Tagging my blog posts with BERTopic and LLMs
I recently added tags to my blog using BERTopic and a mix of LLMs. You can see the tags in the sidebar to the right (or in the footer on mobile). I’ve done this before in 2023, with GGUF Mistral using llama-cpp, but never finished the project. Now, because the models have been getting so good, and my project was small, relatively well-defined, and easy to evaluate, the project took me about 6-10 hours over a month, using BERTopic, Claude Code, and Pi with Deepseek.
Why so many different AI tools? Mostly to evaluate their different ways of working. Much of that time was spent noodling on the UX experience of the tags rather than iterating on the tags themselves.
One of the genuinely useful use-cases of LLMs these days is for finishing personal projects that don’t touch production and have a small surface area that’s personalized for you. In other words, as Robin Sloan wrote, an app can be a home-cooked meal.
I love having a static site because of how easy it is to write and publish content and how fast it loads, but sometimes I wish it was slightly more fully-featured. LLMs have allowed me to add features like search. The theme I use, Hugo Bear Blog, already has support for tags, but I’d never added them to posts, and I also wanted a slightly different way to visualize them.
We consumers generally use LLMs for text or image or, if we’re developers, for code generation. But, one of the most underrated features of LLMs is the ability to compress rather than generate. This is really unsurprising: LLMs are, after all, natural language models.
Since they were trained and fine-tuned originally on language modeling tasks they also perform really well at all the tasks that language models are meant for, such as summarization, information retrieval, question answering. LLMs are really good at labelling things. That is, they’re good at topic modeling, the machine learning task behind tagging, especially in a zero-shot context (where they have no previous training data from you specifically).
What were tags?
In the early days of online blogging, tags were important for facilitating content discovery. People initially started tagging their blog posts on their individual blogs. Eventually, site aggregators like Delicious, surfaced top links with tags by aggregating tags across top links shared by users.
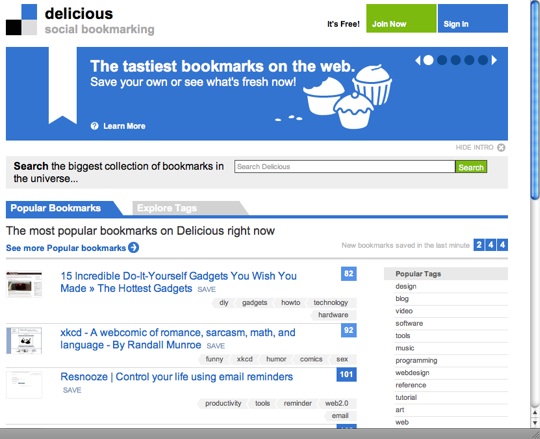
Pinboard was another prominent platform where finding content through tags and looking at aggregated tags was an important feature of the platform. Coincidentally, Delicious was later acquired by Pinboard.
Early on, the best way to find things that you liked was to manually participate in the curation of these folksonomies. Twitter and Tumblr developed some of the most creative folksonomic tagging systems. On Tumblr, tags became a way to not only discover posts, but to have conversations with other people about your post. On Twitter, hashtags became a way to signal communal discovery of people with shared interests before the implementation of Twitter’s SimClusters algorithm.
Tagging and hashtags served as an implicit contract of content discovery across platforms for over a decade, across Twitter, Instagram, TikTok, and many other services. However, big social has been in big decline for a while now. Group chats have arisen as a medium for exchange and discovery, as well as Discord groups that rely less on traditional tagging mechanisms. Bluesky, a social platform that was founded more recently, has the ability to add hashtags to posts, but most folks don’t do so. Discovery happens, like with many platforms today, through starter packs and custom algorithmic feeds.
The rise of LLMs led to an even greater decrease in the power of individual websites to add signal. An increase in AI overview features in search results that offer either summarization or RAG-assisted source synthesis has meant that visits to actual websites are dropping faster than ever. With LLMs, the rise of semantic and blended agentic-style search as a discovery mechanism means tags are not as important.
Within blogging, content surfaces like (oh God) LinkedIn native posts and X’s longform posts are contributing to platform-specific lock-in. All of our public blog content is being scraped as training data anyway, and agentic search and RAG mean people access content through an LLM’s interpretation of it rather than going directly to a page. RSS still exists, but who is going to syndicate a site when they could write an article on X or LinkedIn? (Me, sure.) You can subscribe to my feed!. Blog tags as a mechanism for understanding what my blog is about realistically still probably matter only to me. But I still want them!
Historical approaches to tagging with LDA
Generally, synthesizing and detecting topics across a body of text is an unsupervised learning machine learning problem. We don’t know ahead of time what the categories are. We have to infer them from the corpus.
