You can just hack on ATProto

Icon by iconixar
Since I signed up for Bluesky last year, I’ve been wanting to make something using the AT Protocol that the platform is built on top of.
I finally had a chance to do it over the holiday break and built GitFeed, a small Go app that filters the Bluesky network firehose by posts that have GitHub links and renders them into a refreshable, ephemeral feed.
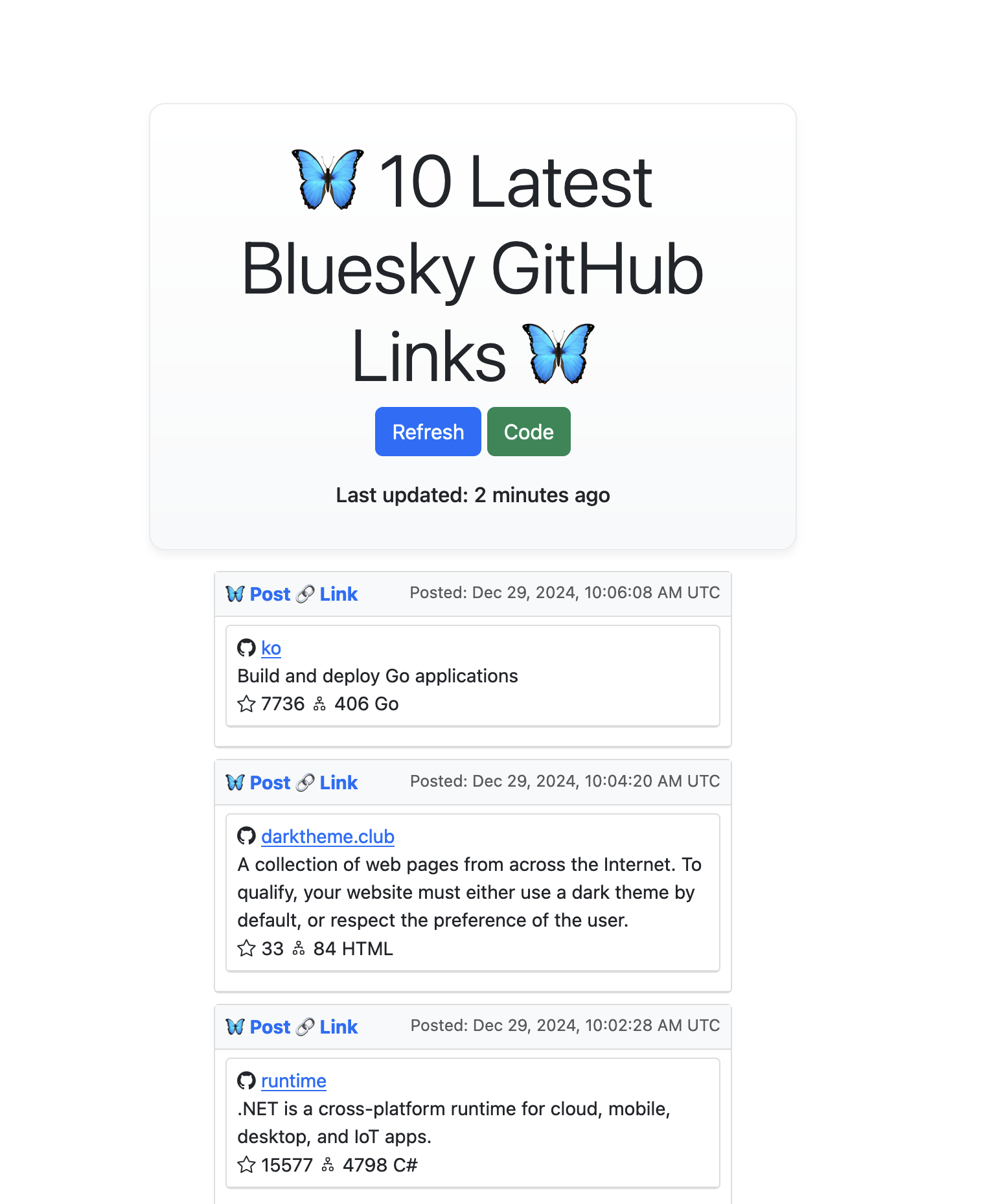
You can see GitFeed here, but it might not actually be running since I didn’t build it for scale, and it’s running on a tiny DigitalOcean Droplet that’s specced out at 1 GB Memory / 1 Intel vCPU / 35 GB Disk , is entirely unloadbalanced, un-load-tested and has zero observability or alerting when my very scientific process of running nohup fails.
