My favorite use-case for AI is writing logs
One of my favorite AI dev products today is Full Line Code Completion in PyCharm (bundled with the IDE since late 2023). It’s extremely well-thought out, unintrusive, and makes me a more effective developer. Most importantly, it still keeps me mostly in control of my code. I’ve now used it in GoLand as well. I’ve been a happy JetBrains customer for a long time now, and it’s because they ship features like this.
I frequently work with code that involves sequential data processing, computations, and async API calls across multiple services. I also deal with a lot of precise vector operations in PyTorch that shape suffixes don’t always illuminate. So, print statement debugging and writing good logs has been a critical part of my workflows for years.
As Kerningan and Pike say in The Practice of Programming about preferring print to debugging,
…[W]e find stepping through a program less productive than thinking harder and adding output statements and self-checking code at critical places. Clicking over statements takes longer than scanning the output of judiciously-placed displays. It takes less time to decide where to put print statements than to single-step to the critical section of code, even assuming we know where that is.
One thing that is annoying about logging is that f-strings are great but become repetitive to write if you have to write them over and over, particularly if you’re formatting values or accessing elements of data frames, lists, and nested structures, and particularly if you have to scan your codebase to find those variables. Writing good logs is important but also breaks up a debugging flow.
from loguru import logger
logger.info(f'Adding a log for {your_variable} and {len(my_list)} and {df.head(0)}')
The amount of cognitive overhead in this deceptively simple log is several levels deep: you have to first stop to type logger.info (or is it logging.info? I use both loguru and logger depending on the codebase and end up always getting the two confused.) Then, the parentheses, the f-string itself, and then the variables in brackets. Now, was it your_variable or your_variable_with_edits from five lines up? And what’s the syntax for accessing a subset of df.head again?
With full-line-code completion, JetBrains’ model auto-infers the log completion from the surrounding text, with a limit of 384 characters. Inference starts by taking the file extension as input, combined with the filepath, and then the part of the code above the input cursor, so that all of the tokens in the file extension, plus path, plus code above the caret, fit. Everything is combined and sent to the model in the prompt.
The constrained output good enough most of the time that it speeds up my workflow a lot. An added bonus is that it often writes a much clearer log than I, a lazy human, would write, logs. Because they’re so concise, I often don’t even remove when I’m done debugging because they’re now valuable in prod.
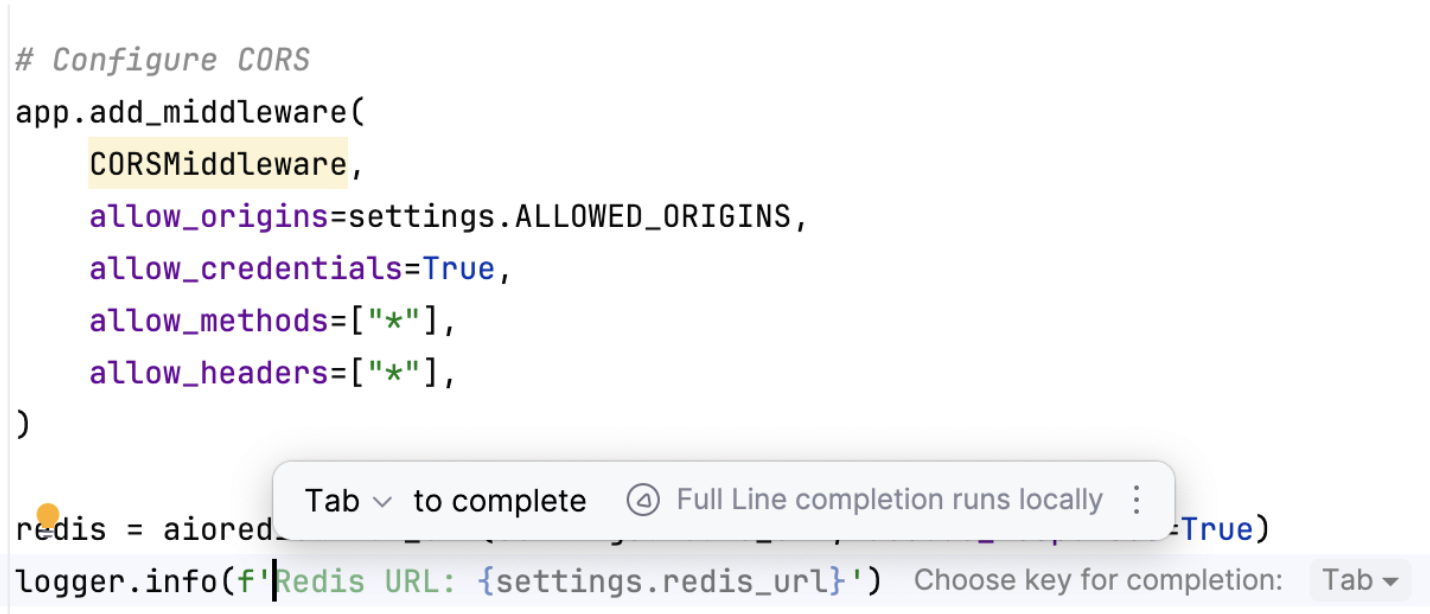
Here’s an example from a side project I’m working on. In the first case, the is autocomplete inferring that I actually want to check the Redis URL, a logical conclusion here.