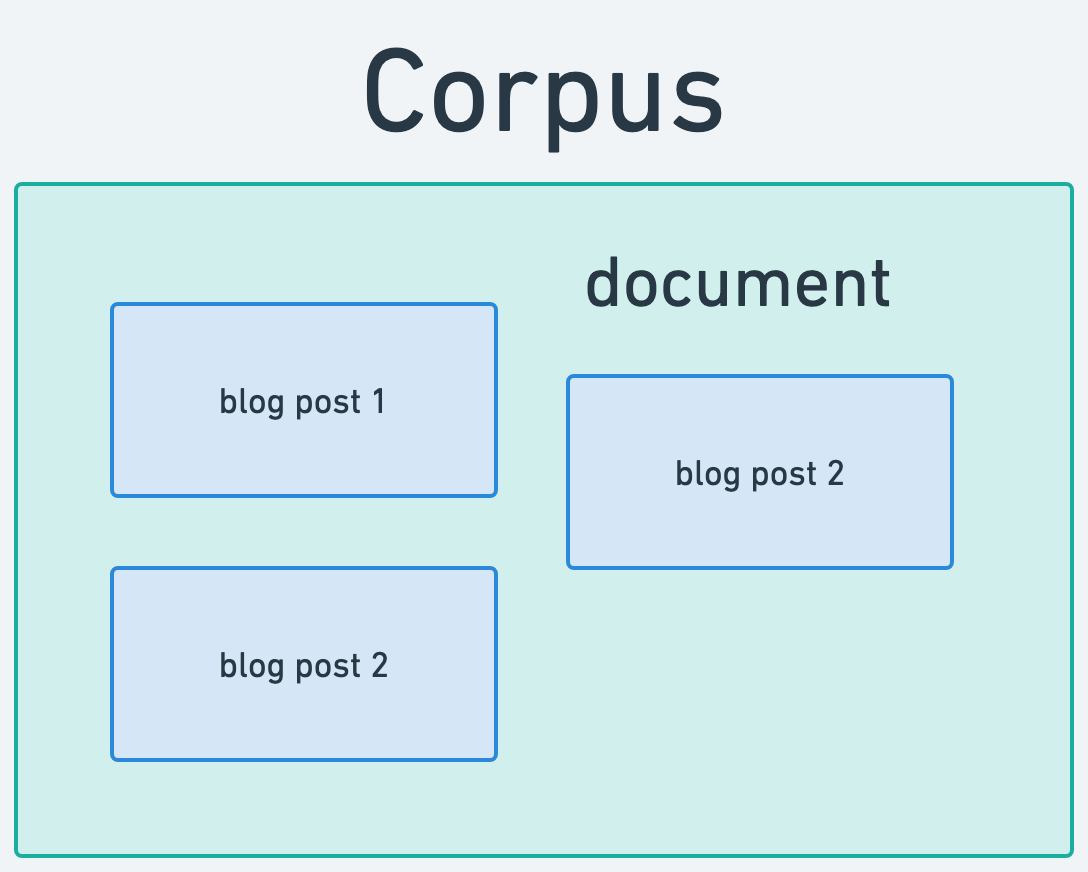
Traditionally, this was a really hard statistical problem in machine learning solved with approaches like latent dirichlet allocation (LDA). I really recommend Ted’s post if you’re interested in more of the core implementation details. The key idea is that, given a corpus of text documents, each document is modeled as a collection of topics. Each topic is a distribution over words, which means that each word in our corpus has a stated probability for being a member of a topic.
There were a number of unsolved problems with this approach, and with all statistical approaches. The biggest one was that the underlying assumption of topic modeling is that documents are bags of words. That is, words that are independent of each other. But, because words lose their context when they’re broken up from their constituent sentences (as we did when we created the tokenized input text for the model), the model wouldn’t recognize that the word “bank” in these two sentences, with “I went to the bank” and “The bank of the river overflowed with water” are different from one another.
One of the most trite and overused quotes in NLP is “You shall know a word by the company it keeps”, and this turned out to be one of the core successes of evolving neural approaches for language processing.
From embeddings to tagging with early LLMs in 2023
The evolving use of embeddings made it much easier to represent items that were semantically close together mathematically, by projecting into the same multi-dimensional vector space. The following generation of contextual embeddings calculated vectors based on the position or representation of the word, which eventually led to models that fully modeled the context - or the relationship of every word to every other word in a given text at the same time, creating weights of how relevant a word is to any other given word, aka the attention mechanism.
The first part of any topic modeling approach is picking your seed topics that the model can extrapolate from. You can do this in a number of ways: by bootstrapping from a couple of selected ones and creating more detailed ones, by picking plausible topics across your document set through tf-idf or LDA, by going through all the content and having an LLM zero-shot them.
Seeding topics with Mistral
This is what I tried to do the first time I tried to do this exercise. When local models like Mistral 7B-Instruct became available in 2023, I started playing around with them and realized that they did well at tagging. I decided I wanted to see if I could tag my blog with topics.
The first part was figuring out a set of tags from the given documents. I did some searching and found a paper called TopicGPT which was already exploring ways to use LLMs to do tasks that were previously done by BERT encoder models, and prior to that, latent dirichlet allocation.