The cool part of an open protocol is that you can also just clone the repo and run a hosted version of it yourself.
ATProto
Bluesky is both a decentralized protocol, called AtProto and a social media company, called Bluesky plc that develops both the protocol and one of the Apps running on the protocol, Bluesky.
There is a lot more in the AT Protocol Paper, but the basics are this:
Data for each user is hosted individually in a PDS - a personal data store - which is a database storing a collection of records that are cryptographically signed and encoded in DAG-CBOR format. The record schema is defined by a “lexicon”, which is dependent on the type of data being transferred. The records themselves are stored in a merkle search tree structure which makes it easy to rebalance records efficiently both on read and write. Its default storage engine is SQLite.
Each user has a PDS, exposed as a web service to network indexers. There is an indexer, the relay, which “scrapes” but really hits all the PDSes in the network for updates. Right now there is only one true relay, run by Bluesky the company, and there is a lot of debate around what that means for a decentralized network and efforts to diversify and decentralize. To better get a sense for how the data model works, you can play around with this tool, which is what I spent a lot of time doing during this project.
The TL; DR is that you can think of the At Proto Atmosphere as a collection of databases, or, really, websites, that the relay indexes and turns into the firehose. Data is then filtered on the firehose side for CSAM and other logic, before it’s turned into an AppView. The AppView is what you see if you sign into bsky.app.
If this sounds familiar, it’s because it’s how web crawlers, including Google work, with the exception that their crawled results are not available to everyone for access.
Steve has a very nice write-up of all of this, with a beautiful ascii diagram.
Al(most) all of the data streaming through each person’s PDS is public, and enables the creation of projects like the Bluesky firehose as a screensaver, or goodfeeds, surfacing feeds across the network., or TikTok and Instagram-like apps. As you can imagine, the protocol then lends itself to a lot of nice experimentation (make sure to check the TOS/Developer guidelines before you do so).
Let’s find all the gists
Initially, I wanted to create a custom feed on Bluesky. Generally, people create these by filtering the network to include all feeds about cats, or feeds from only mutual follows, or one of my recent favorites, gift articles, which includes links from gift articles that you can click through to read.
My idea was: collect all the posts that have a link to github gists, because people put really cool stuff in gists, so I could find and expose to other users some really cool code snippets of what people are hacking on around the platform.
Initially I thought I might be able to create a lightweight recommendation feed based on aggregate likes. Or, I could create a trending links feed. But, if you want to do any machine learning, you need to start consuming the firehose at scale, collecting the data, and setting up storage, and I wanted to learn Go, not implement distributed systems - don’t use N computers when you can use one.
Moreover, in order to implement a feed, generally, you need to also implement:
- pagination
- a cursor in case you lose your place in consuming the feed
- latency considerations
- Thinking about how you render feed objects (eventually they become large and need to be hydrated)
- potentially ranking that feed’s content
- retries and handling for if you skip feed elements
Additionally, specific to atproto, your feed is published at your own PDS - Personal Data Server, a LOT more about this here. You can see this at the link on the Gift Articles Feed:
https://bsky.app/profile/did:plc:o4s55v3tsfph6whswxccpsia/feed/aaaixbb5liqbu
Given that the feed is published and linked to your own data store, it made me hesitant to experiment in case I messed something up and lost all of my data.
There are lots of clients to create and publish feeds, but as a nerd, I didn’t want to have a third party handle this out of principle. Moreover, for gists only, there was not enough data to be interesting. The Bluesky network is growing, having surpassed 29 million users. But, at this scale, interesting content when you filter at this level of granularity is sparse.
After messing around with the (excellent) Python client a bit in this repo, I narrowed down to the problem I actually wanted to solve:
consuming all links with "github.com" in the link name, and consuming them via jetstream rather than the firehose.
That’s how GitFeed was born.
Why GitFeed? Why Go?
McFunley says you only have so many innovation tokens. This also applies to side projects. The other way I’ve seen this explained, is that you can either pick a new language, a new stack, a new business problem to solve, or new people to work with, but not all four at the same time, otherwise you will never ship.