redis = aioredis.from_url(settings.redis_url, decode_responses=True)
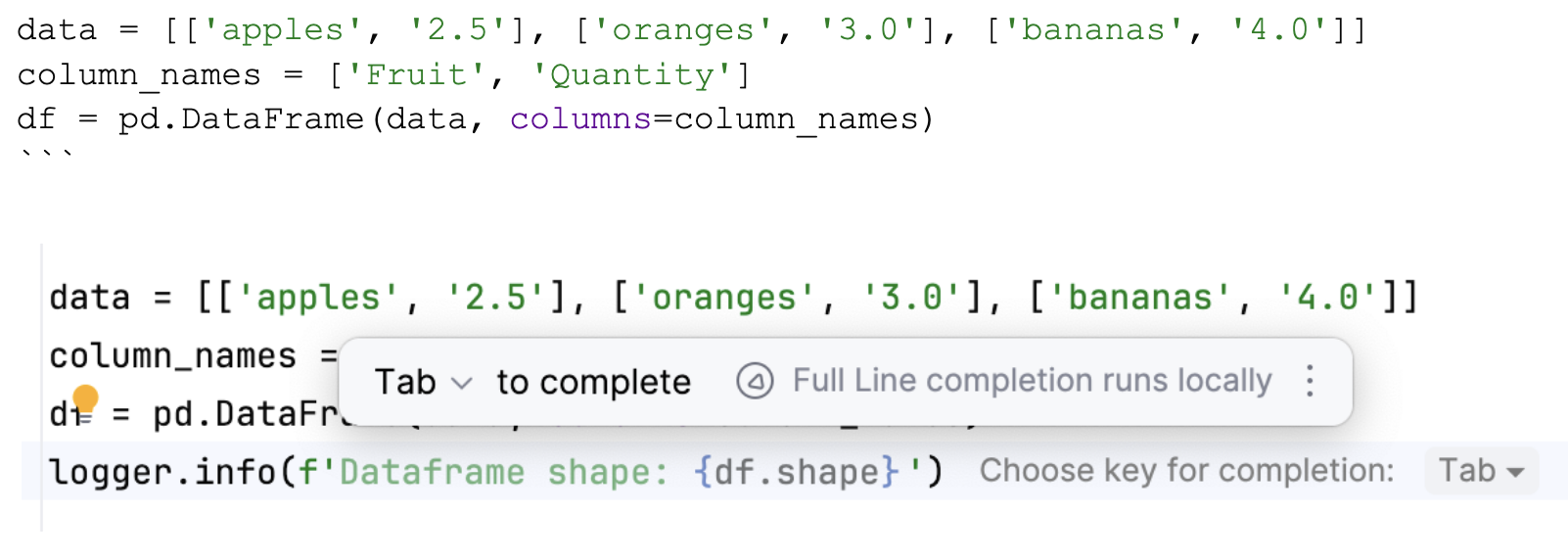
In this second case, it assumes I’d like the shape of the dataframe, also a logical conclusion because the profiling dataframes is a very popular use-case for logs.
from pandas import DataFrame
data = [['apples', '2.5'], ['oranges', '3.0'], ['bananas', '4.0']]
column_names = ['Fruit', 'Quantity']
df = pd.DataFrame(data, columns=column_names)
Implementation
The coolest part of this feature is that the inference model is entirely local to your machine.