I adapted the template in the paper with GGUF quants of Mistral 7B using llama-cpp-python (ancient history by now!).
Prompt templates were really important, less so than now, and the code looked like this:
system = f"""
You will receive a document and a set of top-level topics from a topic hierarchy.
Your task is to identify generalizable topics within the document that can act as top-level topics from the hierarchy.
Output the existing top-level topics as identified in the document. If the document has new topics,
suggest those.
{topics}
[Examples]
{examples}
[Instructions]
Step 1: Determine topics mentioned in the document.
- The topic labels must be as GENERALIZABLE as possible. They must not be document-specific.
- The topics must reflect a SINGLE topic instead of a combination of topics.
- The new topics must have a level number, a short general label, and a topic description.
- The topics must be broad enough to accommodate future subtopics.
Step 2: Perform ONE of the following operations:
1. If there are already duplicates or relevant topics in the hierarchy, output those topics and stop here.
2. If the document contains no topic, return "None".
3. Otherwise, add your topic as a top-level topic. Stop here and output the added topic(s). DO NOT add any additional levels.
Output:
existing_topics: ["Preprocessing", "LLMs"]
new_topics: ["Python"]
"""
Although both llama-cpp-python and the model worked well (for what was available at the time), I was constrained by a couple things:
A small context window - Mistral 7B GGUF had 32k tokens which meant that I had to make decisions about how to fit both my prompt and the longer documents entirely into the context window. Generally compacting to fit into a context window involves either cutting off text or creating a summary of your text and then summarizing that summary, neither of which are ideal when you’re looking for specific terms. You can see the token counting that has to happen in the process.
It was annoying to deal with reprompting the model to run in a loop for every document and keeping track of the results of those documents, especially as the smaller, local model ran out of memory.
Constraining guaranteed outputs for categories using a combination of the prompt and Outlines was finicky, even with the help of Outlines, which made it easier. Side note: Read the paper, it’s very cool.
I couldn’t decide on the proper method to create an initial pass at my first-level taxonomy topics and ended up doing it with this prompting approach, but still had to seed it manually, which didn’t create good categories. This problem isn’t specific to LLMs and is a known problem that’s discussed in the original topic paper, way back from 2005:
The underlying factor behind this variation may be that basic levels vary in specificity to the degree that such specificity makes a difference in the lives of the individual. A dog expert has not only the skill but also the need to differentiate beagles from poodles, for example. Like variation in expertise, variations in other social or cultural categories likely yield variations in basic levels.
For the purposes of tagging systems, however, conflicting basic levels can prove disastrous, as documents tagged perl and javascript may be too specific for some users, while a document tagged programming may be too general for others.
Tagging is fundamentally about sensemaking. Sensemaking is a process in which information is categorized and labeled and, critically, through which meaning emerges (Weick, Sutcliffe & Obstfeld forthcoming). Recall that “basic levels” are related to the way in which humans interact with the items at those levels (Tanaka & Taylor 1991); when one interacts with the outside world, one makes sense of the things one encounters by categorizing them and ascribing meaning to them. However, in practice, categories are often not well defined and their boundaries exhibit vagueness (Labov 1973). Items often lie between categories or equally well in multiple categories. The lines one ultimately draws for oneself reflect one’s own experiences, daily practices, needs and concerns.
Moving to LLMs + Agentic Harnesses in 2026
A couple of things have improved over the past several years that made me revisit the project.
- Model context windows, even for open models, have increased considerably over the past three years. Anywhere from 200k to a million tokens is considered a fair baseline for a given leading model, although it’s unclear how much of that context is actually used effectively.
- The emergence of agentic harnesses as a pattern for LLM access - hi Pi, the one I prefer to use! - into the frothy pot of LLM land means that you can now not only use models to tag individual documents, but also make your harness and underlying model clean up an entire site for less than 10 bucks, depending on the size of your blog and with much less manual wrangling of files.
- As more LLM systems come online, it’s become increasingly clear that the most effective LLM systems are ones that incorporate blended approaches to machine learning. That is, they are composed partly of generative parts where they make sense, and classical deep learning or tabular approaches where these make sense. I blended older transformer models with newer approaches, and this ended up working really well.
So, we can simplify the work with LLMs by just starting to cluster with BERTopic.
Using BERTopic
BERTopic is pretty great and free in terms of cost (though not compute), so I decided to start there.
BERTopic accepts a given set of documents. For our purposes, each of my blog posts is a document. For each document, BERTopic creates an embedding of 384 dimensions. Then, BERTopic performs dimensionality reduction using UMAP, which preserves locality, to reduce the embeddings into 5-10 dimensions, but in dimensions that still make sense relative to each other.
Then, it uses HDBSCAN to actually cluster the points together. Then, it produces a bag-of-words representation from the clusters, similar to what we produced with LDA, which combines all the documents in a given cluster into a single document, and counts frequency per cluster. Finally, the algorithm performs tf-idf on the words in a cluster per topic.