I always want to get to a demo quickly. But, the goal of side projects is to do stuff you wouldn’t get to explore otherwise, so I chose to spend my innovation tokens on:
- learning a new backend language, Go: this thing had to serve code fast as a binary and have a very simple deployment story. I have a background in Java/Scala and initially thought about Java, but unfortunately there is no small light-weight Java server that I’m aware of (Spring doesn’t count) and Go has steadily been growing in popularity since its inception and especially after the language added features like generics and I wanted to check it out. Just as importantly, the backend of Bluesky and the protocol were specced out and written in Typescript and Go, and I thought it might be easier to navigate the Atmosphere in those languages.
- getting slightly better at front-end dev: I’d dabbled a bit with front-end design for Viberary but used almost no Javascript, which I’d need to render a feed.
- understanding the At Proto data model
I didn’t need to:
- Understand the problem of working with a feed of streamable content - I did a lot of feeds work when I worked on recommendations at Tumblr and I find it to be one of the most fun and satisfying problems in engineering to work on.
- Understand how to run/deploy on DigitalOcean using GitHub Actions - I already did this for Viberary and the path was pretty smooth
- Understand SQLite
- Finally, I wanted to track and catalogue my usage of LLMs for this project. I’m constantly evaluating their use-cases.
The Jetstream
I didn’t want to spend time implementing pagination, hydration, latency mitigation, and a data storage strategy. I wanted to get going quickly, so I decided to use the Jetstream. Jetstream is a relatively new content source for Bluesky content (relatively because everything is brand-new and being built on the fly.)
Working with the Bluesky firehose has a set of complications other than pagination: it also has its own data formats (CBOR and CAR for all the full merkle trees in the git repos) that take time in learning how to parse.
Moreover, the sheer volume of firehose events has grown to the point where folks consuming it need to invest heavily in scaling strategies for downstream application consumers.
Jetstream instead streams content in JSON, with reduced bandwidth and costs.
As a tradeoff, Jetstream is less stable, doesn’t contain content that needs API verification, and don’t offer pagination, activity offets, or uptime guarantees. As the docs say, it’s good for low-stakes side projects that don’t require heavy authentication or veracity, aka gitfeed.
Serving GitFeed
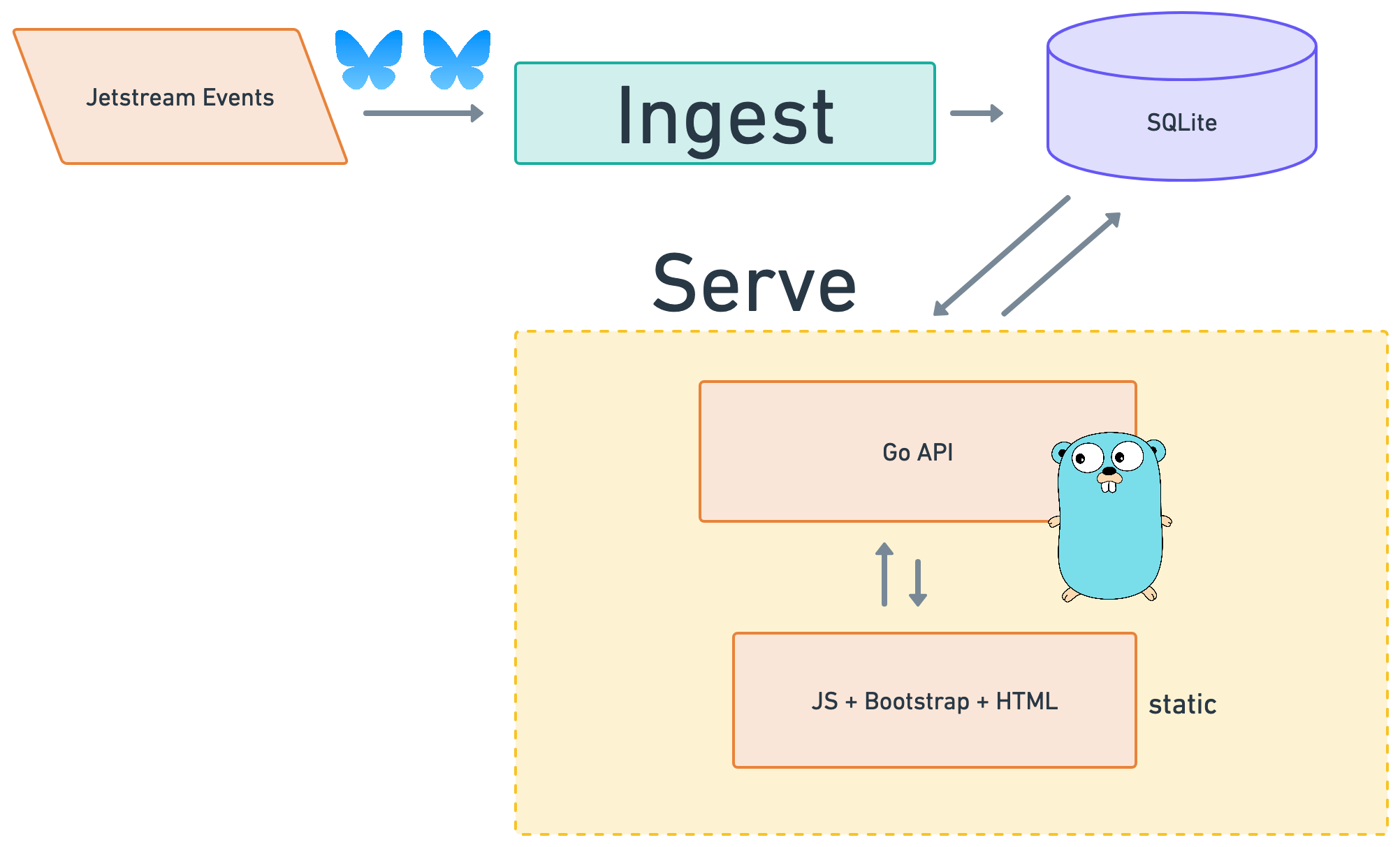
We’re building a simple web app with two components: that are two separate go processes:
