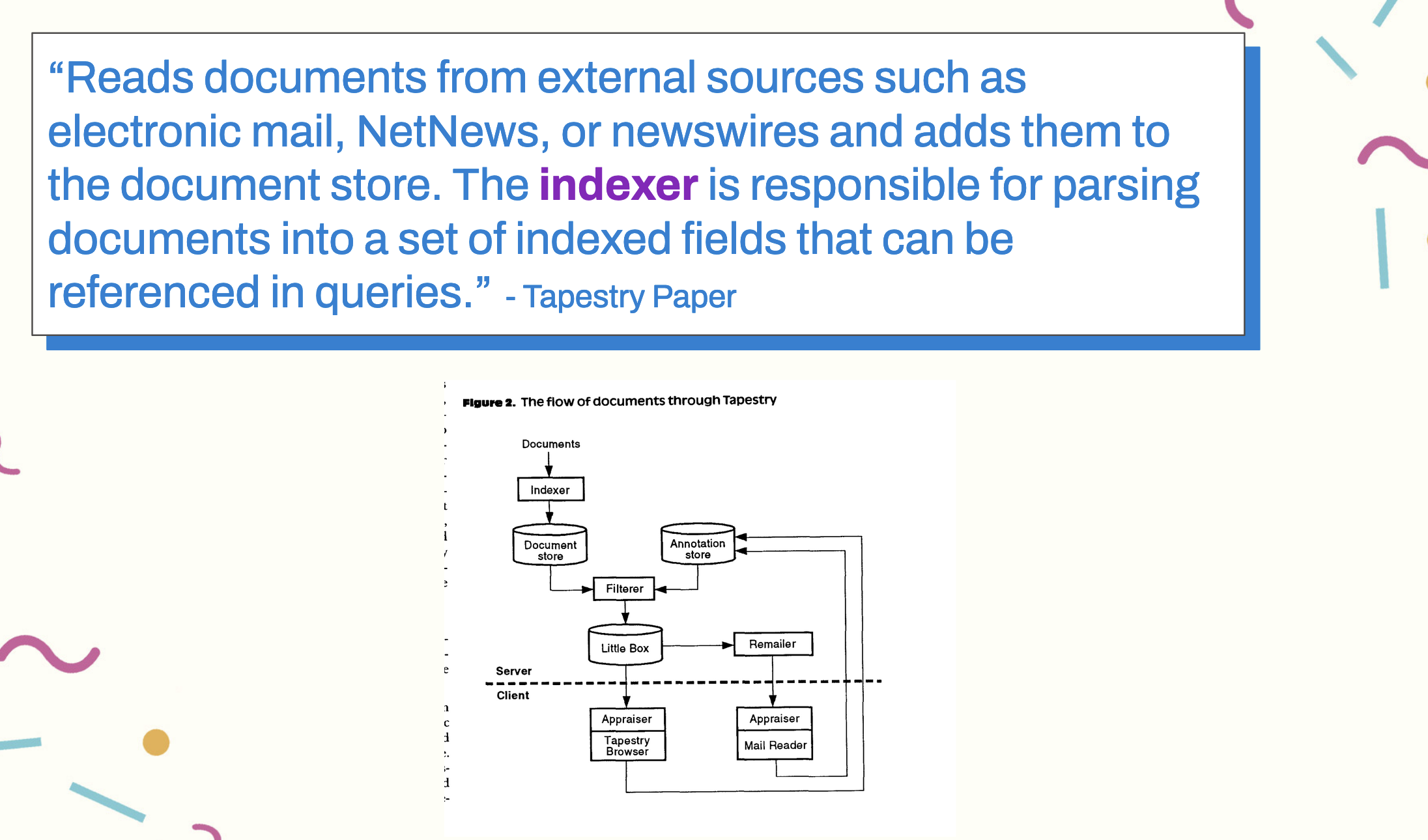
In search, particularly, this is known as an inverted index. And there we have it. We now have an indexer class.
One of the ways we are good (or bad) at naming things is all the different naming patterns we’ve come up with for our data practices. We often talk about phenomena in the data sphere as happening in the watery realms.
In a post called the Union of Data and Water, Pardis Noorzad writes, “Data toolmakers and the larger data community have long been reclaiming water terms to refer to products, services, actions, and concepts.” She has a whole list of ways we’ve been talking about data tools and products as water: data lakes, buckets of data within the data lakes, cascading (and scalding on top of that), two of the first map-reduce paradigms used to get data out of the data lake, and data in the cloud.
But, underneath the waters, if we decide to dive in, under the data lakehouse, the data lake, the LLMs, and is actually a very solid, single foundation that people have spent hundreds of people years thinking about, exactly so we don’t have to reinvent the wheel, but instead build on what’s come before.
How to build and keep your context window