Throughout the process, we are constantly performing compression. But, unlike LDA, which has to re-assign every word in the corpus across many iterations, BERTopic compresses at the document level. With BERTopic, we generate one embedding per document, then cluster those, which speeds up computation quite a bit.
It’s very elegant and extremely fast on (even) a Mac M2 since it uses a lightweight sentence-transformers model, and my blog’s document base is not that big: 176k words.
printf 'Lines: %d\nWords: %d\nBytes: %d\n' \
$(wc -l -w -c bertopic_input.txt | tr -s ' ')
Lines: 4115
Words: 176282
Bytes: 1063606
The “context window” (really, max_seq_length) for all-mini-lm is 256 tokens, which means that I could break my posts down into, essentially, paragraphs, and have each paragraph be an individual document so that I didn’t need to summarize or fold into a context window.
I fed that into BERTopic and got an initial first pass at the topics.
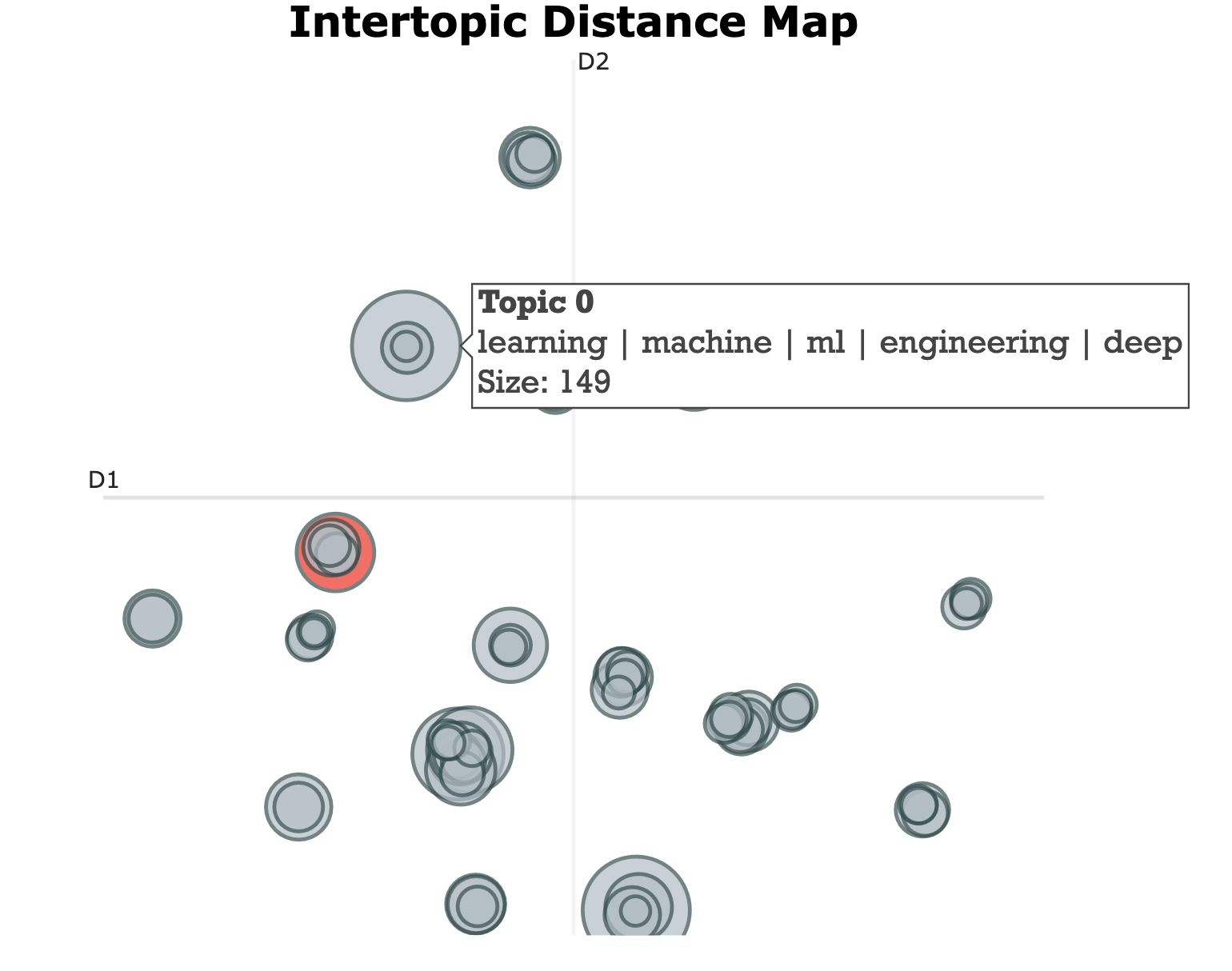
Refining the topics
The thing about clustering algorithms is that they will cluster things into groups, but won’t label the groups. For example, here are some of the clusters that BERTopic produced.

You can see that the attempted titles loosely fit with the tags, but that it would be better for the “software” cluster to come up with something slightly better. Software is a really generic tag in and of itself - my whole blog is about software.