- An
ingestgo module that will ingest posts and writes them to a SQLite DB that we instantiate as part of the application - A
servego module that serves the app via API.
The serving module is just a few Javascript files with static HTML pages. I was very overwhelmed by all the choices in the front-end ecosystem (although the developer docs helped a ton!), so I just ended up going with plain old Vanilla JS.
When we refresh the site, we make a call to the DB (via the posts API endpoint) to surface the posts in reverse chronological order.
export async function fetchPosts() {
const container = document.getElementById('postContainer');
container.innerHTML = '<div class="loading">Loading posts...</div>';
try {
console.log('Fetching new posts...');
const response = await fetch('/api/v1/posts');
if (!response.ok) {
throw new Error(`HTTP error! status: ${response.status}`);
}
const posts = await response.json();
container.innerHTML = '';
And here’s the actual call site:
import {
fetchPosts,
updateTimestamp
} from './feed.js';
console.log('Main.js loaded');
document.addEventListener('DOMContentLoaded', async () => {
console.log('DOM Content Loaded');
try {
await fetchPosts();
await updateTimestamp();
} catch (error) {
console.error('Error in main initialization:', error);
}
});
I was surprised at how much about JS was already familiar to me from Python and PHP, but where I really got stuck was in understanding how the DOM and Javascript work together, what a Javascript app structure looks like, and the Javascript ecosystem.
Using LLMs to build GitFeed:
I’ve done a lot of work with llamafile, and recently, I’ve also been enjoying the local LLM stack of: Ollama for the model backend and OpenWebUI for the front-end. Ollama serves versioned GGUF model weights wrapped in a Docker-like paradigm that hits an API wrapping llama.cpp in an (of course) Go interface. For this project, I used mistral:latest and qwen2.5-coder:latest , the best code model at the time (in the ancient space of 3 months ago, Deepseek3 wasn’t out). I did reasonably well between the two of them, with only 5% of requests that I had to bypass and send to Claude. I did find myself getting frustrated because I couldn’t clearly articulate the unknown unknowns I had about Javascript, though, and eventually I just gave up and bought Eloquent Javascript which I’m hoping to dig into this year to better understand what Qwen and I wrote together and how I can improve it.
Ingest
Consuming the Jetstream is easy. There are four public instances of Jetstream, hosted by Bluesky the company, so we need to connect to one of these, consume the content, process and filter the data, and save it to our database for serving.