Now that we have named our problems, what can we do about this so that we, as humans who are swimming in the deluge of new data, new concepts, and new terminology, are not cast adrift?
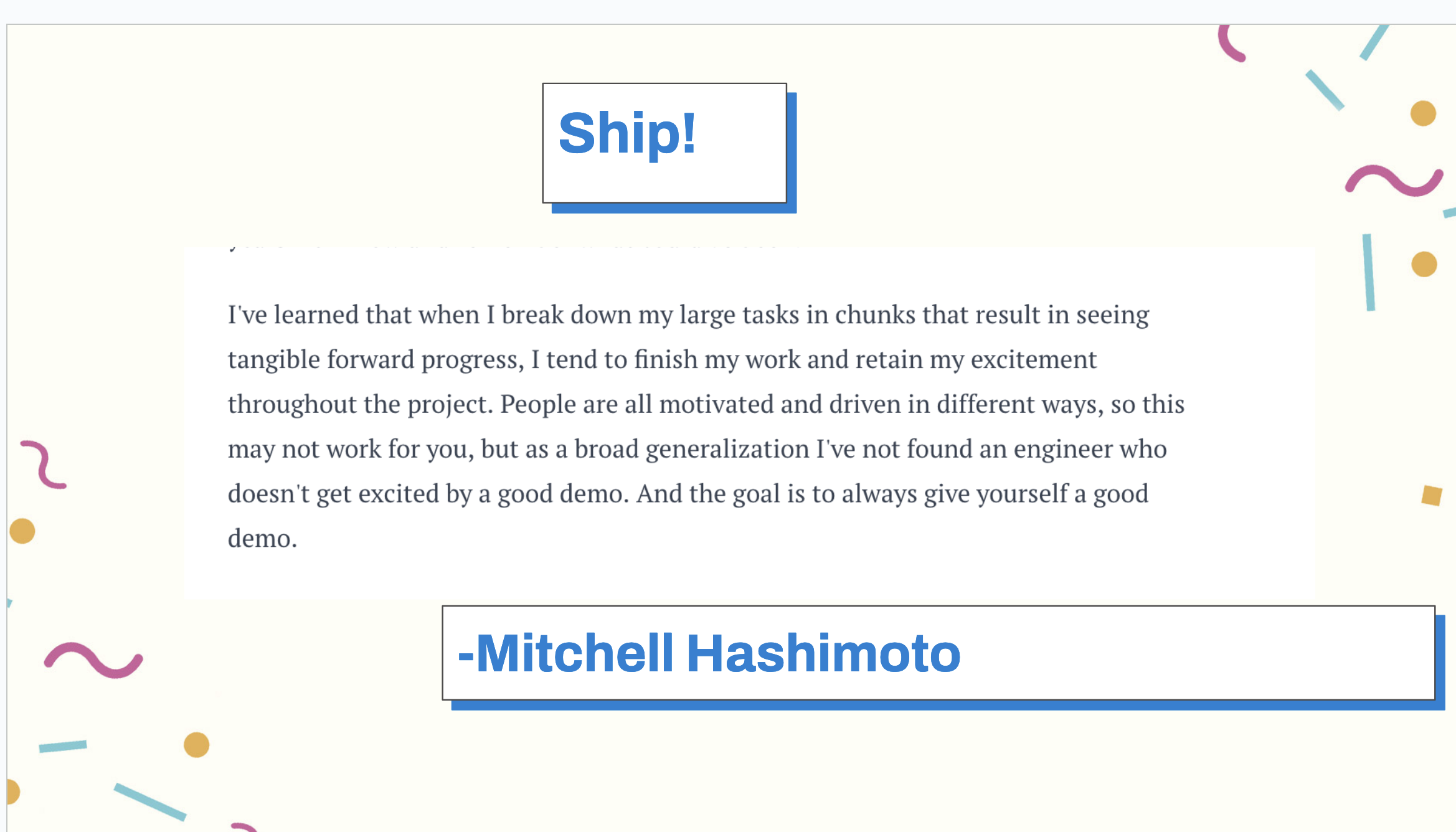
First, become a binary tree. What this means is reading broadly, then reading deeply. Be like Piranesi 2 and read the classics. We train better large language models by either adding more data or changing the architecture so that the attention mechanism captures more of the relationships in the data. We can do this for ourselves by reading broadly and deeply in our field. It’s hard to overestimate how much reading will do in helping anchor our contexts. This can be very hard to do and disheartening in the face of the enormous amount of literature, blog posts, and now social networks that propagate content about machine learning and its operations. When I first started reading, I stress-bought this enormous pile of books and hope I learn through osmosis.
But as soon as I finished one book, a new one came out. As soon as I read one paper, there was another one that beat SOTA. New frameworks rise and fall every day. Pip updates happen every day. It seemed like a never-ending uphill slog. One day, I stood looking at the pile of books and papers in dismay, and my husband, Dan, walked by, sipping his coffee. “I have to learn ALL of this,” I wailed. “It’s not so bad,” he said. “You know why? Because all of these books are not distinctly unique in their contents. For example, once you learn OOP in Python, you’re going to have a much easier time learning it in Java and now you can throw away half the book. And once you know Java, you’re already 60% of the way to Scala (except the weird monad-y parts, but don’t touch those). And so on.”