So, what concretely do I want to say about software? I like to talk about best practices, things we should aspire to. A better word for that might be craft? But it’s not just any craft, it’s software craft.
As the Delicious paper alludes to, it takes a while to get to a good tag, because you’re creating a contract not only for yourself, but what you think your audience understands to be true. This was so important that many early taxonomy systems had experts: aka librarians! That created the first taxonomies. Clay Shirky wrote about just how hard this can be, particularly when you are creating a taxonomy in a digital space that has no boundary constraints.
This was such a complex problem that companies like Tumblr, for example, had a meme librarian that explicitly spent time cataloging and thinking about trends specifically on the platform.
Since these particular blog tags are just mine, I can formulate them however I want. Once I got the original output from BERTopic, I created a list. I then spent a bit of time in the Gemini chatbot window tuning them. Why Gemini? I’d already used it to write a small script cleaning up my markdown posts into documents, but Claude or ChatGPT would have done a similar job.
For example, here’s some iteration I did to get to the “shipping” tag, which you’d think would be extremely easy, but it turns out was actually hard to get to. When people talk about “taste” with relation to LLMs, this is what I think they mean - it takes time to get it to generate something that is like something you yourself would generate, versus what it (or the average of the internet) thinks.
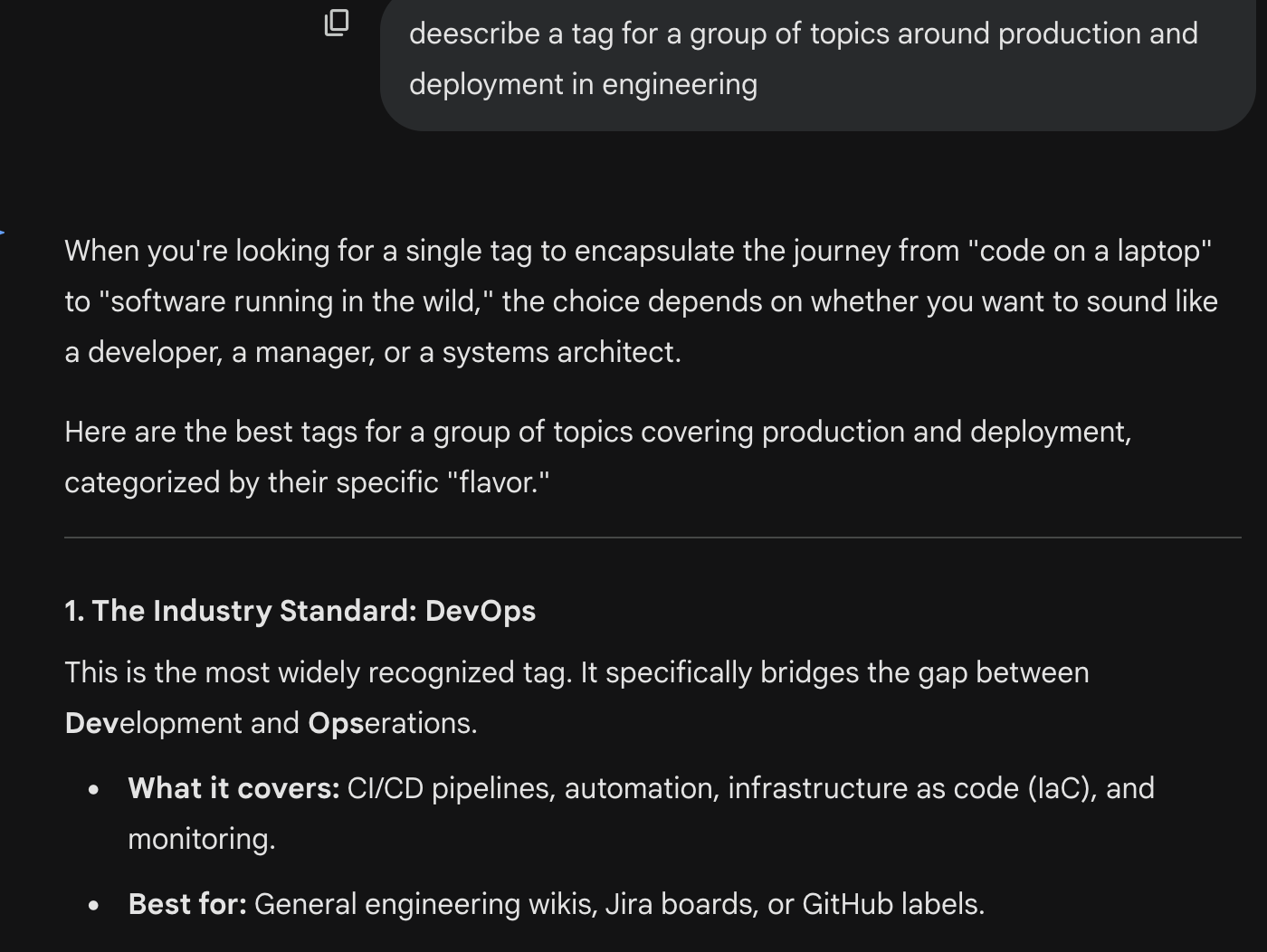
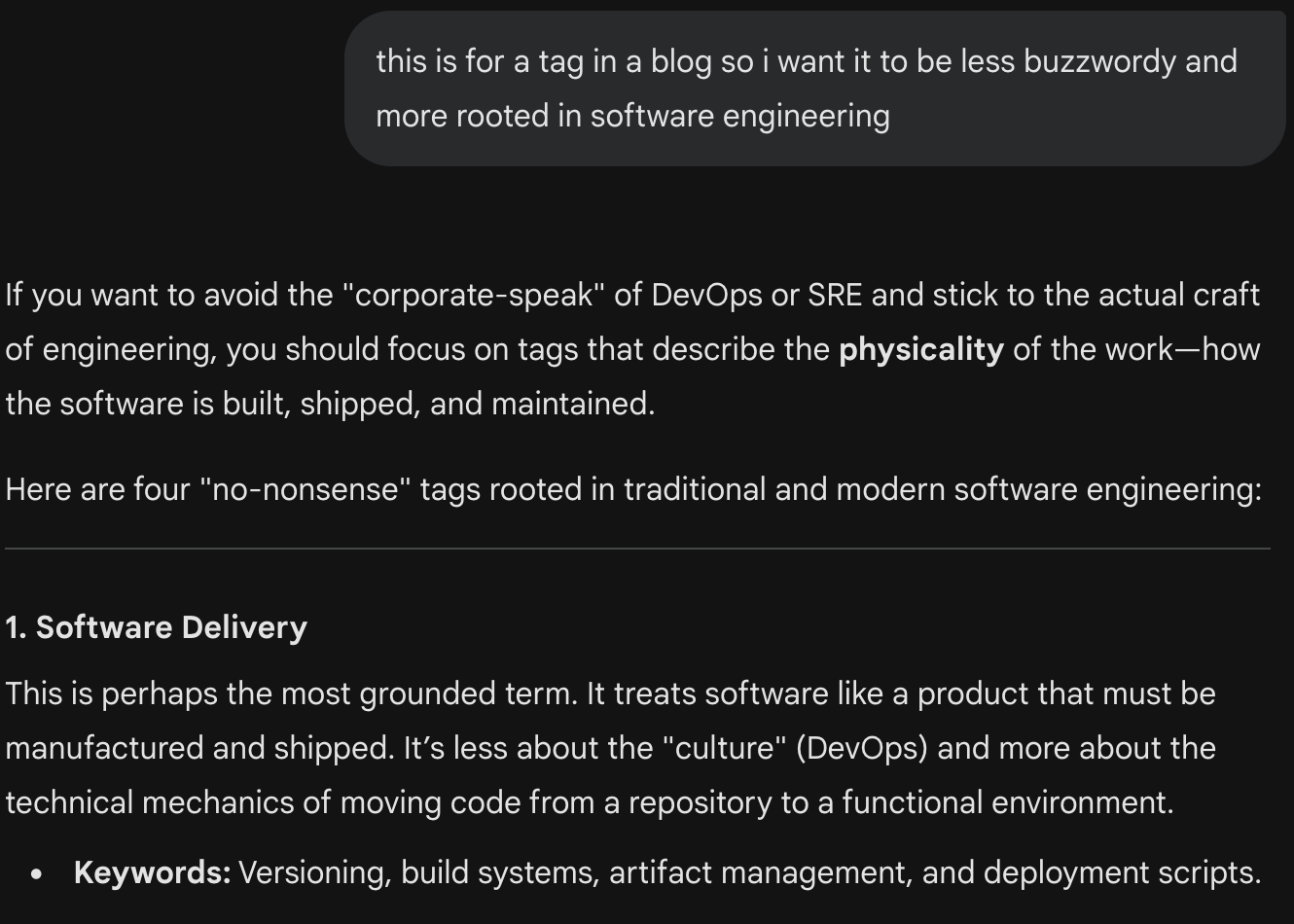
I then decided to get some more help from GPT-OSS running locally on LM Studio in thinking about what, if any, other top-level categories I should have, and refining the final list.