You can check what’s up in the Jetstream with this nifty command line tool:
websocat wss://jetstream2.us-west.bsky.network/subscribe\?wantedCollections=app.bsky.feed.post | jq .
This is everything people are posting on Bluesky! (It sometimes gets very, very weird so be careful if you don’t want to look at NSWF texts.)
And now let’s look at GitHub posts. There aren’t a lot of them, so you might not get an even for at least a few minutes:
websocat wss://jetstream2.us-west.bsky.network/subscribe\?wantedCollections=app.bsky.feed.post | grep "github" | jq .
Jetstream is implemented as a websocket connection to the source.
wsManager := NewWebSocketManager(
"wss://jetstream2.us-west.bsky.network/subscribe?wantedCollections=app.bsky.feed.post",
pr,
)
A websocket is a protocol (like HTTP) that enables client-server communication over TCP but works best for streaming data without the need for continuous polling or webhooks (unlike HTTP).
A connection is instantiated with a handshake between the client and the server in HTTP first, and when the request is processed, both switch to websockets for communication.
I used the gorilla/websocket implementation of the websocket procool. for handling the core websocket logic.
We need to be able to read and write to/from the websocket:
The main thing to internalize about working with WebSockets in Go is that each client connection should get at least two goroutines: one that continuously processes messages coming from the client (i.e., a “read pump”), and one that continuously processes message going out to the client (i.e., a “write pump”).
However, this becomes easier since for GitFeed, we’re only reading from and not writing to the websocket, we need to implement logic to readPump
func (w *WebSocketManager) readPump(ctx context.Context) {
w.Connect(ctx)
counter := 0
for {
select {
case <-ctx.Done():
log.Printf("Exiting readPump: got kill signal\n")
return
default:
var post db.ATPost
if err := w.conn.ReadJSON(&post); err != nil {
w.Connect(ctx)
continue
}
counter++
if counter%100 == 0 {
log.Printf("Read %d posts\n", counter)
}
// Process the post
dbPost := ProcessPost(post)
if err := w.postRepo.WritePost(dbPost); err != nil {
w.errorHandler(fmt.Errorf("failed to write post: %v", err))
continue
}
log.Printf("Wrote Post %v", dbPost.Did)
}
}
}
However, unlike an HTTP call, websocksets are open persistently and don’t offer any guarantees of retries, so we have to implement this logic ourselves. Fortunately, gorilla has a lot of good examples.
You’ll notice a couple key points here: first, we log and handle the case where the web socket disconnects. Then, we do some ultra-fancy print logging to keep track of how many posts we’ve actually processed. And finally, we now get to the actual data, an var post db.ATPost that we process, parse, and write to the database, which we initialize as a post repository, a fancy word for “database with dependency injection”.
Golang tooling:
Go just works out of the box. Unlike my beloved Python, it doesn’t need uv, formatting, linting, or special build processes. At least, for a fairly small project, everything is batteries included. In fact, its boringness and rigidity allowed me to move really quickly. What surprised me is that I thought that VSCode would work really well with go, but actually didn’t as code I imported wouldn’t get loaded automatically, and there were a couple bugs that made me switch to Goland, which works extremely smoothly, without fail, and its local autocomplete at the line level is much better than PyCharm’s equivalent, likely because Go is much smaller, and statically-typed.
Jetbrains LLMs:
Jetbrains’ local LLMs are extremely well-done and I’d encourage anyone interested to check out the paper.
What is an AtProto Post
Now we get to the heart of the matter: once our websocket is open, we are ingesting a stream of JSON objects. AtProto has its own data model, defined using schemas called “Lexicons”. For posts and actions, they look like this.
{
"did": "did:plc:eabmaihciaxprqvxpfvl6flk",
"time_us": 1725911162329308,
"kind": "commit",
"commit": {
"rev": "3l3qo2vutsw2b",
"operation": "create",
"collection": "app.bsky.feed.like",
"rkey": "3l3qo2vuowo2b",
"record": {
"$type": "app.bsky.feed.like",
"createdAt": "2024-09-09T19:46:02.102Z",
"subject": {
"cid": "bafyreidc6abdkkbchcyg62v77wbhzvb2mvytlmsychqgwf2xojjtirmzj4",
"uri": "at://did:plc:ab7b35aakoll7hugkrjtf3xf/app.bsky.feed.post/3l3pte3p2e325"
}
},
"cid": "abfyreidwaivazkwu67xztlmuobx35hs2lnfh3kolmgfmucldvhd3sgzcqi"
}
}
The DID is the ID of the PDS (user repository) where the action happened, the record collection type of app.bsky.feed.post is what we care about, and each record has both a text entry, which truncates the text, and a facet, which has all the contained links and rich text elements in the post.