When I started thinking of learning as a process that involves going extremely wide on core fundamentals, then going deep and building links across fundamentals, it made the process a LOT more manageable.
What also helps here is not reading blog posts, but reading books, particularly books and papers, such as the Tapestry paper, now foundational, that have stood the test of time. Read papers that are ten years old with lots of citations, read blog posts that have been highly upvoted and shared over and over again.
Within those blog posts and papers, look for links to previous works. For example, just the other day I saw a paper that talked about transformers really being SVMs - support vector machines - which were models that were used heavily just before Word2Vec came into the picture. Learn these fundamentals and see how they link together. Learn foundational things, fill your context window with good breadcrumbs that will allow you to see the larger picture.

And, just as we should be reading books, we should be reading code. As engineers we spend most of our days reading rather than writing code and it’s a skill we can improve on. In any given library, click through the methods. Look at them. Write down the code. Go down the rabbit hole.

That’s what we’re here for at this conference! It’s so rare to get the ability to openly talk to other people about what they do at work. Do it here! Piranesi wandered through the hallways, unmoored, until he found other people to anchor his point of reference to. As he writes in his diary, “This experience led me to form a hypothesis: perhaps the wisdom of birds resides, not in the individual, but in the flock, the congregation.”

If you go to an interesting talk, and you see people gathering after the talk, discuss the talk. Ask questions, come up to people after the talk. Ask what other people are working on, what problems they’re having, what technologies they’re using. Presumably you’re here because you were looking to seek out the power of connection - do it!
Particularly in an era of social media fracture, in-person events are so important for doing this and for bringing knowledge back to our organizations.
Finally, build from fundamentals. Become close to the machine. Ellen Ullman writes, low is good. Understanding is good. The further away we get from abstractions and understand the code we’re writing, the better developers we become.

Whether that’s building a vector database out of np.vector or
coding your own algorithms from scratch like Sebastian does,

each of these moves concepts from your short-term to long-term memory and allows you to master your craft. The best engineers I know that do this well are constantly asking questions and learning, and, most importantly, taking things apart and digging deep into them to see how they work.
Finally, build with joy. Ship things!

Conclusion
When we look at any engineering system, we need to look hard, but find that it has still been created by people. We need to aggressively fight to build and keep our context windows. So, be Piranesi. Be Ellen Ullman. Be Phil Karlton. Be yourself and build out and hold on to your context windows. We need them.
Thank you and have an amazing conference. Enjoy Pydata Amsterdam!

Thank you to Chris Albon, Luca Belli, Dan Boykis, Roy Keyes, James Kirk, and Ravi Mody for reviewing drafts of this talk.
#machine learning #llms #talks #engineering #data science #learning