Enabling Hugo static site search with Lunr.js
There comes a time in every woman’s life when she only wants one thing: for her mininmal static site to finally have some of the same features that dynamic blogging platforms do, namely search.
So now I’ve implemented search on this blog, you should see it in the top right and the results render in-line in the drop-down.

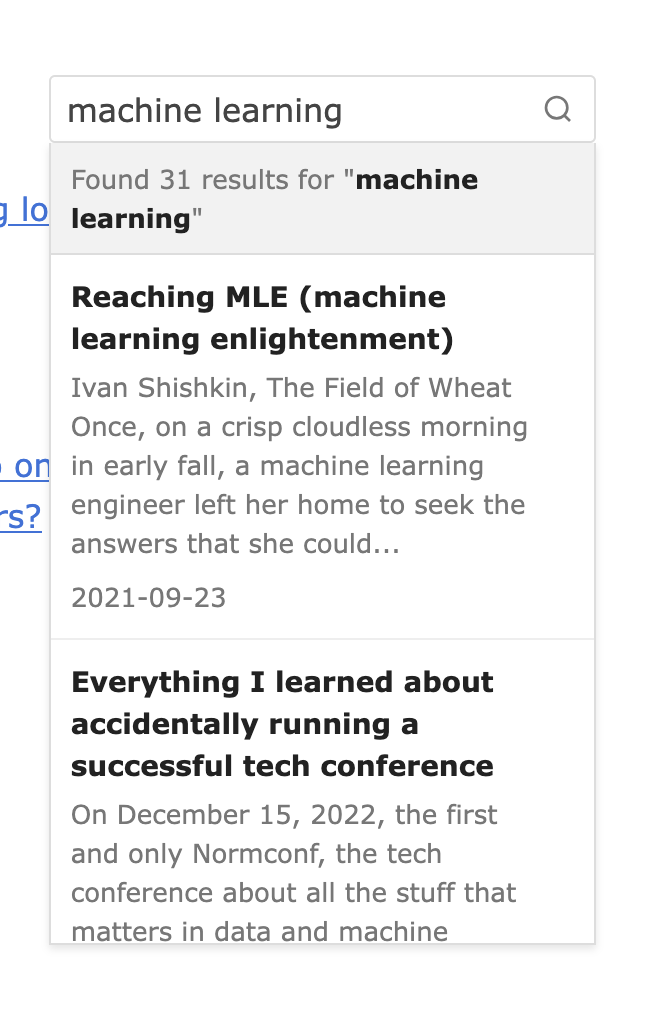
I’m going to tweak the results because the boosting is not quite where I’d like it to be yet, but try it out!
Some implmenetation details:
My blog runs on Hugo, so I looked for solutions that work with Jekyll/Hugo. I picked very fun and lightweight lunr.js, which is a single file that implements BM-25 search based on Solr primitives (it’s called Lunr because it’s smaller and “less bright” than Solr, which I love.)
To create the index that Lunr uses for search, I had Claude write a quick Python script that traverses my post directories and outputs a single JSON file of all indexes posts.
The entries look like this:
{
"id": "2018/07/23/good-small-datasets/",
"title": "Good small datasets",
"ref": "2018/07/23/good-small-datasets/",
"content": "John Lavery, The Chess Players (1929) I've been working on a project that, like most projects, requires testing with a dataset. My personal criteria are: + Relatively small size (Less than 100 KB, or 100ish rows) + At least 5-6 features (columns) + Should have both numerical and text-based features + Ideally a range of different kinds of numbers + Has good documentation + Is open and available to the public + Relatively available for both R and as individual CSV files or Python imports (APIs and",
"summary": "John Lavery, The Chess Players (1929) I've been working on a project that, like most projects, requires testing with a dataset. My personal criteria are: + Rela...",
"date": "2018-07-23T00:00:00Z",
"creator": "",
"site": "",
"url": "/blog/2018-07-23-small-datasets"
}
following this logic:
return {
'id': slug,
'title': frontmatter.get('title', 'Untitled'),
'ref': f"{slug}",
'content': text[:500],
'summary': text[:160] + '...' if len(text) > 160 else text,
'date': frontmatter.get('date', ''),
'creator': frontmatter.get('creator', ''),
'site': frontmatter.get('site', '')
}
I keep that code separate from my Hugo site, in a search directory that’s initialized as a uv project:
├── README.md
├── create_index.py
├── pyproject.toml
└── uv.lock
and generates the lunr.json index into my static repo.
This code is run at build time in my GitHub Actions before the hugo build step:
- name: Install uv
uses: astral-sh/setup-uv@v4
- name: Generate search index
run: |
echo "Generating search index..."
uv run search/create_index.py lunr-index.json
echo "Search index generated successfully"
Generating the script correctly took several passes because Claude missed some data cleaning nuances (I don’t want any HTML output, I wanted slightly longer summarization outputs, I didn’t want to include base pages, etc.), but now it regenerates the index in <5 sec every time.
Then, all of that is rendered in my navbar via Hugo templates, namely by including the logic to serve the search bar in the header partial. I’m abstracting away a ton of “draw the owl” features here, such as doing passes to make sure the CSS for the search bar matches my main blog theme, and rendering the dropdown results.
LLMs helped move this feature along a fair bit here because:
- It’s an extremely small feature where I can clearly test the output and see the generated code
- The context window for changes was fairly small
- The biggest lift was in automating index creation and getting the right syntax for the Python script and the data was easy to check.
- It has a tight local testing loop:
hugo buildandhugo serveare extremely fast locally and offer 95% parity to the served site in GH pages.
This has been a fun addition and I’m excited to do more such as potentially add typeahead suggestions and tune the query.