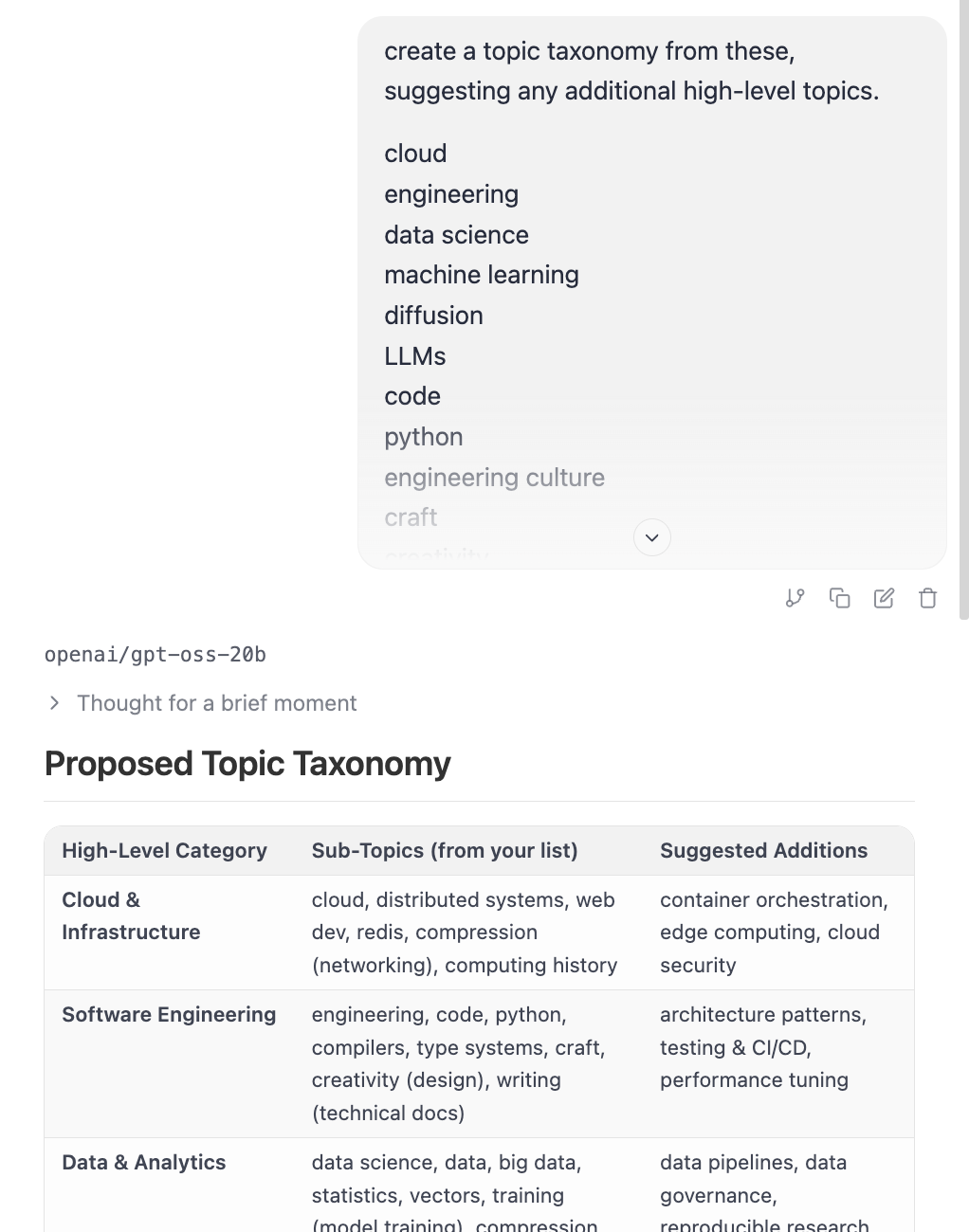
Now, I had a taxonomy, and I was ready to classify.
Batch-tagging with Claude Code

I took the initial list of topics and spun up Claude Code in my blog repo. I asked it to go through all the posts that I had, in batches, and tag them, using this prompt:
selecting from this list of tags, go through all the posts in the `blog` repo and select the appropriate tags based on the content of the posts. If no tags fit, skip. do not suggest related tags. Select between 5-7 appropriate tags for each post. Start with the latest post and work backwards chronologically.
cloud
engineering
data science
embeddings
machine learning
collaboration
diffusion
LLMs
.... [other tags from my list, up to 30 or so]
Claude worked for about 7 minutes, and the result was that each post had tags.
I then went through manually and made some adjustments as necessary. For example, one of the tags I’d jokingly added was “leading thoughts”, but when I saw it in a list of serious tags, it didn’t make sense and I didn’t feel it was helpful, so I took it out.
I had an end-result, which I put at the bottom of the page, and sat with it for a few weeks.

Generating the UI with Pi
I had my tags, but I was unsatisfied both with the amount of tags (too many, too many mixed levels) and with how things looked, because they were too cluttered. In my first pass, I added some more fine-grained categories like “Java”, which I ended up removing, because it became too cluttered.
It was around this time that Claude Code started having reliability issues that were partially obscured from users. After doing some research, I switched to Pi as my harness for a number of reasons, but mostly after watching this incredible talk by Mario. The engineering philosophy he describes really resonates with how I think about these tools, and software in general. That is, they should be introspectable, small, and light, plug and play, and open source.
I switched to Pi and have since tried out a number of models, including the latest from Gemini, OpenAI, and DeepSeek 4. Many of the models are largely interchangeable for this task with slight differences in personality, and I’m also excited to try hooking up Pi to Gemma 4 to see if I can get the same quality of local inference.