This enforces a few very important requirements on the development team, namely compression and speed.
- The model has to be small enough to bundle with the IDE for desktop memory footprints (already coming in at around ~1GB for the MacOS binary), which eliminates 99% of current LLMs
- And yet, the model has to be smart enough to interpolate lines of code from its small context window
- The local requirement eliminates any model inference engines like vLLM, SGLM, or Ray which implement KV cache optimization like PagedAttention
- It has to be a model that’s fast enough to produce its first token (and all subsequent tokens) extremely quickly,
- Finally, it has to be optimized for Python specifically since this model is only available in PyCharm
This is drastically different from the current assumptions around how we build and ship LLMs: that they need to be extremely large, general-purpose models served over proprietary APIs. we We find ourselves in a very constrained solution space because we no longer have to do all this other stuff that generalized LLMs have to do: write poetry, reason through math problems, act as OCR, offer code canvas templating, write marketing emails, and generate Studio Ghibli memes.
All we have to do is train a model to complete a single line of code with a context of 384 characters! And then compress the crap out of that model so that it can fit on-device and perform inference.
So how did they do it? Luckily, JetBrains published a paper on this, and there are a bunch of interesting notes. The work is split into two parts, model training, and then the integration of the plugin itself.
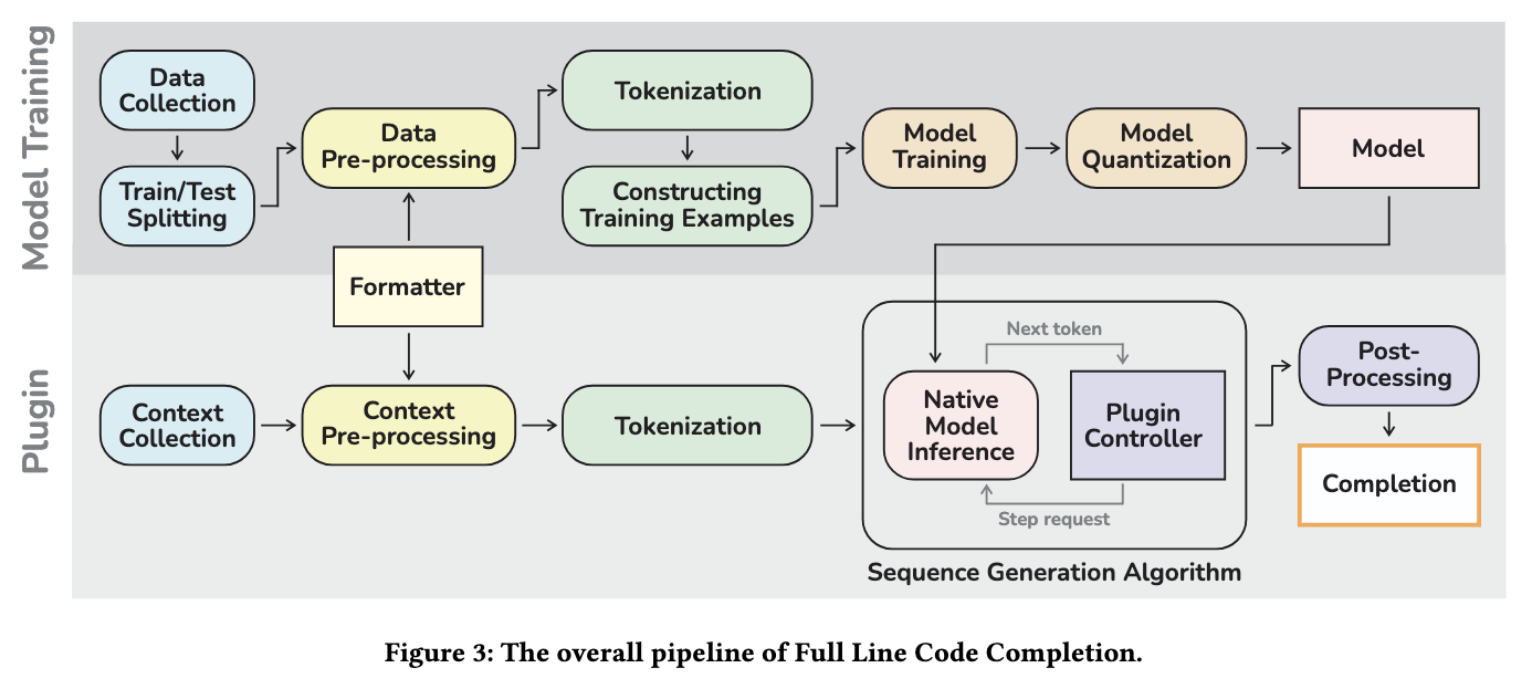
The model is trained is done in PyTorch and then quantized.