{
"did": "did:plc:",
"time_us": 1735494134541,
"type": "com",
"kind": "commit",
"commit": {
"rev": "",
"type": "c",
"operation": "create",
"collection": "app.bsky.feed.post",
"rkey": "",
"record": {
"$type": "app.bsky.feed.post",
"createdAt": "2024-12-29T17:42:14.541Z",
"embed": {
"$type": "app.bsky.embed.external",
"external": {
"description": "",
"thumb": {
"$type": "blob",
"ref": {
"$link": ""
},
"mimeType": "image/jpeg",
"size":
},
"title": "",
"uri": ""
}
},
"facets": [
{
"features": [
{
"$type": "app.bsky.richtext.facet#link",
"uri": ""
}
],
"index": {
"byteEnd": 85,
"byteStart": 54
}
}
],
"langs": [
"en"
],
"text": "..."
},
"cid": ""
}
}
So we parse these JSON objects and store them as Go structs. Go has a super handy tool where you can paste a JSON object and get back the Go struct.
And then we write that struct to a DB with a posts table that we’ve already instantiated for this purpose.
if err := w.postRepo.WritePost(dbPost); err != nil {
w.errorHandler(fmt.Errorf("failed to write post: %v", err))
continue
}
SQLite
Enough has been written about why SQLite is awesome and amazing for smaller, and even larger projects so I’ll skip that here and say that I didn’t even consider using anything else for GitFeed.
There are a ton of optimizations you can perform on SQlite to really juice performance, and I set a few of them in anticipation of many users hitting the server, and also easing read-write contention on the db.
Serving
After working extensively with FastAPI and Flask, I was really excited to learn just how batteries-included net/http module was in Go. I didn’t need to install anything extra - I was immediately writing routes and handlers.
We set up several routes to deal with our saved posts here.
// Start post service
fmt.Println("Connect to post service...")
pr := db.NewPostRepository(database)
postService := &handlers.PostService{PostRepository: pr}
// Create web routes
routes.CreateRoutes(postService)
log.Printf("Starting gitfeed server...")
log.Fatal(http.ListenAndServe(":80", nil))
And then we’re up and running as soon as we build and run our Go executable.
Building and Running Go Artifacts
So easy. Just a small Makefile and we’re rebuilding and testing, and then serving the binaries.
Data Considerations
I don’t want to keep any data or manage it, this is meant to be an ephemeral snapshot, so a goroutine deletes the oldest data once there are more than 10 posts in the database.
GitHub
One last piece we need, which early GitFeed testers suggested, was a way to, after you load the posts from the database, render the associated GitHub metadata with the repo, so we also, after we load the posts from the DB, hit the GitHUB API to enrich the post.
Ops Considerations
I run all of this on a small DigitalOcean droplet, and redeploy to the droplet with new code code merged to main via GitHub actions. There’s no monitoring or alerting, something I’d like to add for the future.
Final Reflections
This app was so much fun to develop and I learned an enormous amount of stuff. Small, self-contained apps are a joy, and especially when there’s a front-end component where you have a self-reinforcing feedback loop. Since us machine learning engineers work at what a friend called “the back-end of the backend”, we don’t often get to experience UI changes, and seeing through something end-to-end was a joy.
There were points of friction: It was definitely frustrating getting up and going with a whole new language and tech stack, but once I got back into the flow, it was great.
As always, the hardest part of this project, as with any project, was understanding the data model and the business logic, and parsing out those objects correctly. The second-hardest was aligning elements in CSS.
I’d love to get to a point where the app can surface Trending GitHub repos.. And maybe add some unit tests.
Upon writing this, I realized I have like three other posts I want to write about this process, so I’ll leave this as-is for now.
#golang #atproto #bluesky #web dev #engineering #database #social