The UX piece took just as much, or even more, than the machine learning. Initially I represented the tags in the bottom bar, but decided to move them to the side for discoverability. Another issue was that initially, I had too many tags and collapsed them in the design.
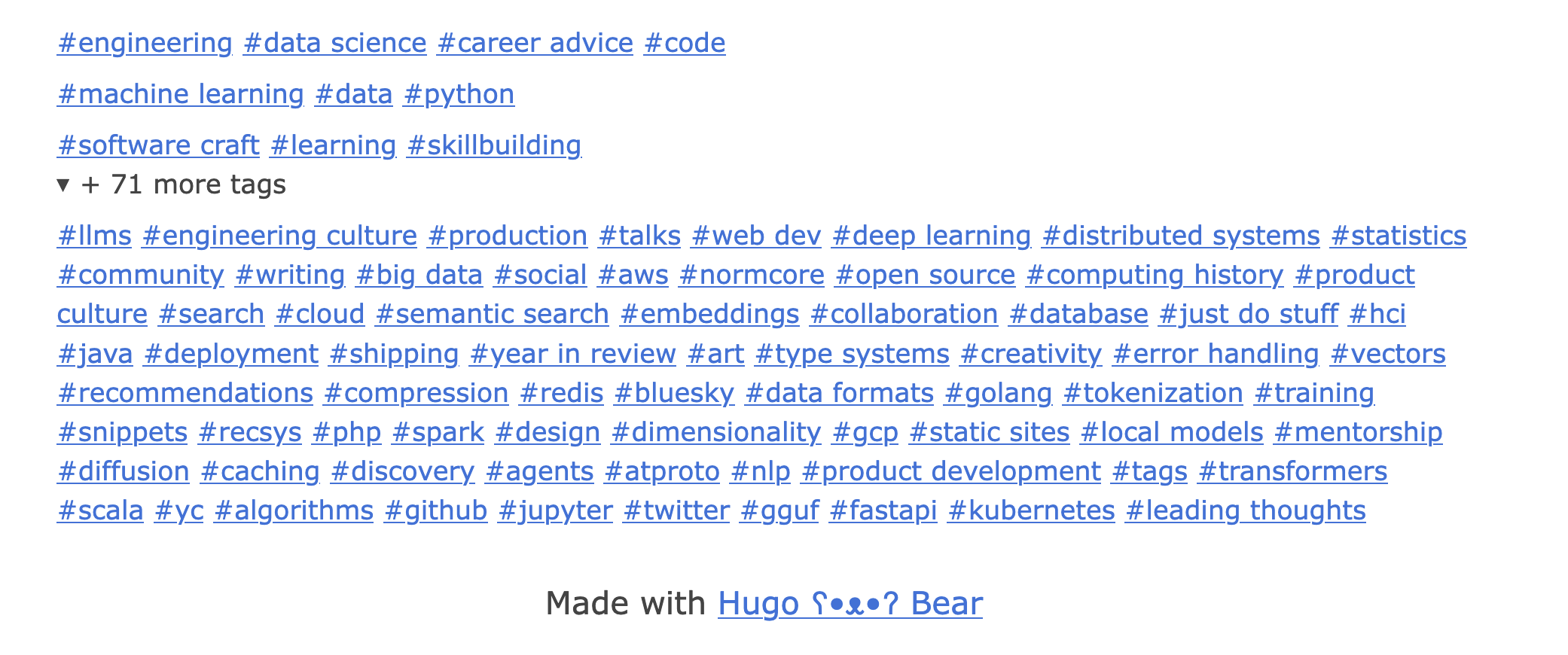
In a second pass, I reduced the number of tags, but the collapsible menu still wasn’t exactly what I wanted.

After moving the tags to the sidebar, I did a bunch of front-end wrangling with Pi using a number of different models to both reduce the number of tags and get them in the correct format on the sidebar, which led to the results you see now.
Final thoughts
It only took me 6-10 hours (over the course of a month) to complete this project, but it truly is incredible how much work LLMs, as they are accessed via a harness in 2026, compressed for me. Outside of how great Pi is generally, most of the models and harnesses these days feel fairly interchangeable, but still allow a lot of productivity for general development tasks that are 1. small, 2. well-scoped, 3. within the developer’s area of expertise so they can assess it.
It’s worth noting that using pre-LLM transformer BERT models did a fair amount of the heavy lifting here, and they did it better and cheaper than LLMs did. I suspect as more vendors raise per-token prices and gate unlimited plans, people encountering rising token costs will at least partly come back to blending LLMs with traditional ML approaches.
Other than that, it was just much easier to work with models in a harness like Claude Code and Pi than the previous TopicGPT-style approach.
I am currently happy with the results. The posts were tagged fairly correctly, I was able to get to a finished result, and I’ve used the tags a few times afterwards.
Will the remaining seven real people on the internet find it helpful? Guess we’ll see!
#machine learning #recsys #search #deep learning #embeddings #llms