- First, they train a GPT-2 style Transformer decoder-only model of 100 million parameters, including a tokenizer (aka autoregressive text completion like you’d get from Claude, OpenAI, Gemini, and friends these days). They later changed this architecture to Llama2 after the success of the growing llama.cpp and GGUF community, as well as the better performance of the newer architecture.
- The original dataset they used to train the model was a subset of The Stack, a code dataset across permissive licenses with 6TB of code in 30 programming languages
- The initial training set was “just” 45 GB and in preparing the data for training, in data cleaning, for space constraints, they remove all code comments in the training data specifically to focus on code generation
- They do a neat trick for tokenizing Python (using a BPE-style tokenizer optimized for character pairs rather than bytes, since code is made up of smaller snippets and idioms than natural language text) which is indentation-sensitive, by converting spaces and tabs to start-end
<SCOPE_IN><SCOPE_OUT>tokens, to remove tokens that might be different only because they have different whitespacing. They ended up going with a tokenizer vocab size of 16,384. - They do another very cool step in training which is to remove imports because they find that developers usually add imports in after writing the actual code, a fact that the model needs to anticipate
- They then split into train/test for evaluation and trained for several days on 8 NVidia A100 GPU with a cross-entropy loss objective function
Because they were able to so clearly focus on the domain and understanding of how code inference works, focus on a single programming languages with its own nuances, they were able to make the training data set smaller, make the output more exact, and spend much less time and money training the model.
The actual plugin that’s included in PyCharm “is implemented in Kotlin, however, it utilizes an additional native server that is run locally and is implemented in C++” for serving the inference tokens.
In order to prepare the model for serving, they:
Quantized it from FP32 to INT8 which compressed the model from 400 MB to 100 MB
Prepared as a served ONNX RT artifact, which allowed them to use CPU inference, which removed the CUDA overhead tax(later, they switched to using llama.cpp to serve the llama model architecture for the server.
Finally, in order to perform inference on a sequence of tokens, they use beam search. Generally, Transformer-decoders are trained on predicting the next token in any given sequence so any individual step will give you a list of tokens along with their ranked probabilities (cementing my long-running theory that everything is a search problem).
Since this is computationally impossible at large numbers of tokens, a number of solutions exist to solve the problem of decoding optimally. Beam search creates a graph of all possible returned token sequences and expands at each node with the highest potential probability, limiting to
kpossible beams. In FLCC, the max number of beams, k, is 20, and they chose to limit generation to collect only those hypotheses that end with a newline character.Additionally they made use of a number of caching strategies, including initializing the model at 50% of total context - i.e. it starts by preloading ~192 characters of previous code, to give you space to either go back and edit old code, which now no longer has to be put into context, or to add new code, which is then added to the context. That way, if your cursor clicks on code you’ve already written, the model doesn’t need to re-infer.
There are a number of other very cool architecture and model decisions from the paper that are very worth reading and that show the level of care put into the input data, the modeling, and the inference architecture.
The bottom line is that, for me as a user, this experience is extremely thoughtful. It has saved me countless times both in print log debugging and in the logs I ship to prod.
In LLM land, there’s both a place for large, generalist models, and there’s a place for small models, and while much of the rest of the world writes about the former, I’m excited to also find more applications built with the latter.
#llms #machine learning #compression #tokenization #training #python #engineering #local models